آشنایی با Googlebot: قسمت اول

آشنایی با Googlebot یکی از مباحث مهمی است که تمام وبمستران (توسعه دهندگان، مدیران وب سایت و ...) باید از آن اطلاع داشته باشند. در این مقاله می خواهیم در رابطه با همین موضوع صحبت کنیم.
Googlebot چیست؟
یک webcrawler (در فارسی بعضا با عنوان «خزنده ی وب» به آن اشاره می شود) است. webcrawler ها در واقع ربات هایی هستند که شبانه روز و به طور سیستماتیک و برنامه ریزی شده در فضای وب گشت و گذار می کنند و اکثرا برای index کردن صفحات وب از آن ها استفاده می شود. index در لغت به معنی فهرست است. برای واضح شدن مطلب یک کتاب را تصور کنید؛ هر کتابی قسمتی به نام فهرست (index) دارد و این فهرست برای هر مبحثی، عددی ارائه می کند که همان شماره ی صفحه است. index کردن صفحات وب نیز به معنی فهرست کردن آن ها در موتورهای جست و جو است. زمانی که شما در گوگل مطلبی را سرچ می کنید با فهرستی از URL ها (صفحات مختلف وب) مواجه می شوید که قبلا توسط یک webcrawler ایندکس (یا صفحه بندی) شده اند.
به زبان ساده تر می توان گفت webcrawler ها نرم افزار هایی هستند که برای دنبال کردن لینک ها، جمع آوری اطلاعات و فرستادن اطلاعات به مکانی مشخص طراحی شده اند. برای اطلاعات بیشتر در مورد webcrawler می توانید به مقاله ی ویکی پدیای آن مراجعه کنید.
نکته: موتور جست و جویی با نام WebCrawler وجود دارد که به گفته ی بسیاری، قدیمی ترین موتور جست و جوی دنیا است. نام این وب سایت را با مبحث امروز ما اشتباه نگیرید.
بنابراین Googlebot در اصل یک webcrawler است که توسط گوگل ساخته شده است و گوگل نامش را Googlebot گذاشته است. اطلاعاتی که Googlebot به گوگل تحویل می دهد برای بروزرسانی ایندکس صفحات در گوگل استفاده می شود. این ربات از میلیاردها صفحه ی وب در سراسر جهان بازدید می کند.
وظیفه ی Googlebot چیست؟

گوگل بات اطلاعات موجود در صفحات را دریافت کرده (یعنی کلمات موجود در صفحه، سورس کد، منابع تشکیل دهنده ی صفحه مانند عکس و فیلم و ...) و اگر محتوای سایت لینکی داشته باشد، آن را به خاطر می سپارد. سپس اطلاعات جمع آوری شده را به گوگل ارسال می کند.
رابطه ی Googlebot و وب سایت شما
همانطور که گفتیم اطلاعاتی که Googlebot به کامپیوترهای گوگل ارسال می کند، ایندکس (صفحه بندی) گوگل را بروزرسانی می کند. به طور فنی تر می توان گفت ایندکس گوگل جایی است که صفحات وب مقایسه و رتبه بندی می شوند. اما دو نکته باقی می ماند:
- اگر می خواهید صفحات وب شما در گوگل قابل پیدا شدن باشند، باید برای گوگل بات قابل دسترسی باشند.
- اگر می خواهید صفحات وب شما در گوگل به رتبه ی خوبی برسند، تمام منابع وب سایت شما باید در دسترس Googlebot باشد.
اما چطور؟ در ادامه برای شما توضیح خواهیم داد.
تفاوت Googlebot با Google index
ممکن است تا این جای کار از خودتان بپرسید با این تفاسیر تفاوت بین Googlebot و Google Index چیست؟ قبلا گفتیم که Googlebot تنها اطلاعات را دریافت می کند بنابراین به هیچ عنوان توانایی بررسی، رتبه دهی و تفاوت قائل شدن بین صفحات را ندارد. تنها سوالاتی که گوگل بات از خود می پرسد عبارت اند از:
- آیا می توانم به محتوای این صفحه دسترسی داشته باشم؟ به صورت جزئی یا به صورت کامل؟
- آیا محتوای بیشتری در آینده نیز وجود دارد که بتوانم به آن دسترسی پیدا کنم؟
این در حالی است که Google Index اطلاعات را از گوگل بات دریافت می کند و سپس داده ها را تحلیل کرده و صفحات را رتبه بندی می کند.
بنابراین واضح است که اگر گوگل بات نتواند به وب سایت شما و محتوای آن دسترسی داشته باشد، وب سایت شما در نتایج گوگل به نمایش در نخواهد آمد.
سوال: اگر وب سایت های ما در نتایج گوگل وجود نداشته باشد، عملا سرور های ما خاک خواهند خورد! چرا چنین گزینه ای برای ما وجود دارد؟
پاسخ: در ادامه به صورت کامل به پاسخ این سوال خواهیم پرداخت اما فعلا به طور خلاصه میگویم که قرار نیست هست و نیست ما در نتایج گوگل باشد! بله اکثر وب سایت ها باید در گوگل نمایش داده شوند اما وب سایت های خصوصی چطور؟ برخی از شرکت های کوچک از وب سایت هایی استفاده می کنند که تنها مخصوص کارکنان آن شرکت است و معنی ندارد به صورت عمومی و برای همه به نمایش در بیاید. حالت بدتری را تجسم کنید؛ سرورهای سرویس های اطلاعاتی کشورهای مختلف مانند CIA و MI6 و ... نباید به هیچ عنوان در دسترس افرادی به غیر از افسران اطلاعاتی قرار بگیرند چه برسد به اینکه به صورت عمومی و در گوگل نمایش داده شوند!! در واقع دسته بندی جالبی در همین مورد موجود است که میخواهم آن را توضیح دهم...
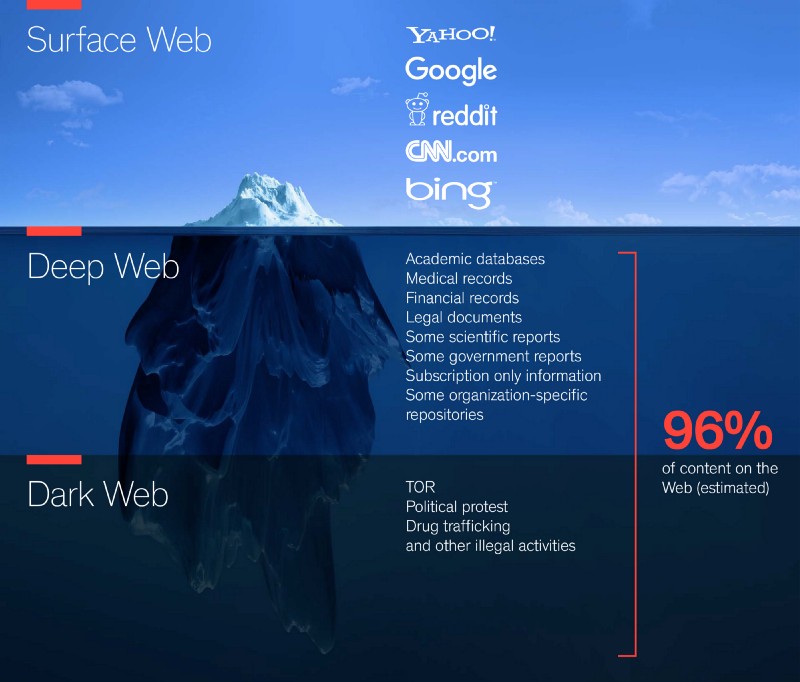
دسته بندی اطلاعات در دنیای وب
اطلاعات دنیای وب، از نظر دسترسی، معمولا به سه دسته تقسیم می شوند:
- Surface Web (دنیای سطحی وب): هر نوع اطلاعاتی که بتواند توسط موتورهای جست و جوی عادی مانند گوگل، یاهو، بینگ و ... ایندکس شود در این دسته قرار می گیرد. این قسمت، همان قسمتی است که همه ی ما روزانه با آن سر و کار داریم؛ مثل انواع وب سایت ها، شبکه های اجتماعی و ... . طی تحقیقاتی که توسط Nature انجام شد مشخص شد که گوگل تنها توانسته است 16 درصد از دنیای وب را (که همان Surface Web است) ایندکس کند. در تحقیقات دیگری ادعا شده است که این عدد تنها 4 درصد می باشد و 96 درصد از اینترنت مخفی است.
- Deep Web (دنیای عمیق وب): هر نوع اطلاعاتی که موتورهای جست و جو در پیدا کردن آن ناتوان هستند شامل این قسمت می شود. داستان های ترسناکی در این مورد دست به دست می شود و می گویند قاتل ها و فروشندگان مواد مخدر و انواع خطرها در Deep Web است! این داستان ها فقط برای سرگرمی مردم و یا به خاطر بی اطلاعی از واقعیت این فضا است. یک مثال از این فضا را به شما می گویم. به وب سایت Hotwire بروید و سعی کنید بدون استفاده از search box سایت (قسمت جست و جوی سایت) به قیمت رزرو اتاق در هتل Sioux Falls پی ببرید. خواهید فهمید که نمی توانید چرا که هیچ لینکی برای صفحه ی این هتل وجود ندارد و تنها راه رسیدن به آن سرچ کردن است. چرا گفتیم بدون استفاده از search box؟ به این دلیل که webcrawler ها نمی توانند از قسمت جست و جوی وب سایت ها استفاده کنند و تنها قادر به دسترسی به محتوای سایت از طریق لینک ها هستند. این یک مثال واقعی از Deep Web است.
- Dark Web (دنیای تاریک وب): اگر در دنیای وب همینطور جلوتر برویم به دنیای تاریک خواهیم رسید. این قسمت، قسمتی کوچک از Deep Web است که به صورت عمدی و با هدفی خاص مخفی شده است و شما نمی توانید با مرورگرهای عادی مانند گوگل کروم و یا فایرفاکس وارد این وب سایت ها شوید. مشهور ترین محتواهایی که در این قسمت موجود است در شبکه ی TOR وجود دارند و با مرورگر خاصی به نام TOR browser در دسترس خواهند بود. این قسمت از دنیای وب بیشتر مربوط به کارهای خلاف مانند قتل، آدم ربایی، فروش مواد مخدر، فروش اسلحه، فروش کالاهای سرقتی، شکنجه و به طور کلی کارهای غیر قانونی و غیراخلاقی است.
به طور مثال وب سایت معروف wikileaks که فاش کننده ی اطلاعات محرمانه ی دولت ها و سازمان های خصوصی است و یا اطلاعات دولت ها به طور کلی در قسمت Deep Web قرار می گیرد. یادتان باشد که Dark Web تنها قسمتی از Deep Web است.
تصویر زیر این بحث را به صورت خوبی نمایش می دهد:
اطمینان از شناخت سایت شما توسط گوگل
حالا چه کار کنیم که وب سایت ما حتما توسط گوگل شناخته شود؟ باید سه مسئله ی اصلی را رعایت کنید:
- آیا Googlebot میتواند وب سایت من و صفحات اش را ببیند؟
- آیا Googlebot میتواند به تمام محتوا و لینک های وب سایت من دسترسی داشته باشد؟
- آیا Googlebot میتواند به منابع وب سایت من دسترسی داشته باشد؟
در قسمت بعد در این مورد این سه مسئله مفصلا بحث خواهیم کرد.








در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.