فصل جدید؛ آشنایی با indexها در MongoDB
Familiarity with indexes in MongoDB
22 اردیبهشت 1401

به فصل جدید از سری آموزشی MongoDB خوش آمدید! در این فصل می خواهیم با مبحث بسیار مهمی به نام index ها آشنا شویم. اولین سوالی که برای همه تازه کاران پیش می آید این است که index چیست؟ index ها می توانند سرعت اجرای کوئری های UPDATE و DELETE و find را بالاتر ببرند؛ یعنی تمام کوئری هایی که در آن ها به دنبال اسناد مشخصی هستیم. به طور مثال به کوئری زیر توجه کنید:
db.products.find({seller: "Max"})
در کوئری بالا به دنبال محصولاتی (products) هستیم که فروشنده شان فردی به نام Max باشد. اگر ما روی seller خود index ای را نداشته باشیم، MongoDB با اجرای کوئری بالا عملیاتی به نام collection scan (اسکن کردن کالکشن) را انجام می دهد. در این عملیات MongoDB کل کالکشن را بررسی می کند و تک تک document ها را بررسی می کند تا ببیند در کدام document ها، فروشنده (seller) فردی به نام Max است. این همان حالت عادی کار با کالکشن ها است و احتمالا شما هم متوجه شده اید که اگر تعداد زیادی سند در کالکشن خود داشته باشیم (مثلا ده ها هزار سند) جست و جو در آن ها عملیات کُندی خواهد بود. در نهایت پس از بررسی تمام این هزاران سند، دو یا چند محصول مورد نظر را از آن کالکشن خارج می کند.
برای حل این مشکل می توانیم از index ها استفاده کنیم. index ها قابلیتی هستند که به collection ها اضافه می شوند بنابراین با ساخت آن ها به کالکشن خود چیزی اضافه کرده اید. اگر ما برای seller یک index تعریف کنیم، چه اتفاقی می افتد؟ index لیستی از تمام مقادیرِ seller در کل کالکشن ما است. توجه کنید که index لیستی از کل سند ها نیست بلکه لیستی از مقادیر (value) یک فیلد مشخص می باشد. این فیلد، همان فیلدی است که برایش index تعریف کرده اید که در مثال ما همان seller است. البته علاوه بر مقادیر آن فیلد، یک pointer نیز دارد که به محل آن سند در کالکشن ما اشاره می کند بنابراین حالا که index را تعریف کرده ایم دیگر نیازی به عملیات collection scan نیست، بلکه عملیاتی به نام index scan انجام می شود.
زمانی که برای seller یک index داشته باشیم و کوئری بالا را اجرا کنیم، MongoDB متوجه وجود این index می شود بنابراین مستقیما به سراغ آن index رفته و سریعا با استفاده از pointer موجود در آن به محل دقیق آن مقدار در کالکشن ما می رود و دیگر نیازی نیست کل کالکشن را اسکن کند. به تصویر زیر توجه کنید:
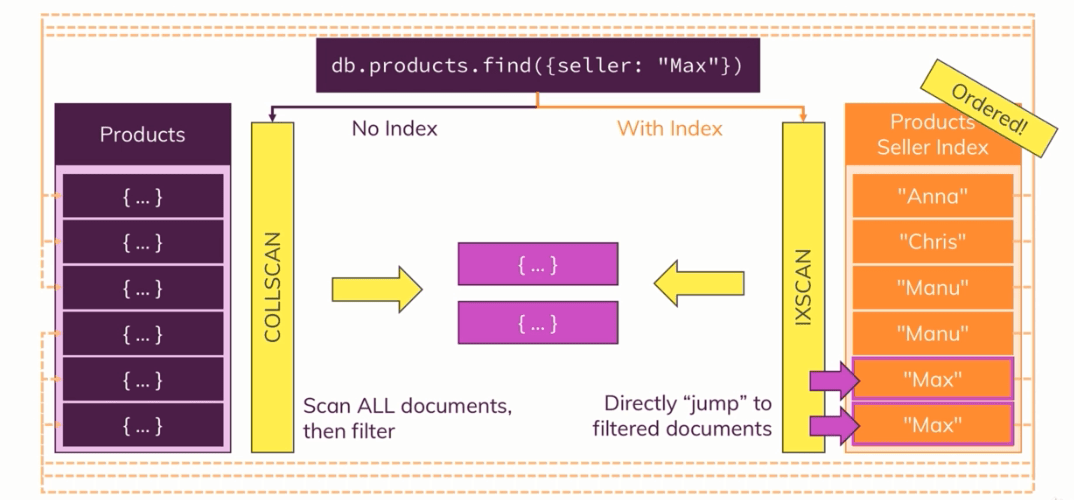
در مثال بالا index را در سمت راست صفحه می بینید که لیستی از مقادیر Seller است. زمانی که این index وجود دارد، مشخص است که Max دقیقا در کجای collection ما وجود دارد بنابراین به جای اینکه کل collection را بگردیم، دقیقا به محلی می رویم که Max در آنجا تعریف شده است. با این حساب سرعت اجرای برنامه ما شدیدا افزایش می یابد.
بنابراین ایندکس ها عالی هستند و باید برای همه فیلد هایمان ایندکس تعریف کنیم، مگر نه؟ مسئله به این سادگی ها نیست! تعریف کردن ایندکس برای تک تک فیلد ها باعث بالا رفتن سرعت کوئری های find می شود اما مشکلات دیگری را اضافه می کند! چه مشکلی؟ سرعت کوئری هایی مانند insert به طور جدی کاهش پیدا می کند! اگر یادتان باشد index لیستی ترتیبی (ordered list - یعنی ترتیب در آن مهم است) از مقادیر یک فیلد بود بنابراین اگر یک دستور insert داشته باشیم که مقدار جدیدی را به آن فیلد اضافه کند (مثلا یک سند با یک seller جدید را وارد کالکشن خود کنیم)، این مقدار باید در لیست ایندکس نیز وارد شده و کل لیست به روز رسانی شود. به عبارتی با هر دستور insert در کالکشن، باید یک insert نیز در index انجام شود. شاید در نگاه اول بگویید که این مسئله آنقدر ها هم بد نیست و حرفتان درست است اما فقط زمانی که برای یک یا دو فیلد، ایندکس داشته باشیم. اگر برای 10 فیلد مختلف ایندکس تعریف کنیم، در هر دستور insert باید 10 ایندکس را به روز رسانی کنیم! یعنی برای یک عملیات ساده باید چندین برابر فشار کاری را روی سرور وارد کنیم که اصلا کار عاقلانه ای نیست.
به همین دلیل است که می گوییم شما باید پایگاه داده و کالکشن خود را به طور کامل بررسی کرده و فیلد هایی را پیدا کنید که واقعا نیاز به index دارند. ما در این فصل دقیقا به همین موضوع می پردازیم و با انواع index ها آشنا خواهیم شد. همچنین با مثال های مختلف به شما توضیح می دهم که چطور بفهمیم کدام فیلد ها به ایندکس نیاز دارند و کدام فیلد ها باید بدون ایندکس باشند.
قبل از اینکه بخواهیم در جلسه بعد به سراغ کار های عملی برویم، باید پایگاه داده خودمان را آماده کنیم. من از قبل داده هایی را برایتان آماده کرده ام که باید آن را از لینک زیر دانلود کنید:
قبلا در مورد import کردن داده ها به شما توضیح داده بودم. ابتدا باید فایل بالا را دانلود کرده و درون پوشه مشخصی قرار دهید. سپس ترمینال یا command promt خود را در آن پوشه باز کرده و دستور زیر را اجرا کنید:
mongoimport persons.json -d contactData -c contacts --jsonArray
دستور بالا می گوید داده های فایل persons.json را در یک پایگاه داده ای به نام contactData و کالکشنی به نام contacts وارد کن. از آنجایی که این پایگاه داده و کالکشن را نداریم، به صورت خودکار برایمان ساخته خواهد شد (d- یعنی database و c- یعنی collection). در نهایت jsonArray را نیز اضافه می کنیم تا MongoDB بداند چه نوع داده هایی را دریافت کرده است و چطور آن ها را وارد کند. با اجرای کوئری بالا چنین پیامی می گیرید:
2020-05-11T11:50:35.258+0430 connected to: mongodb://localhost/ 2020-05-11T11:50:36.080+0430 5000 document(s) imported successfully. 0 document(s) failed to import.
همانطور که می بینید این فایل حاوی 5 هزار سند یا document است بنابراین بسیار حجیم می باشد. حالا برای تست می توانیم دستور show dbs را اجرا کنیم (حتما مثل همیشه به MongoDB متصل باشید) تا پایگاه داده جدید را مشاهده کنید. در قسمت بعد به صورت عملی با داده ها کار خواهیم کرد.





در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.