Normalization یا نرمال سازی پایگاه داده
Database Normalization

نرمال سازی پایگاه داده (normalization) به فرآیندی گفته می شود که توسط آن پایگاه داده در قالب جدول و ستون مرتب می شود. سه مرحله نرمال سازی در پایگاه داده ها وجود دارد: اولین فرم طبیعی، دومین فرم طبیعی و سومین فرم طبیعی. ایده کلی نرمال سازی این است که هر جدول فقط داده هایی در رابطه با موضوع خاصی را ذخیره کند.
فرض کنید پایگاه داده ای دارید که با استفاده از آن کار های زیر را انجام می دهید:
- شناسایی فروشنده های شرکت
- لیست مشتریانی که شرکت با آن ها تماس گرفته است
- شناسایی اینکه کدام فروشنده ها با کدام مشتریان تماس گرفته اند
اگر هدف هر جدول خود را فقط به یکی از این موارد اختصاص بدهید، داده های تکراری در جداول به حداقل خود می رسد. ما در این مقاله به سراغ بررسی قوانین نرمال سازی پایگاه داده می رویم و از سه مرحله ای که گفته شد (اولین فرم طبیعی، دومین فرم طبیعی و سومین فرم طبیعی) عبور خواهیم کرد. هر بار که یکی از این سه مرحله را روی پایگاه داده خود پیاده سازی می کنیم، پایگاه داده ما منظم تر شده و احتمال بروز خطا در آن کمتر می شود.
نکته: برای مطالعه این مقاله آشنایی با مباحث اولیه SQL و پایگاه داده الزامی است.
دلایل نرمال سازی پایگاه داده
سه دلیل اصلی برای نرمال سازی پایگاه داده وجود دارد:
- کاهش تکرار داده در پایگاه داده
- حذف یا کاهش شانس بروز data anomaly
- کاهش پیچیدگی کوئری ها، مخصوصا جست و جو ها
data anomaly یا «ناهنجاری داده» زمانی اتفاق می افتد که پایگاه داده نرمال سازی نشده باشد و طراحی آن دچار مشکلات جدی باشد. یک مثال از پایگاه داده ای که دچار ناهنجاری داده باشد این است که با حذف بخشی از داده ها، بخش های دیگر داده ها نیز حذف شود. مثلا اگر یک کتابخانه داشته باشیم و فردی کتابی را امانت گرفته باشد، ما نامش را به همراه نام کتاب قرض گرفته شده در پایگاه داده ذخیره می کنیم. زمانی که آن فرد کتاب را برگرداند باید این داده ذخیره شده در پایگاه داده را حذف کنیم اما با حذف آن کاربر، آن کتاب نیز از پایگاه داده حذف می شود! این نتیجه طراحی بد پایگاه داده است.
برای درک بهتر بیایید به یک جدول ساده نگاه کنیم که نرمال سازی نشده است:

ستونی که زیرش خط کشیده شده است (EmployeeID - حاوی آیدی کارکنان شرکت) همان primary key در این جدول است. اگر به تصویر بالا با دقت نگاه کنید متوجه می شوید که این جدول چندین هدف مختلف را به صورت همزمان دنبال می کند:
- شناسایی فروشنده های شرکت (ستون SalesPerson)
- شناسایی دفتر های فروش (ستون SalesOffice) و شماره تلفن آن دفترها (ستون OfficeNumber)
- اتصال یک فروشنده به یک دفتر فروش
- نمایش مشتریان هر فروشنده
چنین جدولی نشان از طراحی بسیار بد و غیرحرفه ای است. مشکلات زیادی در این پایگاه داده وجود دارد که اولین آن ها تکرار داده است. مثلا برای هر فروشنده، هم دفتر فروش و هم شماره تلفن آن را ذخیره کرده ایم بنابراین داده ها مرتبا تکرار می شوند. این مسئله به خودی خود دو مشکل بزرگ را برایمان ایجاد می کند. اولا حجم پایگاه داده را بی جهت افزایش می دهد که خودش باعث کاهش سرعت پایگاه داده می شود و دوما مدیریت تغییر داده ها در چنین پایگاه داده ای بسیار دشوار است.
منظور من از مدیریت تغییر داده چیست؟ منظورم هر عملیاتی مانند ویرایش (UPDATE) یا حذف (DELETE) و غیره است. مثلا فرض کنید دفتر فروش شیکاگو (Chicago) را به شهر Evanston منتقل کرده باشیم. حالا برای تغییر این موضوع در پایگاه داده باید شهر شیکاگو را برای تمام فروشنده ها (SalesPersons) ویرایش کنیم که یک UPDATE عظیم روی کل پایگاه داده خواهد بود. این یک مثال خوب از data anomaly (ناهنجاری داده) است که به طور خاص modification anomalies (ناهنجاری ویرایش) محسوب می شود.
نوع دیگری از ناهنجاری داده Insert Anomaly یا ناهنجاری ثبت است؛ در جدول بالا تا زمانی که اطلاعات تمام ستون ها را نداشته باشیم نمی توانیم داده هایی را ثبت کنیم. مثلا تا زمانی که فروشنده خود را نشناسیم و اطلاعاتش را نداشته باشیم نمی توانیم یک دفتر فروش را اضافه کنیم. چرا؟ به دلیل اینکه برای اضافه کردن یک ردیف به چنین جدولی باید EmployeeID (آیدی کارمند) را داشته باشیم. حتما یادتان است که EmployeeID همان primary key جدول ما بود بنابراین نمی توانیم آن را خالی بگذاریم.
ناهنجاری بعدی Update Anomaly یا ناهنجاری ویرایش است. در جدول بالا اگر شماره تلفن یک دفتر فروش تغییر کند باید آن را در چندین محل مختلف ویرایش کنیم در غیر این صورت ممکن است برخی از ردیف ها شماره قدیمی را داشته باشند. در نهایت ناهنجاری حذف یا Deletion Anomaly را داریم که حتما می توانید معنی اش را حدس بزنید. مثلا اگر آقای John Hunt بازنشست بشود و ما ردیف او را از جدول بالا حذف کنیم اطلاعات دفتر فروش نیویورک را نیز از دست می دهیم!
در نهایت آخرین دلیل نرمال سازی پایگاه داده مسئله ساده سازی کوئری ها است. اگر بخواهیم در جدول بالا یک مشتری خاص (مثلا Ford) را پیدا کنیم باید چنین کوئری بنویسیم:
SELECT SalesOffice FROM SalesStaff WHERE Customer1 = ‘Ford’ OR Customer2 = ‘Ford’ OR Customer3 = ‘Ford’
طبیعتا اگر مشتریان در یک جدول جداگانه بودند مجبور به نوشتن چنین کوئری بدی نبودیم. مسئله زمانی بدتر می شود که بخواهید نتایج را بر اساس مشتریان مرتب کنید. در این حالت باید سه کوئری UNION جداگانه بنویسیم!
تعریف نرمال سازی پایگاه داده
نرمال سازی پایگاه داده، راه حل ما برای مشکلات بخش قبل است. همانطور که گفتم نرمال سازی سه حالت مختلف دارد:
- اولین حالت نرمال یا 1NF: داده ها در یک جدول رابطه ای ذخیره می شوند و هر ستون مقادیر اتمی (atomic) را قبول می کند. مقادیر اتمی مقادیر تک و مستقل هستند (گروهی از داده ها نیستند). همچنین هیچ ستونی نمی تواند تکرار شود.
- دومین حالت نرمال یا 2NF: جدول در حالت نرمال اول است و تمام ستون ها وابسته به primary key در آن جدول هستند.
- سومین حالت نرمال یا 3NF: جدول در حالت نرمال دوم است و ستون ها فقط به صورت غیر ترایا به primary key وابسته هستند.
احتمالا در نظر اول متوجه این حالت ها نشوید اما مشکلی نیست. ما در ادامه این مقاله به صورت کامل توضیحاتی را ارائه خواهیم کرد.
توجه داشته باشید که علاوه بر سه حالت بالا، حالت های دیگری مانند BCNF نیز وجود دارند اما BCNF از مباحث پیشرفته است و برای یادگیری نرمال سازی الزامی نیست. تمام مراحل بالا به هم وابسته هستند، یعنی برای اینکه پایگاه داده شما به سومین حالت نرمال برسد باید حتما به دومین حالت نرمال و اولین حالت نرمال نیز رسیده باشد.
ما برای توضیح نرمال سازی و حالت های آن در این مقاله از جدول ساده زیر استفاده می کنیم:
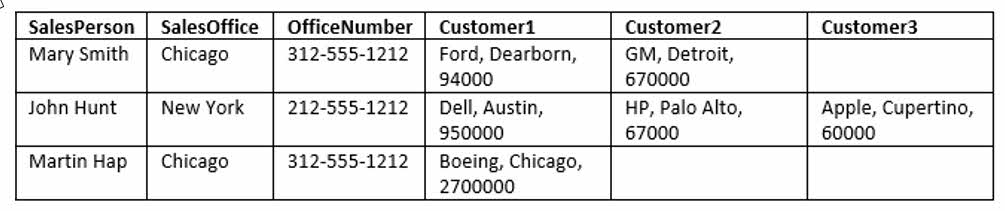
باید بتوانید سه مشکل بزرگ این جدول را به سادگی تشخیص بدهید:
- این جدول به جای تمرکز روی یک موضوع خاص، چندین موضوع (فروشنده، دفاتر، مشتری) را در برمی گیرد.
- مشتریان در قالب ستون های مختلف تکرار می شوند (ستون های Customer1 و Customer2 و Customer3).
- آدرس مشتریان درون ستون هایشان قرار گرفته است (ستون های Customer1 و Customer2 و Customer3).
اولین حالت نرمال (1NF)
اولین قدم برای طراحی یک جدول SQL این است که مطمئن شویم داده ها در حالت نرمال اول قرار دارند. این مسئله باعث بهتر شدن کوئری های جست و جو و فیلتر کردن داده ها می شود. اگر از دید اولین حالت نرمال به جدول بالا نگاه کنیم متوجه سه مشکل اصلی می شویم:
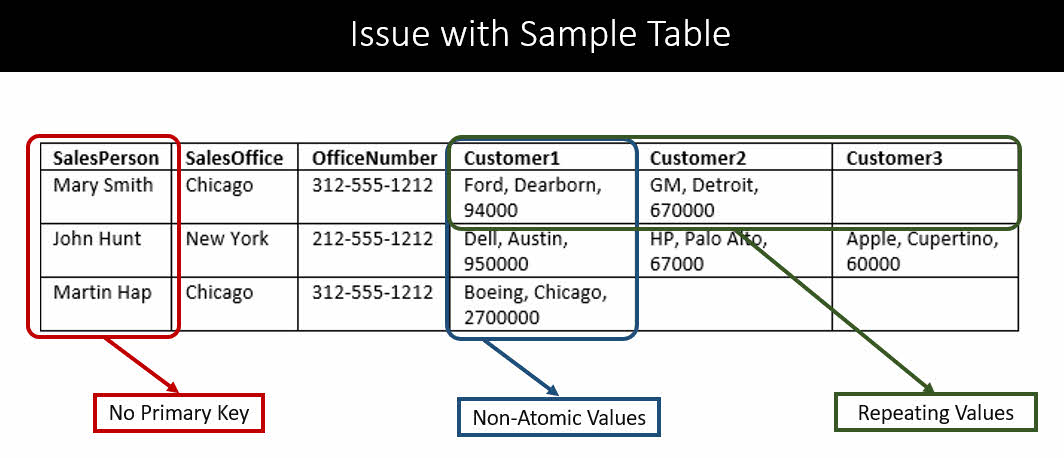
اولا هیچ primary key وجود ندارد، دوما مقادیر ذخیره شده در ستون های Customer اتمی (atomic) نیستند و سوما داده ها و ستون های تکراری داریم. منظور ما از داده های اتمی داده هایی هستند که تقسیم نمی شوند. مثلا در ستون مشتری (customer) علاوه بر نام مشتری (Ford) آدرس او (Dearborn, 94000) را نیز ذخیره کرده ایم. چنین داده ای می تواند به دو قسمت «نام مشتری» و «آدرس مشتری» تقسیم شود بنابراین اتمی نیست اما چیزی مانند «نام مشتری» قابل تقسیم به واحد های کوچکتر نیست بنابراین اتمی محسوب می شود.
همانطور که گفتم برای ورود به اولین حالت نرمال باید به سه قانون اصلی توجه کنیم:
- در هر جدول باید ستونی خاص (primary key) وجود داشته باشد که مسئولیت شناسایی هر ردیف را بر عهده بگیرد.
- مقادیر درون ستون ها اتمی باشند.
- ستون ها تکرار نشوند.
ما در ابتدا با نگاهی ساده به جدول بالا متوجه موضوع مهمی می شویم:
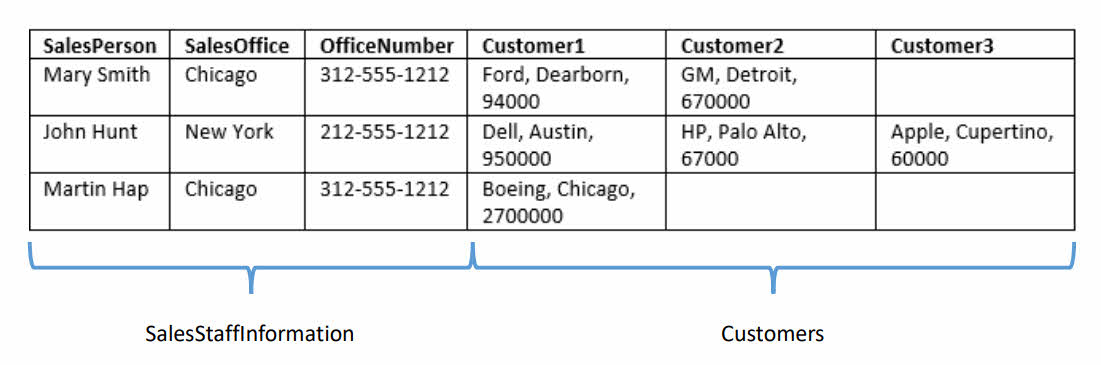
جدول ما می تواند از نظر موضوعی به دو دسته تقسیم شود: اطلاعات فروشنده (نماینده فروش، دفتر فروش و غیره) و اطلاعات مشتری. بنابراین می توانیم جدول را در ابتدا به دو جدول تقسیم کنیم:
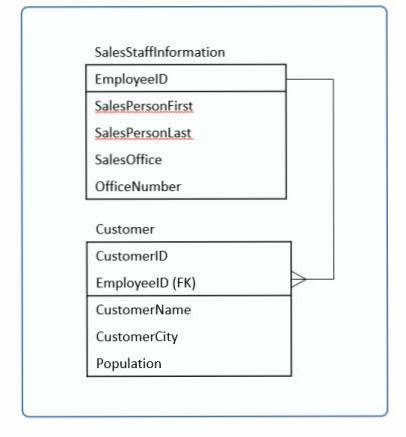
در واقع ما با استفاده از یک Foreign Key جدول مشتریان را به جدول فروشنده ها متصل کرده ایم. بنابراین داده های جدول ما در حالت نرمال اول بدین شکل خواهند بود:
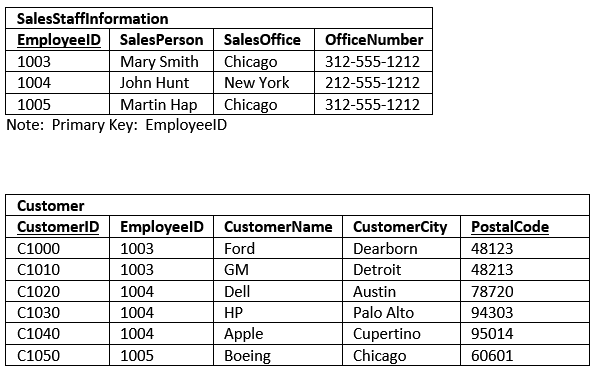
نکته: در این مقاله اگر زیر نام یکی از ستون ها خط کشیده شود یعنی آن ستون primary key می باشد.
دو جدول بالا که در حالت نرمال اول هستند از نظر فنی برتری های زیادی نسبت به جدول قبلی دارند:
- جدول اولیه و غیر نرمال، هر SalesStaffInformation را به سه مشتری (customer) محدود می کرد اما در دو جدول جدید نرمال سازی شده تعداد مشتریان بی نهایت است.
- مرتب کردن (عملیات sorting) مشتریان در طراحی قبلی تقریبا غیر ممکن بود مگر آنکه از دستورات UNION استفاده می کردید اما در طراحی جدید کاری بسیار ساده است.
- فیلتر کردن داده ها در جدول جدید مشتریان بسیار ساده تر است و می توانیم هر فیلتر دلخواهی را که خواستیم تعریف کنیم.
- تمام ناهنجاری های داده در جدول جدید از بین رفته است. مثلا می توانید بدون حذف یک فروشنده، مشتری او را حذف کنید.
دومین حالت نرمال (2NF)
هدف اصلی در این بخش محدود کردن جدول ها به یک موضوع خاص است. انجام این کار باعث می شود طراحی پایگاه داده واضح تر شده و از ناهنجاری های داده دوری کنیم. محور اصلی حالت نرمال دوم primary key ها هستند. مثلا در طراحی ما EmployeeID فقط یک primary key و یک عدد ساده است که به تنهایی هیچ معنایی ندارد اما با اضافه کردن نام، سن، موقعیت و اطلاعات دیگر باعث می شویم آن primary key یک فرد واقعی را توصیف کند.
یک جدول زمانی در دومین حالت نرمال قرار گرفته است که از هر دو قانون زیر پیروی کند:
- جدول در حالت نرمال اول باشد.
- تمام ستون های غیر کلیدی پایگاه داده وابسته به primary key باشند.
همانطور که تا این بخش توضیح داده ایم هر primary key باید توصیف کننده یکتا و منحصر به فردی برای هر ردیف از جداول ما باشد. زمانی که می گوییم ستون ها باید وابسته به primary key باشند منظورمان این است که برای پیدا کردن یک داده خاص (مثلا سن Kris - یکی از کارمندان) باید EmployeeID او را داشته باشیم.
بنابراین بهترین راه برای تشخیص این موضوع این است که به تک تک ستون های جدول نگاه کرده و از خودتان بپرسید: «آیا این ستون در حال توصیف primary key است؟» اگر پاسخ شما مثبت بود یعنی آن ستون وابسته به primary key است و جای گیری آن صحیح است اما اگر پاسخ منفی بود آن ستون باید به جدول دیگری منتقل شود.
زمانی که تمام ستون ها وابسته به primary key باشد یعنی تمام ستون ها در حال توصیف primary key هستند بنابراین «موضوع» جدول یک موضوع واحد است. اینجاست که متوجه منظور من می شوید؛ هدف ما در دومین حالت نرمال این است که موضوع واحدی را برای هر جدول انتخاب کنیم.
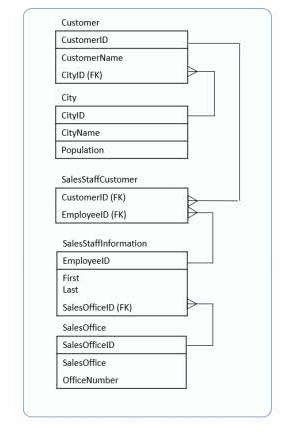
تا این لحظه جدول ما به حالت نرمال اول رسیده است اما هنوز مشکلاتی را دارد. اولین مشکل اینجاست که چندین داده داریم که به طول کامل به مشتری مربوط نیستند بنابراین به فیلد CustomerID (همان primary key برای جدول مشتریان) وابسته نیستند. با مشاهده تصویر زیر متوجه می شوید که برای دریافت یک مشتری نباید نیازی به دانستن هر دو فیلد CustomerID و EmployeeID باشد.
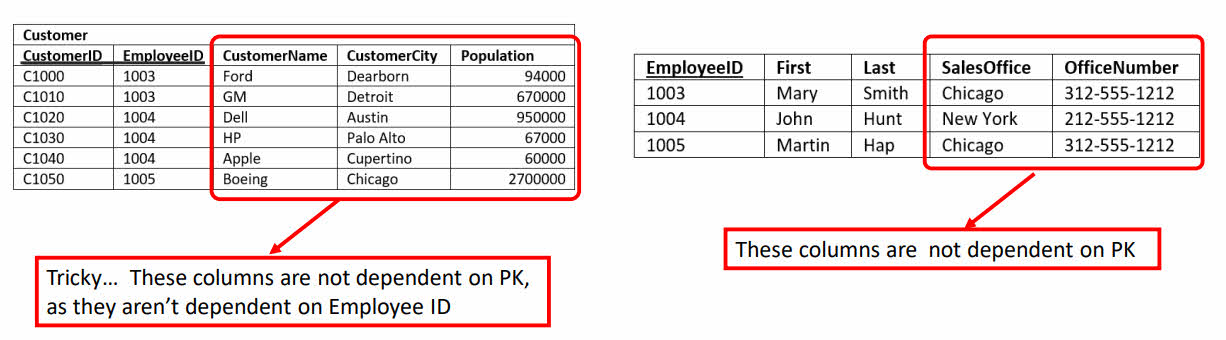
در ابتدا دوباره یادآوری می کنم که اگر زیر نام ستونی خط کشیده شود، آن ستون primary key است. در تصویر بالا و در جدول مشتریان (Customer) مشاهده می کنید که دو ستون اول (CustomerID و EmployeeID) با هم به عنوان primary key انتخاب شده اند که به آن یک کلید کامپوزیت یا ترکیبی می گوییم.
دوباره به تصویر بالا توجه کنید. در جدول فروشندگان دو ستون SalesOffice (دفتر فروش) و OfficeNumber (شماره تلفن دفتر فروش) را داریم که اصلا ارتباطی با primary key این جدول (یعنی آیدی کارمندان - EmployeeID) ندارند. این دو ستون به ما نشان می دهند که کارمند مورد نظر در چه شهری کار می کند اما خود کارمند را توصیف نمی کنند.
همچنین در جدول مشتریان نیز سه ستون CustomerName (نام مشتری) و CustomerCity (شهر مشتری) و Population (جمعیت شهر) را داریم که ارتباطی به primary key جدول (ستون های CustomerID و EmployeeID به صورت ترکیبی) ندارند.
برای حل این مشکل باید یک جدول دیگر به نام SalesOffice را طراحی کنیم که یک foreign key را به جدول کارمندان داشته باشد تا بتوانیم تشخیص بدهیم هر کارمند در کجا کار می کند. از طرف دیگر جدول مشتریان را داریم که یکی از فیلد های سازنده primary key آن EmployeeID می باشد که مشکل اصلی ما است بنابراین آن را از این جدول حذف می کنیم. با انجام این کار جدول هایمان خالص می شوند و هر کدام یک موضوع واحد را دارند.
حالا یک جدول دیگر به نام SalesStaffCustomer را تعریف می کنیم تا مشخص کند هر فروشنده با چه مشتریانی تماس گرفته است و دو ستون خواهد داشت: CustomerID و EmployeeID. این دو ستون به همراه هم یک primary key را تشکیل می دهند اما هر کدام به طور جداگانه یک foreign key به جدول های مشتریان و فروشندگان هستند. این جدول بین دو جدول دیگر یک اتصال برقرار می کند.
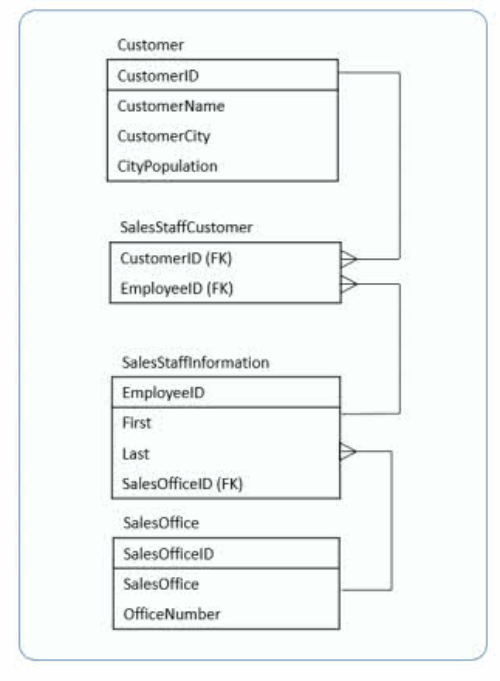
سومین حالت نرمال (3NF)
یک جدول زمانی در حالت نرمال سوم است که هر دو شرط زیر را رعایت کند.
- در حالت نرمال دوم باشد.
- ستون های آن به صورت غیر ترایا به primary key وابسته باشند.
برای درک این موضوع باید با transitive یا ترایا بودن یا گذرا بودن آشنا شویم. در منطق ترایایی به معنی این است که اگر چیزی از ابتدا تا انتهای صحیح باشد از وسط تا انتها نیز صحیح است. مثلا اگر A از B بزرگتر باشد و B از C بزرگتر باشد بنابراین حتما A از C بزرگتر است. در این حالت ما یک مقایسه ترایا را بین A و C داریم. برای ساده تر شدن درک شما از این مطلب به جای کلمه «ترایا» می توانید از واژه «گذرا» استفاده کنید.
اما وابستگی ترایا به چه معنی است؟ ساده ترین توضیح آن بدین صورت است: مقدار یک ستون با استفاده از یک ستون واسطه به ستون دیگری وابسته است. سه ستون ساده را در نظر بگیرید: AuthorNationality (ملیت نویسنده)، Author (نویسنده) و Book (کتاب). مقادیر AuthorNationality و Author وابسته به Book هستند و زمانی که کتابی را مد نظر داشته باشید می توانید دیگر ستون های آن مانند نویسنده و ملیت او را نیز پیدا کنید. در عین حال ستون ملیت نویسنده به ستون نویسنده وابسته است، یعنی زمانی که نویسنده را بشناسید می توانید ملیت او را تعیین کنید. با این حساب AuthorNationality با واسطه Author به Book وابستگی ترایا دارد.
اگر بخواهیم این مطلب را خلاصه تر بگوییم سه ستون را فرض می کنیم: A و B و PK (همان primary key). اگر مقدار A به PK وابسته باشد و B نیز به PK وابسته باشد و A نیز به B وابسته باشد، می توان گفت A با واسطه B به PK وابسته است. به عبارت دیگر A به صورت ترایا یا گذرا به PK وابسته است.
بیایید یک مثال از دنیای واقعی را در نظر بگیریم. آیا نام کوچک و نام خانوادگی به هم وابستگی ترایا دارند؟ خیر، چرا که نام کوچک برایتان انتخاب می شود اما نام خانوادگی از سمت پدر می آید. آیا BMI (شاخص توده بدنی) بیشتر از ۲۵ با اضافه وزن وابستگی ترایا دارند؟ بله! BMI بالای ۲۵ به معنی اضافه وزن است. با این حساب می توانیم یک وابستگی ترایا یا گذرا را در جدول مشتریان پیدا کنیم:

تمام این ستون ها به ستون Primary Key وابسته هستند (حالت نرمال دوم) اما بین جمعیت شهر مشتری (CustomerCity) و جمعیت آن شهر (population) یک وابستگی مهم برقرار است. این مسئله باعث می شود احتمال بروز مشکل در برنامه ما بالا برود. چرا؟ یکی از ناهنجاری های داده ای که می تواند در این بخش اتفاق بیفتد update anomaly یا ناهنجاری در به روز رسانی است. فرض کنید مشتری ما شهر خود را عوض کند. در این حالت ممکن است از یاد ببریم که جمعیت آن شهر را نیز تصحیح کنیم و بدین شکل مشکل بزرگی خواهیم داشت.
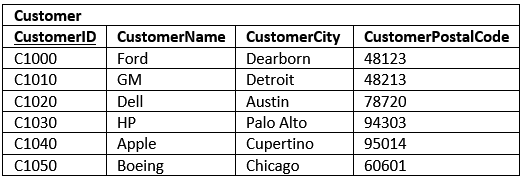
برای حل این مشکل می توانیم یک جدول جداگانه را طراحی کنیم که حاوی جمعیت و شهر باشد:
جدول های دیگر نیز به صورت خودکار در سومین حالت نرمال هستند و نیازی به انجام کاری نداریم.
آیا نرمال سازی اضافه کاری است؟
نرمال سازی یک اصل بسیار مهم در طراحی برنامه هایی است که باید به شکل قابل اطمینان طراحی شوند اما آیا برای تمام برنامه ها مهم است؟ پاسخ من خیر است. نرمال سازی برای هر برنامه ای نیست و حد و حدودی دارد. مثلا شاید شما به عنوان یک توسعه دهنده اعتقاد داشته باشید که انتقال جدول بالا به سومین حالت نرمال اضافه کاری و طراحی بیش از حد است و بیشتر باعث پیچیدگی کار می شود. من شخصا با حرف شما موافق هستم و به نظرم چنین ریزه کاری هایی فقط در برنامه های بسیار مهم (مثلا برنامه های تجاری و بانکی در سطح کشوری یا بین الملل) یا برنامه هایی با بازدید روزانه سنگین (وب سایت های بسیار مشهور) اهمیت پیدا می کنند. اگر شما یک وبلاگ شخصی دارید تقریبا هیچ وقت به چنین چیزی نیاز نخواهید داشت.
در عین حال به عنوان یک قانون کلی می گویم که بهتر است همیشه تمام پایگاه های داده خود را تا دومین حالت نرمال برسانید چرا که اگر هیچ نرمال سازی در پایگاه داده شما اتفاق نیفتد، مطمئن باشید در آینده با مشکل مواجه خواهید شد. من این مشکلات را در ابتدای همین مقاله برایتان توضیح دادم و دیدیم که انجام عملیات های sort و فیلتر کردن داده ها بدون نرمال سازی کار بسیار سختی خواهد بود.
منبع: وب سایت essentialsql









در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.
در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.