تغییرات و ویژگیهای جدید نسخه 8 زبان PHP چیست؟
?What is New in PHP 8

بر اساس گفته های مختلف، نسخه هشتم زبان PHP در ماه دسامبر امسال (سال 2020) ارائه خواهد شد که دارای تغییرات زیادی است. در واقع بسیاری از RFC های PHP در حال حاضر تایید شده اند. بنابراین می توانیم برخی از آن ها را بررسی کنیم اما به هر حال قسمتی از تغییرات PHP 8 هنوز تایید نشده اند و نمی توان در مورد آن ها نظر قطعی داد. هدف این مقاله تنها آشنا کردن شما با برخی از تغییرات PHP 8 می باشد. بنابراین بدون مقدمه وارد بحث می شویم.
کامپایلر JIT
معروف ترین و پر سر و صداترین قابلیت معرفی شده در PHP 8 قابلیتی به نام Just-in-time (JIT) compiler است اما این کامپایلر چه کاری می کند؟ RFC مربوطه می گوید:
“PHP JIT is implemented as an almost independent part of OPcache. It may be enabled/disabled at PHP compile time and at run-time. When enabled, native code of PHP files is stored in an additional region of the OPcache shared memory and op_array→opcodes[].handler(s) keep pointers to the entry points of JIT-ed code.”
بنابراین JIT قسمتی از OPcache است و شما می توانید با اختیار خود آن را فعال یا غیرفعال کنید. برای اینکه بخواهیم با JIT بهتر آشنا شویم و مطلب بالا را دقیقا برایتان ترجمه کنم، ابتدا باید بدانیم که PHP چطور یک اسکریپت را از اول تا آخر اجرا می کند. البته قبل از نام بردن از چهار مرحله باید با چند تعریف ساده آشنا باشید:
machine code: زبان های برنامه نویسی برای راحت شدن کار توسعه دهندگان ایجاد شده اند و معمولا طوری طراحی شده اند که تا حدی به زبان انسان نزدیک باشند. مشکل اینجاست که کامپیوترها نمی توانند این دستورات را بخوانند، بنابراین تمام زبان های برنامه نویسی باید به machine code تبدیل شوند. machine code کدهای باینری و هگزادسیمالی هستند که برای CPU آشنا هستند بنابراین می توانند به صورت مستقیم توسط CPU اجرا شوند. تبدیل اسکریپت و کدهای شما به machine code، بسته به زبان برنامه نویسی، یا توسط کامپایلرها و یا توسط مفسرها انجام می شود.
opcode: در هنگام اجرای یک اسکریپت، کدهای اسکریپت شما به opcode تبدیل می شوند که کدهایی میانی و low-level هستند (یعنی به زبان کامپیوتر یا machine code نزدیک تر هستند و تبدیل آن ها به machine code زمان کمتری می برد). شما می توانید opcode های PHP را در این لیست مشاهده کنید.
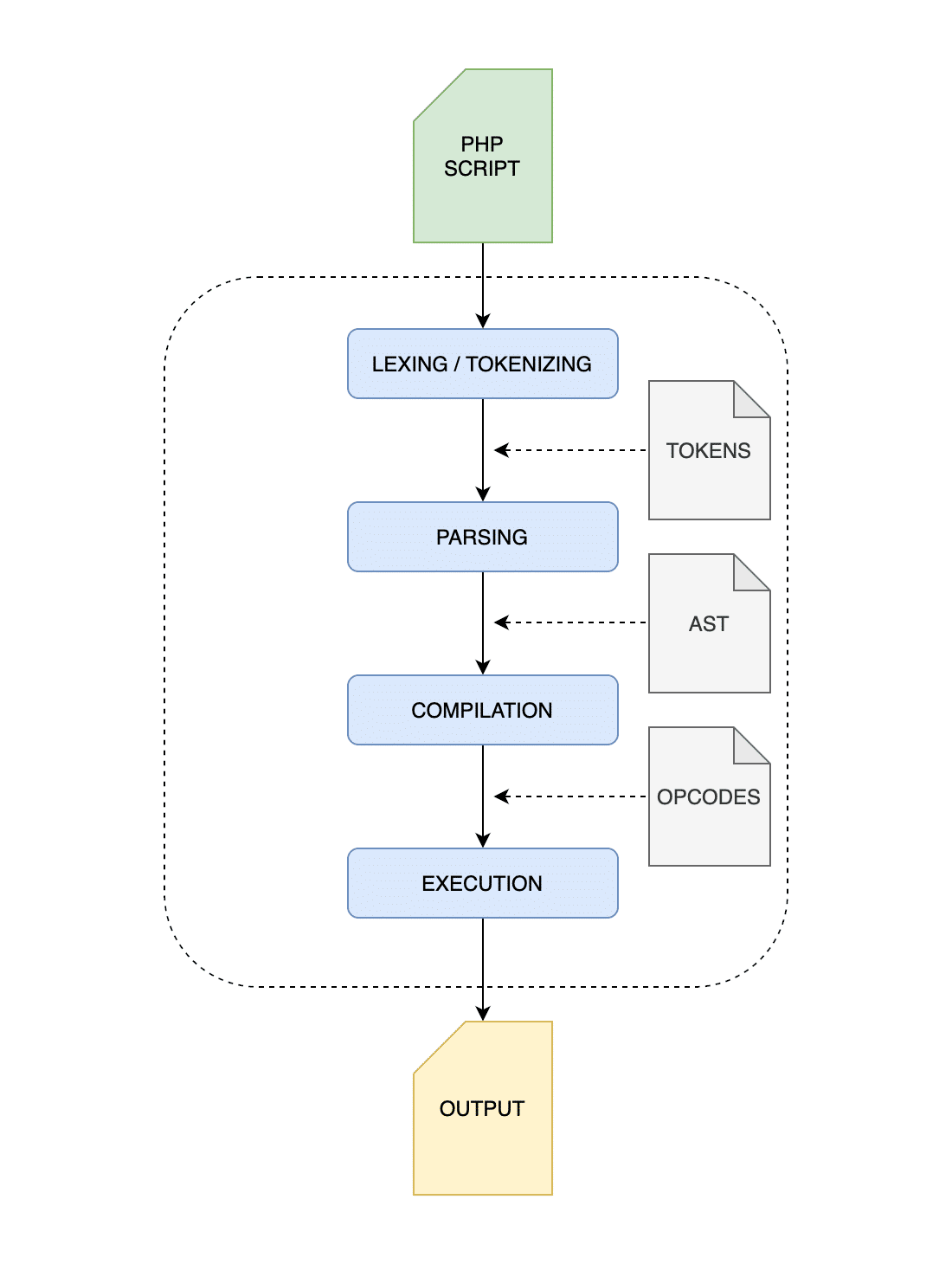
حالا می توانیم اجرا شدن اسکریپت های PHP را در چهار مرحله اصلی بررسی کنیم:
- Lexing/Tokenizing: در این مرحله که مرحله اول می باشد، مفسر (interpreter) زبان PHP وارد عمل شده، تمام اسکریپت را خوانده و توکن هایی را می سازد.
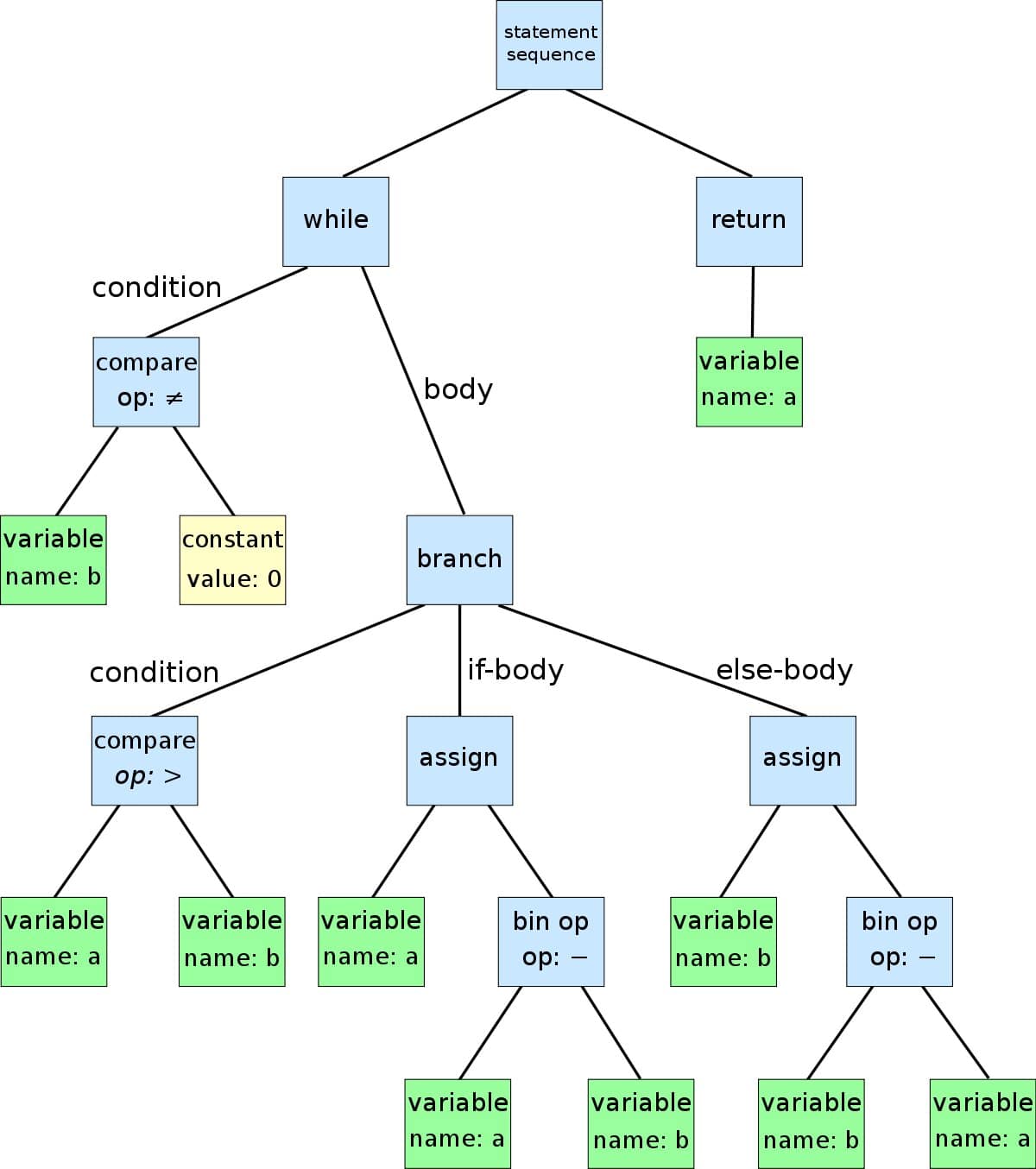
- Parsing: مفسر چک می کند که آیا اسکریپت نوشته شده با قواعد نحوی (syntax rules) مطابقت دارد یا خیر و سپس از توکن های ساخته شده در مرحله قبل برای ساخت چیزی به نام Abstract Syntax Tree (به اختصار AST) استفاده می کند. AST به زبان ساده یک نمای سمبلیک درختی و سلسله مراتبی از سورس کد شما است.
- Compilation: مفسر در این مرحله در درخت AST گردش کرده و node های آن را به opcode های سطح پایین Zend تبدیل می کند. این opcode های سطح پایین شناسه هایی عددی هستند که نوع دستورات اجرا شده توسط ماشین مجازی Zend را مشخص می کنند (اطلاعات بیشتر در این لینک).
- Interpretation: در این مرحله opcode ها تفسیر شده و در ماشین مجازی Zend یا همان Zend VM اجرا می شوند.
تمام مراحل بالا در تصویر زیر خلاصه شده است:
همچنین یک نمونه برای درخت AST را در تصویر زیر می بینید:
با این حساب قابلیت OPcache (که ربطی به نسخه جدید ندارد) چطور PHP را سریع تر می کند؟ برای پاسخ به این سوال باید بحث را به سه قسمت جداگانه تقسیم کنیم:
- افزونه OPcache چیست؟
- preloading چیست؟
- درک بهتر JIT
افزونه OPcache چیست؟
زبان PHP یک زبان تفسیری (interpreted language) می باشد؛ یعنی زمانی که درخواستی برای سرور ارسال می شود، اسکریپت ما با ترتیب ذکر شده (parse شدن و کامپایل شدن و الی آخر) اجرا می شود. مسئله اینجاست که کامپایل شدن و parse شدن اسکریپت ما در هر درخواست، دوباره اجرا می شود. برخی از زبان های برنامه نویسی دیگر Compiled language هستند. مهم ترین تفاوت زبان های interpreted و compiled این است که سورس کد زبان های compiled توسط یک کامپایلر به machine code (کدهایی که به صورت مستقیم برای کامپیوتر قابل فهم باشند) تبدیل می شوند اما سورس کد زبان های interpreted با هر درخواست دوباره کامپایل می شود که می تواند باعث به هدر رفتن منابع CPU شود. چطور؟
تصور کنید هر بار که اسکریپت شما اجرا می شود، سورس کد باید دوباره به machine code کامپایل شود اما اگر شما سورس کد خود را تغییر نداده باشید، machine code های جدید برابر با machine code های قبلی خواهند بود! به عبارتی ما منابع خود را هدف دادیم و با استفاده از CPU دوباره همان راهی را رفتیم که قبلا رفته بودیم و اصلا نیازی به این کار نبود. اگر می توانستیم به نوعی جلوی این مشکل را بگیریم، سرعت برنامه بسیار بالا می رفت! از نسخه 5.5 زبان PHP قابلیت OPcache ارائه شده است و به صورت پیش فرض فعال است. وب سایت رسمی PHP در این باره می گوید:
“OPcache improves PHP performance by storing precompiled script bytecode in shared memory, thereby removing the need for PHP to load and parse scripts on each request.”
به زبان ساده تر با استفاده از OPcache اسکریپت شما فقط یک بار اجرا می شود (چهار مرحله اجرایی PHP فقط در دفعه اول اجرا خواهد شد) و سپس opcode ها یا machine code در مموری ذخیره می شود تا در درخواست های بعدی نیازی به کامپایل شدن دوباره اسکریپت نداشته باشیم. در واقع کامپایل شدن دوباره اسکریپت فقط زمانی رخ می دهد که PHP متوجه شود، اسکریپت شما نسبت به دفعه قبل تغییر کرده است، بدین صورت می توانیم جلوی هدر رفتن منابع سرور را بگیریم.
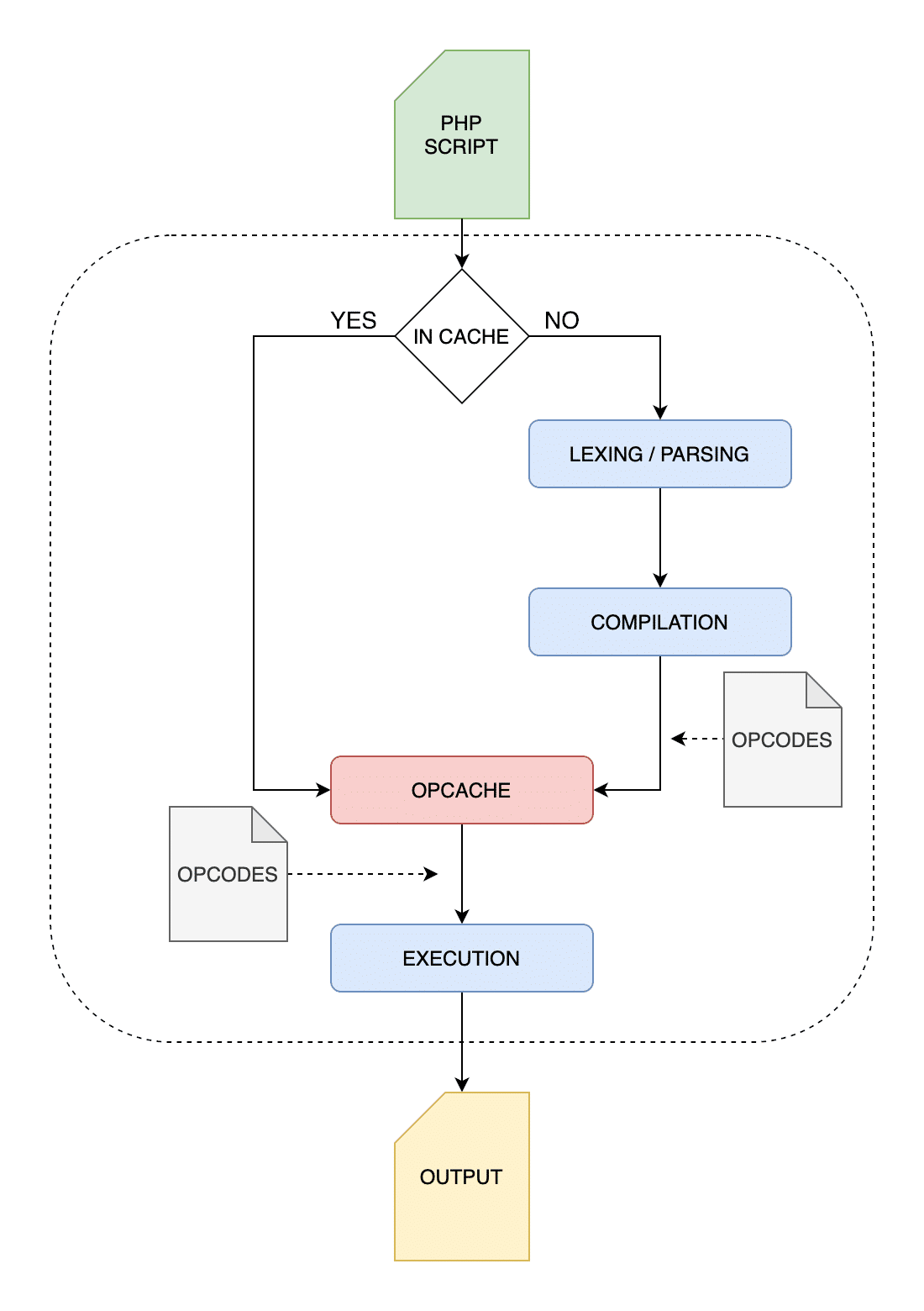
برایتان توضیح دادم که زبان برنامه نویسی PHP یک زبان تفسیری (interpreted language) می باشد و این مسئله بدین معنی است که هر اسکریپت در هر درخواست دوباره کامپایل می شود که باعث هدر رفتن و درگیر شدن بیهوده CPU سرور ما می شود. برای جلوگیری از این موضوع از نسخه 5.5 زبان PHP قابلیتی به نام OPcache به این زبان اضافه شده است که باعث می شود اسکریپت شما فقط در دفعه اول کامپایل شود و کدهای کامپایل شده در مموری ذخیره شوند تا در زمان نیاز بدون کامپایل شدن اجرا شوند.
سوال: چطور بفهمیم که OPcache برای ما فعال است؟
پاسخ: بستگی به محیط کاری شما دارد. اگر از وبسایت های میزبانی (hosting) استفاده می کنید باید به مشخصات سرورها نگاه کنید. شرکت های میزبانی معتبر معمولا مشخص میکنند که OPcache فعال است یا خیر (معمولا به صورت پیش فرض و بدون هزینه اضافی فعال است) اما اگر چیزی پیدا نکردید با ایجاد تیکت در پشتیبانی از آن ها سوال کنید. اگر سرورهای خودتان را دارید یا سروری اختصاصی را به صورت کامل اجاره کرده اید باید از تابع ()phpinfo یا فایل php.ini استفاده کنید و به دنبال اطلاعات Opcode Caching باشید.
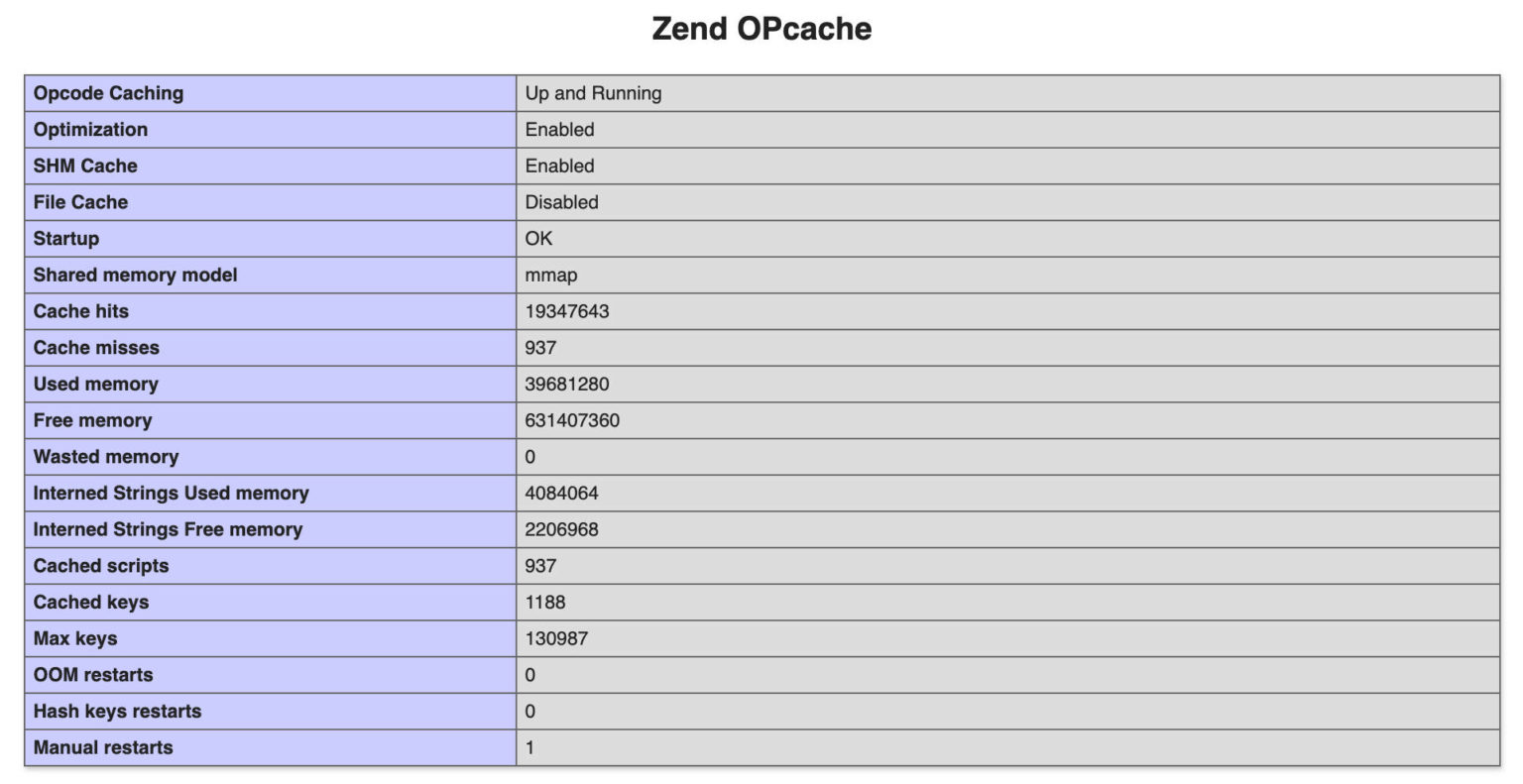
همچنین تمام اطلاعات و پیکربندی های مربوط به OPcache در وبسایت رسمی PHP موجود است.
Preloading چیست؟
preloading یکی از قابلیت های جدید در OPcache است که در نسخه 7.4 از زبان PHP ارائه شده است، بنابراین یک ویژگی نسبتا جدید محسوب می شود (RFC در سال 2018 ایجاد شده است). این قابلیت به شما اجازه می دهد که قبل از اجرا شدن کدهای برنامه، چند اسکریپت خاص و دستچین شده توسط خودتان را وارد مموری OPcache کنید اما معمولا برای وبسایتهای عادی آنچنان تغییری را حاصل نمیکند.
ایده preloading توسعه ایده OPcache است. زبان PHP از انواع و اقسام سیستمهای کش برای opcode های خود استفاده میکند که OPcache یکی از آنها است (مثال های دیگر عبارت اند از: APC و MMCache) اما این سیستم های caching، مشکل هدر رفتن منابع را به صورت 100 در 100 حل نمی کنند. چرا؟ فرض کنید درخواستی را به یک برنامه ارسال کرده ایم که چند اسکریپت دارد. برای استفاده از OPcache باید فایل مورد نظر را که در مموری کش شده است از خود مموری دریافت کنیم و به اسکریپتی بدهیم که به عنوان وابستگی از آن استفاده میکند. علاوه بر این باید بررسی کنیم که آیا فایل تغییر کرده است یا خیر؟ آیا نیاز به کامپایل کردن دوباره کدها داریم؟ همچنین باید قسمتی از کلاس ها یا توابع را از مموری اشتراکی (shared memory - محل ذخیره OPcache) دریافت کرده و به processing memory (مموری در حال پردازش) بدهیم. همچنین OPcache قابلیت تشخیص وابستگی ها (dependency) را ندارد بنابراین در هر درخواست باید وابستگی کلاس ها به هم یا فایل ها به هم را دوباره تشخیص داده و آنها را به هم لینک کنیم. تمام این فرآیند ها نیاز به منابع و زمان دارد بنابراین با اینکه OPcache کمک بسیار بزرگی است، اما هنوز جای پیشرفت دارد.
اینجاست که preloading وارد کار میشود و به ما اجازه می دهد منابع اصلی (مانند فریم ورک یا library ها) را در زمان راه اندازی سرور، قبل از اجرای هر کد دیگری و به صورت کش شده در مموری قرار بدهیم. با این کار زیرساخت برنامه ما همیشه کش شده است و سرعت اجرای برنامه بالاتر می رود.
JIT قدم بعدی در OPcache
با اینکه opcode ها کدهایی میانی و سطح پایین (low-level) هستند (یعنی به زبان کامپیوتر یا machine code نزدیک تر هستند و تبدیل آن ها به machine code زمان کمتری می برد) هنوز هم برای اجرا باید به machine code تبدیل شوند بنابراین هنوز هم یک میانجی داریم که باید کامپایل شود و طبیعتا این فرآیند زمان خواهد برد. تکنولوژی JIT به جای اینکه یک میانجی دیگر (معمولا به این میانجی ها Intermediate Representation می گوییم) ایجاد کند، با استفاده از DynASM (مخفف Dynamic Assembler for code generation engines) کدهای native را مستقیما از bytecode های PHP تولید میکند. به زبان ساده تر JIT کدهای میانی را مستقیما به machine code تبدیل میکند و با دور زدن فرآیند compilation می تواند در سرعت و مصرف منابع سرور تاثیر بسزایی بگذارد.
آقای Zeev Surasky (از نویسندگان پروپوزال JIT) در ویدیویی در کانال یوتیوب خود تاثیر JIT در برخی از محاسبات خاص را نشان داده است:
مثالی که در ویدیوی بالا از آقای Zeev Surasky می بینید یک حالت خاص است به همین دلیل برای ما این سوال پیش می آید که آیا JIT در وبسایت های عادی یا وبسایت های وردپرسی نیز موثر خواهد بود؟ در RFC مربوط به JIT گفته شده است که JIT به طور کلی سرعت PHP را بالاتر خواهد برد و تست های اولیه نیز نشان می دهند که JIT در عملیات هایی که نیاز شدیدی به CPU دارند، تاثیر بسزایی دارد. البته RFC این هشدار را به همه داده است که:
like the previous attempts – it currently doesn’t seem to significantly improve real-life apps like WordPress (with opcache.jit=1235 326 req/sec vs 315 req/sec). It’s planned to provide additional effort, improving JIT for real-life apps, using profiling and speculative optimizations.
در واقع در تست های قبلی تفاوت چشم گیری در برنامه هایی مانند وردپرس برای استفاده از JIT نداشتیم (326 درخواست بر ثانیه با JIT و 315 درخواست بر ثانیه بدون JIT) البته در آینده بهینه سازی هایی ارائه خواهد شد تا شاید این تفاوت بیشتر شود.
یعنی زمانی که JIT فعال باشد، کدها به جای اجرا شدن توسط Zend VM، توسط خود CPU اجرا خواهند شد و طبیعتا این مسئله باعث افزایش سرعت محاسبات خواهد شد اما برنامه هایی مانند وردپرس به غیر از پردازش و محاسبات به فاکتورهای دیگری مانند بهینه سازی های پایگاه داده و درخواست های HTTP و غیره نیز وابسته اند. بنابراین JIT باعث ارتقاء شدید سرعت در برنامه شما نمی شود اما هنوز هم مزایای خود را دارد، مانند:
- ارتقاء شدید سرعت در کدهای عددی
- بالاتر رفتن سرعت برنامه های عادی PHP (هر چند کم)
- امکان انتقال کد از زبان C به PHP با توجه به افزایش سرعت
اعتبارسنجی برای trait های abstract
همانطور که می دانید زبان PHP می تواند به صورت شیء گرا نوشته شود اما وراثت آن از نوع single inheritance است که یعنی هر کلاس فقط می تواند از یک کلاس دیگر ارث بری داشته باشد. برای حل این موضوع trait ها معرفی شدند که در واقع راهی برای اجرای متدها در چندین کلاس هستند. هر trait می تواند متدهای abstract داشته باشد. به گفته documentation زبان PHP ما می توانیم از متدهای abstract در trait ها برای اجباری کردن آن در یک کلاس خاص استفاده کنیم، البته در این حالت باید signature یا امضای دو متد برابر باشد؛ یعنی تعداد و نوع آرگومان ها حتما یکی باشد. مثال:
<?php
trait Hello {
public function sayHelloWorld() {
echo 'Hello'.$this->getWorld();
}
abstract public function getWorld();
}
class MyHelloWorld {
private $world;
use Hello;
public function getWorld() {
return $this->world;
}
public function setWorld($val) {
$this->world = $val;
}
}
?>
با استفاده از متد getWorld و تعریف آن به صورت abstract، کلاس MyHelloWorld را مجبور به تعریف متدی به نام getWorld کرده ایم (نحوه تعریف آن به سلیقه خود این کلاس است - نکته الزامی، وجود این متد است). حالا بر اساس گفته Nikita Popov که پیشنهاد دهنده RFC بوده است، اعتبارسنجی signature ها پراکنده و به شکل زیر بوده است:
- در حالتی که پیاده سازی متد در کلاس استفاده کننده از trait انجام می شود، مجبور به اعتبارسنجی نیستیم و می توانیم آن را رد کنیم.
- زمانی که پیاده سازی متد از کلاس پدر می آید مجبور به اعتبارسنجی هستیم.
- زمانی که پیاده سازی متد از کلاس فرزند می آید، مجبور به اعتبارسنجی هستیم.
Nikita برای مورد اول مثال زیر را می زند:
trait T {
abstract public function test(int $x);
}
class C {
use T;
// Allowed, but shouldn't be due to invalid type.
public function test(string $x) {}
}
همانطور که می بینید آرگومان متد Test در trait از نوع عددی اما در کلاس C از نوع رشته ای است. این کد در PHP صحیح است اما از نظر Nikita نباید اینچنین باشد. این RFC جدید پیشنهاد می دهد که در صورت عدم همخوانی دو متد با یکدیگر، PHP باید یک Fatal Error را برگرداند (فارغ از اینکه متد اصلی از فرزند یا پدر یا غیره است):
Fatal error: Declaration of C::test(string $x) must be compatible with T::test(int $x) in /path/to/your/test.php on line 10
این RFC با رای کامل تایید شده است.
method signature های ناسازگار
در زبان PHP اگر signature دو method با هم سازگار نباشد، یا با خطای fatal یا با warning روبرو می شویم (بسته به اینکه مشکل اصلی کجاست). مثلا اگر کلاسی در PHP از یک interface استفاده کند و متدهای این دو از نظر signature با هم متفاوت باشند، یک خطای Fatal دریافت می کنیم. یک مثال ساده از بروز خطا از طریق وراثت interface:
interface I {
public function method(array $a);
}
class C implements I {
public function method(int $a) {}
}
اگر از PHP نسخه 7.4 به بعد استفاده می کنید، کد بالا یک خطای fatal خواهد داد که به شکل زیر است:
Fatal error: Declaration of C::method(int $a) must be compatible with I::method(array $a) in /path/to/your/test.php on line 7
اما اگر این ناسازگاری در signature ها بین متدهای کلاس پدر و فرزند باشد فقط یک خطای warning می گیریم. مثال:
class C1 {
public function method(array $a) {}
}
class C2 extends C1 {
public function method(int $a) {}
}
از PHP نسخه 7.4 به بعد، کد بالا یک warning به شکل زیر را نمایش می دهد:
Warning: Declaration of C2::method(int $a) should be compatible with C1::method(array $a) in /path/to/your/test.php on line 7
تا به اینجا طبق انتظارمان پاسخ گرفته ایم اما یک RFC جدید ثبت شده است که بر اساس آن، نتیجه تغییر signature ها بین دو متد در هر حالتی که باشند حتما fatal error خواهد بود. بنابراین مثال قبلی که رابطه پدر و فرزندی را به ما نشان می داد به جای Warning یک Fatal error به شکل زیر را نمایش می دهد:
Fatal error: Declaration of C2::method(int $a) must be compatible with C1::method(array $a) in /path/to/your/test.php on line 7
آرایه هایی با ایندکس منفی
در زبان PHP اگر آرایه ای با ایندکس منفی شروع شود (start_index < 0) ایندکس های بعدی از صفر شروع می شوند (بدون توجه به اینکه مقدار قبلی چقدر بوده است). به طور مثال متد Array_fill را در PHP در نظر بگیرید:
<?php $a = array_fill(5, 6, 'banana'); $b = array_fill(-2, 4, 'pear'); print_r($a); print_r($b); ?>
آرگومان اول start_index یا ایندکس اولیه برای شروع است، آرگومان دوم تعداد عناصری است که باید وارد آرایه شود و آرگومان سوم مقدار این عناصر است. خروجی دستور بالا به شکل زیر است:
Array
(
[5] => banana
[6] => banana
[7] => banana
[8] => banana
[9] => banana
[10] => banana
)
Array
(
[-2] => pear
[0] => pear
[1] => pear
[2] => pear
)
همانطور که می بینید ما برای آرایه دوم، ایندکس اولیه را 2- دادیم اما نکته مهم اینجاست که عضو بعدی آرایه 1- نیست بلکه مستقیما از صفر شروع می شود. برای اینکه مسئله روشن تر شود به جای 2- از 5- استفاده می کنم:
$a = array_fill(-5, 4, true); var_dump($a);
در نسخه های 7.4 به بعد PHP نتیجه زیر را می گیریم:
array(4) {
[-5]=>
bool(true)
[0]=>
bool(true)
[1]=>
bool(true)
[2]=>
bool(true)
}
بنابراین نتیجه همان است. حالا این RFC جدید پیشنهاد داده است که می گوید فرمول کلی این فرآیند باید به شکل start_index + 1 باشد و یک واحد یک واحد افزوده شود. با این حساب نتیجه کد بالا در PHP نسخه 8 به شکل زیر خواهد بود:
array(4) {
[-5]=>
bool(true)
[-4]=>
bool(true)
[-3]=>
bool(true)
[-2]=>
bool(true)
}
بنابراین اگر در کدهایتان از این موارد استفاده می کنید، حتما با بروزرسانی نسخه PHP، کدهای خود را نیز به روز رسانی کنید.
نسخه دوم Union types
به زبان ساده union type ها مقادیری را قبول می کنند که ممکن است از تایپ های مختلفی باشند. در حال حاضر PHP از union types پشتیبانی نمی کند (به استثنای دستور Type? و تایپ خاص iterable) بنابراین قبل از نسخه ی 8 زبان PHP، استفاده از union type ها به phpdoc annotation محدود بود. به طور مثال:
class Number {
/**
* @var int|float $number
*/
private $number;
/**
* @param int|float $number
*/
public function setNumber($number) {
$this->number = $number;
}
/**
* @return int|float
*/
public function getNumber() {
return $this->number;
}
}
اگر با phpdoc block آشنا نیستید (خطوط کامنت شده در بالا) می توانید به لینک زیر مراجعه کنید:
https://docs.phpdoc.org/latest/getting-started/your-first-set-of-documentation.html
البته به طور خلاصه می توان گفت که این doc block ها برای مشخص کردن هدف هر قسمت از کدهای شما هستند. حالا با RFC جدید برای union type ها می توانیم از signature متدها نیز از آن ها استفاده کنیم تا دیگر مجبور به استفاده از inline documentation (همان doc block های بالا) نباشیم بلکه از این به بعد از ساختار T1|T2 برای تعریف آن ها استفاده کنیم. مثال:
class Number {
private int|float $number;
public function setNumber(int|float $number): void {
$this->number = $number;
}
public function getNumber(): int|float {
return $this->number;
}
}
آقای Nikita Popov در این RFC می گوید:
“Supporting union types in the language allows us to move more type information from phpdoc into function signatures, with the usual advantages this brings:
- Types are actually enforced, so mistakes can be caught early.
- Because they are enforced, type information is less likely to become outdated or miss edge-cases.
- Types are checked during inheritance, enforcing the Liskov Substitution Principle.
- Types are available through Reflection.
- The syntax is a lot less boilerplate-y than phpdoc.”
ترجمه:
پشتیبانی از union types به ما کمک می کند تا اطلاعات بیشتری از type یک داده را از phpdoc به function signature منتقل کنیم تا از مزیت های آن بهره مند شویم:
- type ها اجباری می شوند بنابراین اشتباهات در همان ابتدا (در مراحل توسعه) مشخص می شوند.
- از آنجایی که type ها اجباری می شوند، اطلاعات type ها قدیمی نشده و در حالت های خاص نیز استفاده خواهد شد.
- type ها در هنگام ارث بری بررسی می شوند بنابراین از قانون Liskov Substitution پیروی خواهیم کرد.
- type ها از طریق reflection هم قابل دسترسی خواهند بود.
- نحو و قواعد نوشتن آن نیز نسبت به phpdoc کمتر به کدهای boilerplate (کدهای آماده و تکراری - در این مورد بیشتر مطالعه کنید) شباهت دارد.
با این حساب Union type ها از تمام type های داده پشتیبانی خواهند کرد، البته محدودیت هایی نیز وجود دارد:
- تایپ void نمی تواند قسمتی از union type ها باشد چرا که void به معنی برنگشتن هیچ مقداری از یک تابع است.
- تایپ null فقط در union type ها قابل استفاده است و نمی توان از آن به صورت مستقل استفاده کرد.
- استفاده از تایپ ?T (با نام nullable type شناخته می شود) به معنای T|null مجاز است اما اجازه نداریم که از خود ?T در union type استفاده کنیم. مثلا ?T1|T2 مجاز نیست و به جای آن باید از T1|T2|null استفاده کنیم.
- بسیاری از توابع در PHP می توانند مقدار False را برگردانند (مثل strops و strstr و substr و غیره) بنابراین استفاده از false نیز مجاز است.
اگر می خواهید در مورد union type ها بیشتر بدانید به لینک زیر مراجعه کنید:
https://wiki.php.net/rfc/union_types_v2
خطاهای یکسان بین توابع پیش فرض و توابع تعریف شده
در حال حاضر اگر پارامتری را که Type غیرمجاز دارد به یک تابع پاس بدهیم، بر اساس اینکه آن تابع internal باشد یا user-defined باشد، رفتار متفاوتی را خواهیم دید. منظور از توابع internal همان توابع built-in است؛ یعنی توابعی که به صورت پیش فرض در زبان PHP وجود دارد اما توابع User-defined توابعی هستند که توسط خود توسعه دهنده تعریف می شوند. مثال:
<?php
function foo($arg_1, $arg_2, /* ..., */ $arg_n)
{
echo "Example function.\n";
return $retval;
}
?>
ما در زبان PHP هیچ تابعی به نام foo نداریم بنابراین باید خودمان آن را به شکل بالا تعریف کنیم. مسئله اینجاست که اگر تابعی از ما پارامتر خاصی بخواهد (مثلا رشته ای) و ما چیزی غیر از آن را پاس بدهیم (مثلا یک عدد) شاهد رفتار زیر خواهیم بود:
- در توابعی که توسط توسعه دهنده تعریف می شوند، یک خطای TypeError می گیریم.
- در توابع پیش فرض بر اساس اینکه با چه تابعی سر و کار داریم، نتایج مختلفی می گیریم اما معمولا اینطور است که warning داده شده و null برگردانده می شود.
به طور مثال بیایید این کار را با یک تابع پیش فرض انجام بدهیم:
var_dump(strlen(new stdClass));
با اجرای کد بالا خطای زیر را می گیریم:
Warning: strlen() expects parameter 1 to be string, object given in /path/to/your/test.php on line 4 NULL
همچنین اگر strict_types را فعال کرده باشیم یا اگر اطلاعات آرگومان type را مشخص کرده باشد، شاهد رفتار دیگری خواهیم بود. در چنین سناریوهایی PHP متوجه خطای تایپ شده و یک TypeError می گیریم. این مسئله باعث مشکلات مختلفی می شود که در این قسمت از RFC توضیح داده شده اند. برای رفع این مشکل RFC جدید پیشنهاد می دهد که در صورتی که با چنین وضعیتی روبرو بودیم همیشه خطای ThrowError را دریافت کنیم. بنابراین در نسخه ی 8 زبان PHP کد بالا باعث خطای زیر خواهد شد:
Fatal error: Uncaught TypeError: strlen(): Argument #1 ($str) must be of type string, object given in /path/to/your/test.php:4
Stack trace:
#0 {main}
thrown in /path/to/your/test.php on line 4
دستور throw
در زبان PHP تقسیم بندی های مختلفی برای شناسایی کدها و دستورات وجود دارد که statement یکی از آن ها است. هر اسکریپت PHP از مجموعه ای از statement ها تشکیل شده است و هر statement می تواند یک عملیات انتساب، صدا زدن تابع، حلقه ها، عبارات شرطی و غیره باشد. اکثر Statement ها با علامت نقطه ویرگول (;) تمام می شوند. از طرفی یکی دیگر از واحدهای شناسایی کدهای PHP عبارت یا Expression ها هستند. documentation رسمی PHP می گوید بهترین و دقیق ترین تعریف برای Expression ها بدین صورت است: «هر چیزی که دارای مقداری باشد» بنابراین ساده ترین expression ها همان متغیرها و ثابت های PHP هستند. یکی از statement های معروف، throw است بنابراین نمی توانیم از آن در قسمت هایی از کد استفاده کنیم که نیاز به expression دارد.
یک RFC جدید پیشنهاد داده است که throw به یک expression تبدیل شود تا بتوانیم در همه جا از آن استفاده کنیم. به طور مثال در Arrow function ها و null coalesce operator ها و ternary and elvis operators ها و الی آخر. کد زیر از همین RFC آمده است:
$callable = fn() => throw new Exception(); // $value is non-nullable. $value = $nullableValue ?? throw new InvalidArgumentException(); // $value is truthy. $value = $falsableValue ?: throw new InvalidArgumentException();
در حالت نمی توانیم از throw new استفاده کنیم اما با نسخه جدید PHP می توانیم این کار را انجام بدهیم.
معرفی Weak Map ها
Weak Map ها مجموعه ای از داده ها (شیء ها) است که در آن key ها به شکل ضعیف به هم متصل هستند. اتصال ضعیف یعنی از Garbage collection در امان نیستند. برای درک این جمله باید با مفهوم garbage collection در زبان های برنامه نویسی آشنا شوید. کلمه garbage به معنی «آشغال» یا «ضایعه» و کلمه collection به معنی «جمع آوری» می باشد بنابراین garbage collection یعنی زباله روبی! اما این عبارت در زمینه برنامه نویسی معنی خاص خود را دارد و معادل بازیافت حافظه است. یعنی چه؟
زمانی که شما یک متغیر را تعریف می کنید، این متغیر در مموری سیستم جا می گیرد (زمانی که کدها اجرا شود) و در صورت نیاز تغییراتی روی آن اعمال می شود یا اطلاعاتی از آن خوانده می شود (بسته به اینکه چه کدهایی نوشته باشید) اما بالاخره اجرای برنامه شما متوقف می شود یا حداقل قسمتی از آن متوقف می شود. مثلا اگر از کلاس مشخصی یک نمونه یا شیء ساخته باشیم این شیء در مموری خواهد بود و فضای مموری را اشغال می کند تا زمانی که دیگر به آن نیاز نداشته باشیم. اگر نیاز ما به این شیء برطرف شد، باید آن را از مموری دور بیندازیم تا فضای مموری را خالی کنیم در غیر این صورت مموری ما آنقدر اشغال می شود که دیگر جایی برای چیزی نیست. به این فرآیند بازگردانی مموری GC یا garbage collection می گویند که به نوعی در تمام زبان های برنامه نویسی پیاده سازی شده است. در بعضی از زبان های low-level (زبان هایی که به machine code نزدیک تر هستند) عملیات GC توسط کتابخانه ها یا به صورت دستی و توسط خود توسعه دهنده انجام می شود. مثلا در زبان C توسعه دهنده باید با دو تابع ()malloc و ()dealloc خودش فضای مموری را به اشیاء مختلف اختصاص داه و خودش هم آن فضا را پس بگیرد اما در زبان هایی مانند جاوا اسکریپت تمام این عملیات به صورت خودکار انجام می شود.
در نسخه 7.4 زبان PHP قابلیتی به نام weak references ها ارائه شد. در کلاس WeakReference می توانیم یک ارجاع (reference) به یک شیء را حفظ کنیم البته به طوری که باعث جلوگیری از نابودی خود شیء نشود (یعنی جلوی عملیاتی مثل garbage collection یا حذف دستی شیء را نگیرد). شاید در ابتدا این توضیح کمی پیچیده باشد بنابراین بگذارید بیشتر توضیح بدهم. به مثال زیر توجه کنید:
$object = new stdClass; $weakRef = WeakReference::create($object); var_dump($weakRef->get()); unset($object); var_dump($weakRef->get());
در این مثال یک weak referece (ارجاع ضعیف) به متغیر object$ داریم. نتیجه اولین var_dump بالا به شکل زیر خواهد بود:
object(stdClass)#1 (0) {}
اما نتیجه var_dump دوم فقط NULL است چرا که شیء مرجوع از بین رفته است (به خاطر دستور unset). این کد بدون خطا و به همان صورتی که گفتم اجرا شده است. در حالت عادی اگر بین این دو، ارجاعی داشتیم چه اتفاقی می افتاد؟ ارجاع عادی جلوی نابودی شیء اول (متغیر object$) را می گرفت! استفاده از weak reference ها معمولا در ساختار های cache می باشد.
حالا به گفته آقای Nikita Popov قابلیت weak reference ها واقعا کاربرد چندانی ندارند اما weak map ها دارای پتانسیل کاربردی هستند. Popov می گوید نمی توانیم یک weak map بهینه را با weak reference ها پیاده سازی کنیم چرا که در weak reference ها قابلیت اضافه کردن یک callback برای حذف شیء را نداریم. به همین خاطر RFC جدید کلاس weakmap را اضافه کرده است تا بتوانیم اشیائی بسازیم که به عنوان کلیدهای weakmap استفاده شوند به طوری که جلوی نابودی چیزی را نگیرند و اگر reference دیگری به آن ها نداریم، کلید های شیء نابود شوند.
این قابلیت در فرآیند های سنگین و طولانی باعث جلوگیری از memory leak (فرآیندی که در آن برنامه ما قادر به رها سازی صحیح مموری و آزاد کردن آن برای استفاده نیست در حالی که اصلا به آن نیاز ندارد) و بهبود سرعت برنامه می شود. مثال زیر از RFC ذکر شده است:
$map = new WeakMap; $obj = new stdClass; $map[$obj] = 42; var_dump($map);
در نسخه 8 زبان PHP کد بالا نتیجه زیر را خواهد داشت:
object(WeakMap)#1 (1) {
[0]=>
array(2) {
["key"]=>
object(stdClass)#2 (0) {
}
["value"]=>
int(42)
}
}
در صورتی که می خواهید کد بالا را در عمل اجرا کنید به لینک https://3v4l.org/o6lZX/rfc#output بروید. حالا اگر شیء بالا را unset کنیم، کلید (key) به صورت خودکار از weak map حذف می شود:
unset($obj); var_dump($map);
پس از اجرای کد بالا (unset کردن شیء) نتیجه ما به شکل زیر خواهد بود:
object(WeakMap)#1 (0) {
}
این RFC با تمام آرا و بدون هیچ رای مخالفی تصویب شده است.
استفاده از Trailing Comma در لیست پارامترها
Trailing comma ها ویرگول (comma) هایی هستند که به لیست هایی از آیتم های مختلف اضافه می شوند و بسته به زمینه استفاده شده، اجازه پیوست شدن موارد بیشتری را می دهند. به طور مثال در نسخه 7.2 زبان PHP قابلیت اضافه کردن Trailing comma به آرایه ها و namespace های گروهی اضافه شد. به مثال زیر توجه کنید:
<?php $colors = [ 'blue', 'red', 'green', ];
اگر به عنصر آخر این آرایه نگاه کنید (green) یک ویرگول می بینید! شاید در ابتدا تصور کنید که این کد اشتباه است اما اینطور نیست! با اضافه کردن این ویرگول می توانیم با خیال راحت آرایه ها را با هم ادغام کنیم و دیگر نگران عنصر آخر و مشکلات آن نباشیم. سپس در نسخه 7.3 زبان PHP این قابلیت در صدا زدن توابع نیز مجاز شد. مثال:
<?php array_merge( $greenColors, $redColors, $yellowColors, );
حالا در نسخه 8 زبان PHP می توانیم از قابلیت trailing commas در لیست پارامترهای متدها و توابع و closure ها نیز استفاده کنیم! مثال:
class Foo {
public function __construct(
string $x,
int $y,
float $z, // trailing comma
) {
// do something
}
}
این پیشنهاد با 58 رای موافق و 1 رای مخالف تایید شده است.
استفاده از نحو class:: روی اشیاء
می دانیم که برای دریافت نام یک کلاس می توانیم از نحو Foo\Bar::class استفاده کنیم اما یک RFC جدید پیشنهاد می دهد که بتوانیم همین نحو را به اشیاء نیز بسط بدهیم تا بتوانیم نام کلاسِ یک شیء را نیز پیدا کنیم. به کد زیر توجه کنید:
$object = new stdClass; var_dump($object::class); // "stdClass" $object = null; var_dump($object::class); // TypeError
همانطور که می بینید ما از این نحو (syntax) روی اشیاء بالا استفاده کرده ایم. بنابراین در نسخه 8 زبان PHP استفاده از object::class$ برابر با استفاده از (get_class($object خواهد بود. همچنین اگر object$ یک شیء نباشد یک خطای TypeError به ما برگردانده می شود. این پیشنهاد بدون رای مخالف و با تمام آرا تصویب شد.
نسخه دوم attributes
ممکن است که با Attributes یا همان annotations در زبان های دیگر آشنا باشید. attributes نوعی از متادیتاهای ساختاریافته هستند که خصوصیات یک شیء یا عنصر یا فایل را مشخص می کنند. تا نسخه 7.4 زبان PHP تنها راه اضافه کردن متادیتا به کلاس ها و توابع و غیره استفاه از doc-comment یا همان Doc-block بود که در قسمت های قبلی به آن اشاره کرده بودیم. بگذارید برایتان مثالی بزنم. فرض کنید که می خواهیم این تابع را تعریف کنیم:
function add ($a, $b) {
return $a + $b;
}
حالا می خواهیم برای آن متادیتا (metadata - در اصطلاح یعنی داده هایی در مورد داده های ما!) بگذاریم، یعنی به صورت کامنت برای کسی که از این تابع استفاده می کند توضیح بدهیم که چه کار باید انجام بدهد. تابع بالا بسیار ساده است و نیازی به متادیتا ندارد اما برای روشن شدن موضوع این کار را می کنیم:
/** * Enter description here... * * @param unknown_type $a * @param unknown_type $b * @return unknown */
همانطور که می بینید doc-comment ها کامنت هایی هستند که شبیه به documentation می باشند و نحوه استفاده را توضیح می دهند. در مثال بالا باید به جای Enter description here، توضیحی در مورد تابع بنویسید. سپس param@ ها نوع یا تایپ پارامترها را مشخص می کنند و در نهایت return@ مشخص می کند که تابع ما چه چیزی را برمی گرداند (رشته یا عدد یا غیره).
حالا یک RFC جدید ثبت شده است که به ما اجازه می دهد از attributes ها برای تعریف متادیتا در کلاس ها و توابع استفاده کنیم. این attribute ها باید قبل از تعریف تابع یا کلاس نوشته شوند. به مثال زیر از این RFC توجه کنید:
<<ExampleAttribute>>
class Foo
{
<<ExampleAttribute>>
public const FOO = 'foo';
<<ExampleAttribute>>
public $x;
<<ExampleAttribute>>
public function foo(<<ExampleAttribute>> $bar) { }
}
$object = new <<ExampleAttribute>> class () { };
<<ExampleAttribute>>
function f1() { }
$f2 = <<ExampleAttribute>> function () { };
$f3 = <<ExampleAttribute>> fn () => 1;
البته شما می توانیم این attribute ها را با doc-comment ها ترکیب کنید:
<<ExampleAttribute>>
/** docblock */
<<AnotherExampleAttribute>>
function foo() {}
هر declaration ای (تعریف تابع یا کلاس یا غیره) می تواند یک یا چند مقدار مربوط داشته باشد:
<<WithoutArgument>>
<<SingleArgument(0)>>
<<FewArguments('Hello', 'World')>>
function foo() {}
یک مثال دیگر بدین شکل است:
class ProductSubscriber
{
<<ListensTo(ProductCreated::class)>>
public function onProductCreated(ProductCreated $event) { /* … */ }
<<ListensTo(ProductDeleted::class)>>
public function onProductDeleted(ProductDeleted $event) { /* … */ }
}
ما درون این attribute نوشته ایم ListensTo (یعنی گوش کن به) ProductCreated::class تا توضیح دهیم که کار این متد چیست. نوشتن این attribute ها نحو یا syntax خاص خودش را دارد بنابراین برای کسب اطلاعات بیشتر به RFC مربوطه مراجعه کنید:
https://wiki.php.net/rfc/attributes_v2
معرفی توابع جدید
نسخه 8 زبان PHP توابع جدیدی را معرفی کرده است که من چند مورد را بررسی می کنم. در حال حاضر برای پیدا کردن یک رشته در رشته ای دیگر باید از توابعی مانند strstr و strpos استفاده کنیم اما استفاده از آن ها اصلا راحت و ساده نیست و برای تازه کاران دردسرساز می شود. به مثال زیر توجه کنید:
$mystring = 'Managed WordPress Hosting';
$findme = 'WordPress';
$pos = strpos($mystring, $findme);
if ($pos !== false) {
echo "The string has been found";
} else {
echo "String not found";
}
همانطور که می بینید نحوه پیدا کردن findme$ در myString$ اصلا ساده نیست. همچنین در مثال بالا از ==! استفاده کرده ایم که تایپ دو مقدار را نیز مقایسه می کند که خودش باعث می شود در صورت برابر بودن موقعیت findme$ با صفر خطا دریافت نکنیم. به همین خاطر است که فریم ورک های PHP معمولا توابع کمکی را برای این موضوع ارائه می دهند. حالا یک RFC جدید تابع str_contains را ارائه داده است که استفاده از آن بسیار ساده تر است:
str_contains ( string $haystack , string $needle ) : bool
کد بالا چک می کند که آیا needle درون haystack می باشد یا خیر و بر همین اساس true یا false برمی گرداند. بنابراین کد بالا را می توانیم به شکل زیر بنویسیم:
$mystring = 'Managed WordPress Hosting';
$findme = 'WordPress';
if (str_contains($mystring, $findme)) {
echo "The string has been found";
} else {
echo "String not found";
}
در زمان نوشتن این مقاله RFC می گوید که str_contains نسبت به بزرگی و کوچکی حروف حساس است اما ممکن است این موضوع در آینده تغییر کند. این تابع با 43 رای موافق و 9 رای مخالف تصویب شده است.
همچنین دو تابع دیگر نیز داریم:
- str_starts_with: بررسی می کند که آیا یک رشته با مقدار خاصی آغاز شده است.
- str_ends_with: بررسی می کند که آیا یک رشته با مقدار خاصی تمام شده است.
مثال:
str_starts_with (string $haystack , string $needle) : bool str_ends_with (string $haystack , string $needle) : bool
به نظرم هر دو تابع واضح هستند و نیازی به توضیح اضافه ندارند. واضح است که اگر needle از haystack بزرگتر باشد، نتیجه false می شود. در زمان نوشتن این مقاله هر دو تابع case-sensitive (حساس به بزرگی و کوچکی حروف) هستند.
تابع بعدی get_debug_type است که به تابع قدیمی gettype شباهت دارد اما get_debug_type تایپ یک متغیر را به همراه نام کلاس آن مشخص می کند. به این مثال از gettype توجه کنید:
$bar = [1,2,3];
if (!($bar instanceof Foo)) {
throw new TypeError('Expected ' . Foo::class . ', got ' . (is_object($bar) ? get_class($bar) : gettype($bar)));
}
ما باید از is_object استفاده کنیم تا مطمئن شویم مقدار ما یک کلاس است یا غیر از کلاس اما با get_debug_type می توان گفت:
if (!($bar instanceof Foo)) {
throw new TypeError('Expected ' . Foo::class . ' got ' . get_debug_type($bar));
}
تفاوت های این دو را در جدول زیر مشاهده می کنید:
| مقدار مثالی | نتیجه در تابع ()gettype | نتیجه ر تابع ()get_debug_type |
| 1 | integer | int |
| 0.1 | double | float |
| true | boolean | bool |
| false | boolean | bool |
| null | NULL | null |
| "Roxo.ir" | string | string |
| [1,2,3] | array | array |
| کلاسی با نام Foo\Bar | object | Foo/Bar |
| یک کلاس anonymous | object | class@anonymous |
امیدوارم به خوبی با قابلیت های اصلی PHP 8 آشنا شده باشید. قابلیت های جزئی دیگری نیز وجود دارد که من آن ها را ذکر نمی کنم اما می توانید خودتان آن ها را پیدا کنید.
منبع: وب سایت kinsta









در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.
در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.
در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.
در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.
در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.
در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.
در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.
در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.