
SQL چیست؟
SQL یا Structured Query Language یک زبان دامنه ای خاص است که در برنامه نویسی استفاده می شود و برای مدیریت داده های موجود در یک RDBMS (relational database management system یا مدیریت پایگاه داده رابطه ای) یا RDSMS (relational data stream management system یا سیستم مدیریت جریان داده های رابطه ای) به کار می رود. این زبان یک زبان پرس و جوی ساختاریافته و یک زبان برنامه نویسی استاندارد شده است که برای مدیریت پایگاه داده های رابطه ای و انجام عملیات های مختلف بر روی داده های موجود در آن ها استفاده می شود. از این رو آموزش SQL اهمیت دارد.
این ویژگی SQL در مدیریت داده های ساخت یافته، یعنی داده هایی که روابط بین موجودیت ها و متغیرها را در بر می گیرد، مفید است. SQL دو مزیت اصلی نسبت به سایر API های خواندن/نوشتن قدیمیتر مانند ISAM یا VSAM دارد:
- مفهوم دسترسی داشتن به تعداد زیادی از رکوردها را با یک فرمان را معرفی می کند.
- نیاز به مشخص کردن چگونگی دستیابی به یک رکورد را از بین می برد، به عنوان مثال با اندیس یا بدون اندیس.
SQL که در اصل بر اساس جبر رابطهای و حساب رابطهای چندگانه استوار است، شامل انواع مختلفی از اصطلاح ها است، که ممکن است به عنوان زیرزبانها (sublanguages) طبقهبندی شوند، مانند:
- data query language (DQL) (یک زبان کوئری داده)
- data definition language (DDL) (یک زبان تعریف داده)
- data control language (DCL) (یک زبان تعریف داده)
- data manipulation language (DML) (زبان دستکاری داده ها)
دامنه SQL شامل پرس و جوی داده ها (data query)، دستکاری داده ها (درج، به روز رسانی و حذف)، تعریف داده ها (ایجاد و ویرایش schema ها) و کنترل دسترسی به داده ها است.
تاریخچه SQL
SQL در IBM توسط Donald D. Chamberlin و Raymond F. Boyce در اوایل دهه 1970 توسعه یافت. این نسخه که در ابتدا زبان پرس و جوی ساختاریافته نام داشت، برای دستکاری و بازیابی داده های ذخیره شده در سیستم مدیریت پایگاه داده شبه رابطه ای اصلی IBM و System R، که گروهی در آزمایشگاه تحقیقاتی IBM San Jose در طول دهه 1970 توسعه داده بودند، طراحی شد.
پس از آزمایش SQL در سایتهای آزمایشی ویژه مشتریان برای تعیین سودمندی و کاربردی بودن سیستم، IBM شروع به توسعه محصولات تجاری بر اساس نمونه اولیه System R خود، از جمله System/38، SQL/DS و DB2 کرد که در سالهای 1979، 1981 به صورت تجاری در دسترس قرار گرفت.
اگرچه SQL یک استاندارد ANSI/ISO است، اما نسخه های مختلفی از زبان SQL وجود دارد. با این حال، برای انطباق با استاندارد ANSI، همه آن ها حداقل از دستورات اصلی مانند SELECT ،UPDATE ،DELETE ،INSERT ،WHERE به روشی مشابه پشتیبانی می کنند.
تا سال 1986، گروه های استاندارد ANSI و ISO به طور رسمی تعریف زبان استاندارد SQL را پذیرفتند. نسخه های جدید استاندارد شده در سال های 1989، 1992، 1996، 1999، 2003، 2006، 2008، 2011 و اخیرا در سال 2016 منتشر شدند.
SQL چگونه کار میکند؟
SQL حجم زیادی از داده ها را مدیریت می کند، به خصوص اگر داده های زیادی وجود داشته باشد که به طور همزمان نوشته می شوند و تراکنش های داده بسیار زیاد باشد.
نسخه ها و فریمورک های مختلفی برای SQL وجود دارد که رایج ترین آن ها MySQL است. MySQL یک راه حل منبع باز است که به تسهیل نقش SQL در مدیریت داده های back-end برای برنامه های کاربردی وب کمک می کند.
شرکت هایی مانند فیس بوک، اینستاگرام، واتس اپ و غیره همگی از SQL برای ذخیره سازی داده ها و راه حل های پردازش داده ها استفاده می کنند. هنگامی که یک کوئری SQL نوشته و اجرا می شود (یا تجزیه می شود)، توسط یک بهینه ساز کوئری پردازش می شود. کوئری به سرور SQL فرستاده می شود و سپس در سه مرحله کامپایل می شود: تجزیه، اتصال و بهینه سازی.
- تجزیه (parsing): فرآیندی برای بررسی سینتکس
- اتصال (Binding): فرآیندی برای بررسی معنای کوئری
- بهینه سازی (Optimisation): فرآیندی برای تولید روش اجرای کوئری
در مرحله سوم، همه جایگشت ها و ترکیب های ممکن برای یافتن موثرترین روش اجرای کوئری در یک زمان معقول ایجاد می شوند. هرچه کوئری کوتاه تر باشد، بهتر است.
دستور زبان
زبان SQL به چندین عنصر زبانی تقسیم می شود که عبارتند از:
- Clauses: بندهایی که اجزای تشکیل دهنده عبارت ها و کوئری ها هستند. (در برخی موارد، این بندها اختیاری هستند)
- Expressions: عباراتی که می توانند مقادیر اسکالر یا جدول هایی متشکل از ستون ها و سطر ها را تولید کنند.
- Predicates: شرایطی را مشخص میکند که میتواند با منطق سه مقداری SQL (three-valued logic (3VL)) یعنی درست/نادرست/ناشناخته یا مقادیر بولی ارزیابی شوند و برای محدود کردن اثرات عبارت ها و کوئری ها یا تغییر جریان برنامه استفاده شوند.
- Queries: داده ها را بر اساس معیارهای خاص بازیابی می کنند. کوئری ها یک عنصر مهم از SQL هستند.
- Statements: بیانیههایی که ممکن است تاثیر دائمی روی schema ها و دادهها داشته باشند یا ممکن است تراکنشها، جریان برنامه، اتصالات، سشن ها یا تشخیصها را کنترل کنند.
- دستورات SQL همچنین شامل نقطه ویرگول (";") پایان دهنده عبارت هستند. اگرچه در هر پلتفرمی مورد نیاز نیست، اما به عنوان بخشی استاندارد از دستور زبان SQL تعریف شده اند.
- فضای خالی ناچیز به طور کلی در عبارات و پرس و جوهای SQL نادیده گرفته می شود و قالب بندی کد SQL را برای خوانایی آسان تر می کند.
مهم ترین دستورهای SQL
- SELECT: داده ها را از پایگاه داده استخراج می کند.
- UPDATE: داده ها را در پایگاه داده به روز می کند.
- DELETE: داده ها را از پایگاه داده حذف می کند.
- INSERT INTO: داده های جدید را در پایگاه داده وارد می کند.
- CREATE DATABASE: یک پایگاه داده جدید ایجاد می کند.
- ALTER DATABASE: یک پایگاه داده را تغییر می دهد.
- CREATE TABLE: یک جدول جدید ایجاد می کند.
- ALTER TABLE: یک جدول را تغییر می دهد.
- DROP TABLE: یک جدول را حذف می کند.
- CREATE INDEX: یک اندیس ایجاد می کند (کلید جستجو).
- DROP INDEX: یک اندیس را حذف می کند.
نکته: کلمات کلیدی SQL به حروف بزرگ و کوچک حساس نیستند.
انواع داده های SQL
استاندارد SQL سه نوع نوع داده را تعریف می کند:
- انواع داده های از پیش تعریف شده
- انواع ساخته شده
- انواع تعریف شده توسط کاربر
انواع ساخته شده ARRAY، MULTISET، REF(erence) یا ROW هستند. انواع تعریفشده توسط کاربر با کلاسهای زبان های شیگرا، observer ها، جهشدهندهها، متدها، وراثت، overloading، رونویسی، رابطها و غیره قابل مقایسه هستند.
انواع داده های از پیش تعریف شده
- انواع کاراکترها
- Character (CHAR)
- Character varying (VARCHAR)
- Character large object (CLOB)
- انواع کاراکترهای National
- National character (NCHAR)
- National character varying (NCHAR VARYING)
- National character large object (NCLOB)
- انواع باینری
- Binary (BINARY)
- Binary varying (VARBINARY)
- Binary large object (BLOB)
- انواع عددی
- Exact numeric types (NUMERIC, DECIMAL, SMALLINT, INTEGER, BIGINT)
- Approximate numeric types (FLOAT, REAL, DOUBLE PRECISION)
- Decimal floating-point type (DECFLOAT)
- Datetime types (DATE, TIME, TIMESTAMP) یا انواع زمانی
- Interval type (INTERVAL)
- Boolean
- XML
- JSON
SQL چه کاری می تواند انجام دهد؟
- SQL می تواند کوئری ها را در پایگاه داده اجرا کند.
- SQL می تواند داده ها را از پایگاه داده بازیابی کند.
- SQL می تواند رکوردها را در پایگاه داده وارد کند.
- SQL می تواند رکوردهای موجود در پایگاه داده را به روز کند.
- SQL می تواند رکوردها را از پایگاه داده حذف کند.
- SQL می تواند پایگاه داده جدیدی ایجاد کند.
- SQL می تواند جدول جدید در پایگاه داده ایجاد کند.
- SQL می تواند رویه های ذخیره شده را در یک پایگاه داده ایجاد کند.
- SQL می تواند View (نماها) را در پایگاه داده ایجاد کند.
- SQL می تواند مجوزها را روی جدول ها، رویه ها و نماها تنظیم کند.
افزونه های رویه ای
SQL برای یک هدف خاص طراحی شده است: پرس و جو یا کوئری از داده های موجود در یک پایگاه داده رابطه ای. SQL یک زبان برنامه نویسی مبتنی بر مجموعه و تعریفی است، نه یک زبان برنامه نویسی مانند C یا BASIC. با این حال می توان با افزودن extension ها به SQL قابلیتهای زبان های برنامهنویسی رویهای، مانند ساختارهای کنترل جریان را به آن اضافه کنیم.
علاوه بر پسوندهای استاندارد SQL/PSM و پسوندهای اختصاصی SQL، قابلیت برنامهریزی رویهای و شی گرا در بسیاری از پلتفرمهای SQL از طریق یکپارچهسازی DBMS با زبانهای دیگر در دسترس است. استاندارد SQL پسوندهای SQL/JRT را برای پشتیبانی از کد جاوا در پایگاههای داده SQL تعریف میکند. Microsoft SQL Server 2005 از SQLCLR (SQL Server Common Language Runtime) برای میزبانی دات NET مدیریت شده در پایگاه داده استفاده می کند.
View ها
یک view یک مجموعه نتایج SQL است که در پایگاه داده همراه با یک برچسب ذخیره می شوند، بنابراین می توانید بعدا بدون نیاز به اجرای دوباره کوئری به آن بازگردید. viewها زمانی مفید هستند که یک کوئری SQL پرهزینه و سنگین داشته باشید. بنابراین به جای این که کوئری را بارها و بارها اجرا کنید تا مجموعه نتایج یکسانی ایجاد کند، میتوانید فقط یک بار این کار را انجام دهید و آن را به عنوان view ذخیره کنید. دستور کلی استفاده از آن به شکل زیر است:
CREATE VIEW view_name AS SELECT column1, column2..... FROM table_name WHERE condition; view_name: Name for the View table_name: Name of the table condition: Condition to select rows
کلیدهای اصلی (Primary) و خارجی (Foreign)
معمولا در یک پایگاه داده رابطهای، دادهها در جداول مختلفی که از ویژگیها (ستونها) و رکوردها (سطرها) ساخته شدهاند، سازماندهی میشوند. در هر جدول یک ستون وجود دارد که نشان دهنده کلید اصلی است. هر ورودی نشان دهنده یک سطر در آن جدول است. این ستون معمولا ID است. ستونی در جدول که از طریق مقادیر مشترک با کلید اصلی جدول دیگر ارتباط برقرار می کند، کلید خارجی نامیده می شود. کلیدهای خارجی نیز معمولا دارای عنوان id هستند اما با نام جدول ارجاع شده اضافه می شوند.
این مفهوم هنگام ترکیب دو یا چند جدول با استفاده از JOIN اعمال می شود. در مثال زیر دو جدول داریم: جدول User (جدول 1) و جدول Event (جدول 2). میخواهیم این دو جدول را به هم متصل کنیم تا دادههای user را در کنار دادههای event آنها دریافت کنیم.
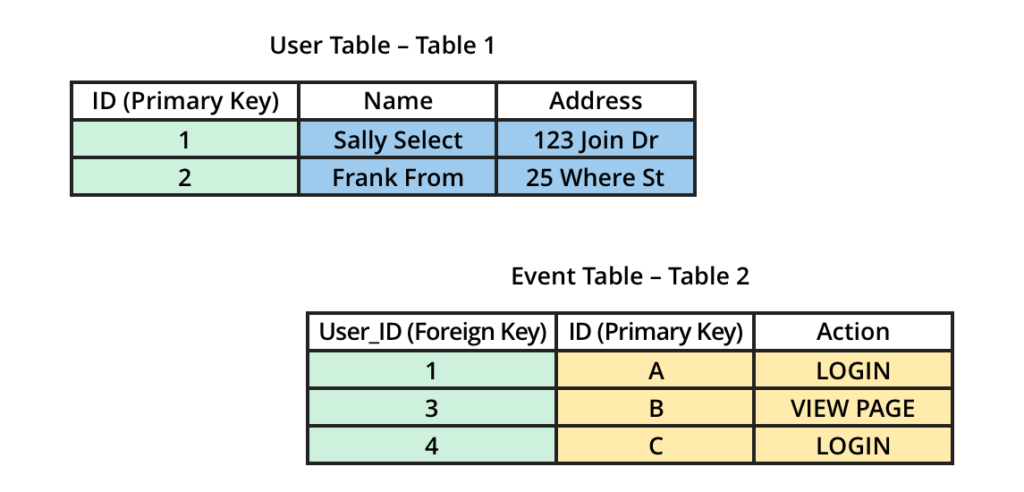
توجه کنید که در هر دو جدول یک ستون مشترک وجود دارد که با رنگ آبی مشخص شده است. در جدول User، ستون ID ،ID کاربر و کلید اصلی آن جدول است، در حالی که، در جدول Event، ستون User_ID کلید خارجی است زیرا این ستون به ستون ID در جدول User ها اشاره دارد. می توانیم از این رابطه برای پیوستن دو جدول به یکدیگر استفاده کنیم تا اطلاعات user ها و event ها را در یک جدول به دست آوریم.
JOIN (اتصال) جدول ها
همان طور که می دانیم داده های جدول، مهم ترین بخش هر پایگاه داده SQL است. برای استفاده موثر از آن، مدیران پایگاه داده باید به طور منظم رکوردها را از چندین جدول بر اساس شرایط خاص استخراج کنند و در صورت لزوم ترکیب کنند. SQL JOIN دقیقا برای همین است.
JOIN یک عبارت SQL است که برای بازیابی داده ها از دو یا چند جدول بر اساس روابط منطقی بین جدول ها استفاده می شود. JOIN ها نشان می دهد که چگونه SQL باید از داده های یک جدول برای انتخاب سطر های جدول دیگر استفاده کند.
انواع مختلف JOIN در SQL
SQL Server از انواع مختلف JOIN از جمله JOIN INNER، SELF JOIN، CROSS JOIN و OUTER JOIN پشتیبانی می کند. در واقع، هر نوع اتصال، نحوه ارتباط دو جدول را در یک کوئری تعریف می کند. اتصال بیرونی (OUTER JOIN) به نوبه خود می توانند به اتصال بیرونی چپ (LEFT OUTER JOINS)، اتصال بیرونی راست (RIGHT OUTER JOINS) و اتصال بیرونی کامل (FULL OUTER JOINS) تقسیم شوند. برای نشان دادن بهتر نحوه عملکرد JOIN ها، دو جدول ایجاد می کنیم.
CREATE TABLE AdventureWorks2019.dbo.users ( auid INT IDENTITY ,username VARCHAR(50) NOT NULL ,password VARCHAR(50) NOT NULL ,createdate DATETIME NOT NULL ,isActive TINYINT NOT NULL ); CREATE TABLE AdventureWorks2019.dbo.userprofile ( apid INT NOT NULL ,auid INT NOT NULL ,firstname VARCHAR(50) NOT NULL ,lastname VARCHAR(50) NOT NULL ,email VARCHAR(100) NOT NULL ,phone VARCHAR(45) NOT NULL );
در مرحله بعد باید داده ها را در جدول های ایجاد شده درج کنیم.
USE AdventureWorks2019 GO Insert into dbo.users (auid, username,password, createdate, isActive) values (1,'admin','pswrd123', GETDATE(), 1); Insert into dbo.userprofile (apid, auid, firstname, lastname, email, phone) values (1,1,'Jack', 'Wolf', 'bettestroom@gmail.com','600075764216'); Insert into dbo.users (auid,username,password, createdate, isActive) values (2, 'admin1','pass506', GETDATE(), 1); Insert into dbo.userprofile (apid, auid, firstname, lastname, email, phone) values (2, 3, 'Tom', 'Collins', 'tnkc@outlook.com','878511311054'); Insert into dbo.users (auid, username,password, createdate, isActive) values (4,'fox12','45@jgo0', GETDATE(), 1); Insert into userprofile (apid, auid, firstname, lastname, email, phone) values (4,5,'Bill', 'Fonskin', 'bill_1290@gmail.com','450985764216'); Insert into dbo.users (auid,username,password, createdate, isActive) values (6, 'lexus1267','98hnfRT6', GETDATE(), 1); Insert into dbo.userprofile (apid, auid, firstname, lastname, email, phone) values (7, 7, 'John', 'Hopkins', 'john_hompkins@mailchimp.com','878511311054');
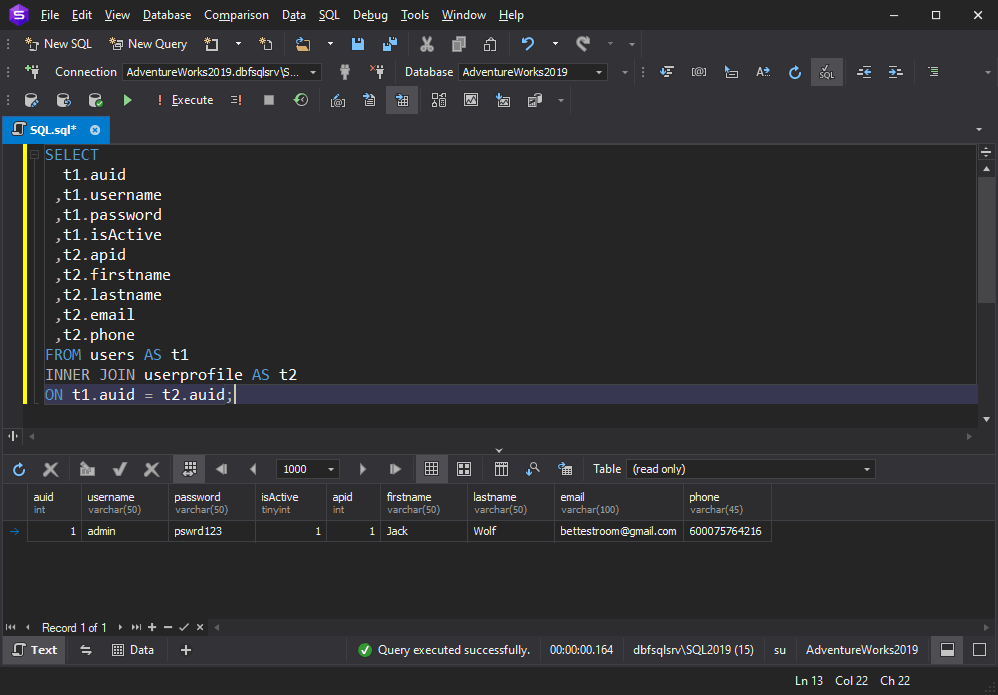
SQL INNER JOIN
عبارت INNER JOIN رکوردهایی را برمی گرداند که دارای مقادیر منطبق در هر دو جدول باشند.

سینتکس INNER JOIN به صورت زیر است:
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
SQL OUTER JOIN
برخلاف OUTTER JOIN ،INNER JOIN نه تنها رکوردهای منطبق، بلکه موارد غیرمنطبق را نیز برمی گرداند. در صورت وجود سطرهای غیر منطبق در جدولی که از اتصال جدول های پیشین به دست آمده، مقادیر NULL برای آن ها نشان داده می شود. دو نوع OUTER JOIN در SQL Server وجود دارد: SQL LEFT JOIN و SQL RIGHT JOIN. بیایید نگاهی دقیق تر به هر یک از آن ها بیندازیم.
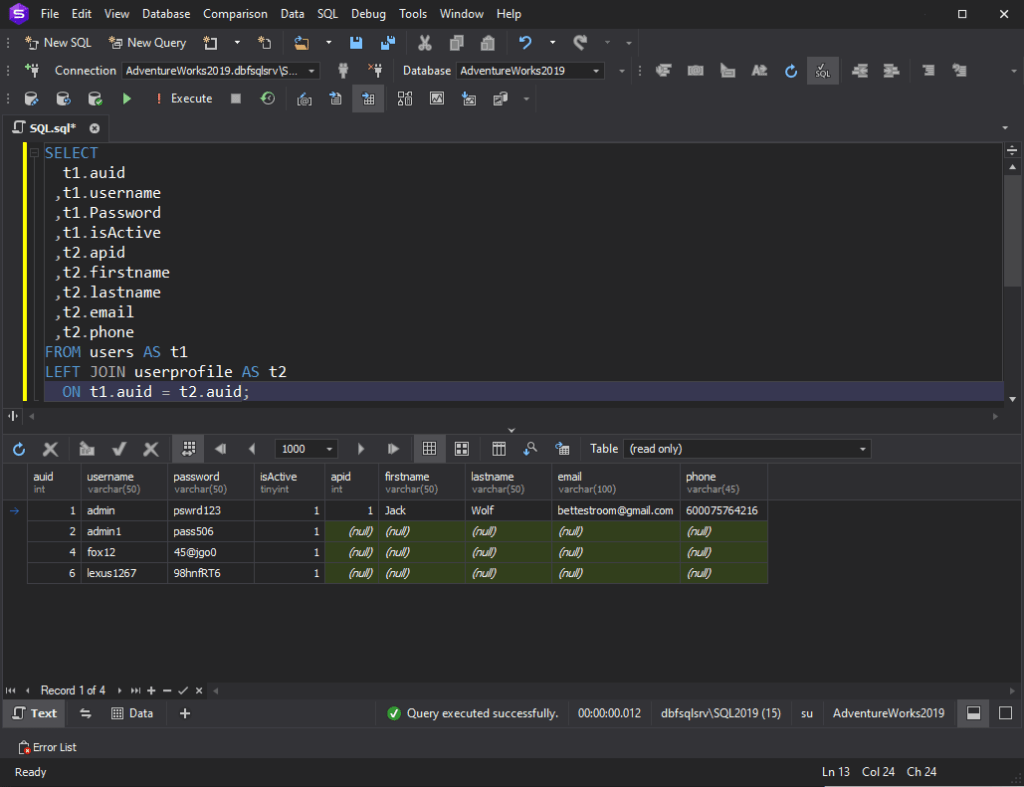
SQL LEFT JOIN
SQL LEFT JOIN همه رکوردها را از جدول سمت چپ (جدول A) و رکوردهای منطبق از جدول سمت راست (جدول B) را برمی گرداند. در صورت عدم تطابق، 0 رکورد از سمت جدول راست خواهیم داشت.
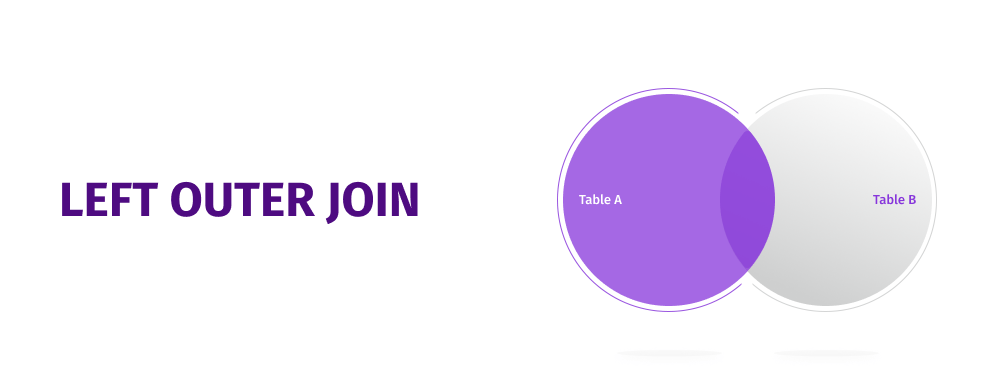
سینتکس عبارت SQL LEFT JOIN به شرح زیر است:
SELECT column_name(s) FROM tableA LEFT JOIN tableB ON tableA.column_name = tableB.column_nam
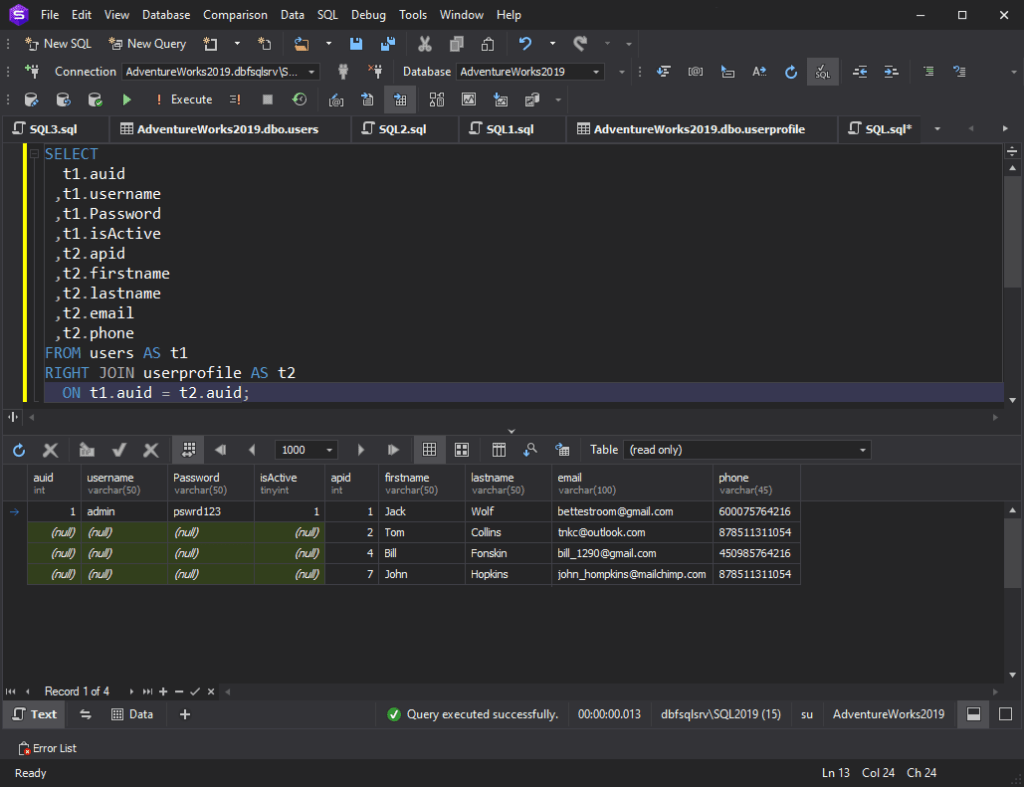
SQL RIGHT JOIN
کلمه کلیدی RIGHT JOIN همه رکوردها را از جدول سمت راست (جدول 2) و رکوردهای منطبق را از جدول سمت چپ (جدول 1) برمی گرداند. در صورت عدم تطابق، 0 رکورد از سمت چپ خواهیم داشت.

سینتکس عبارت SQL RIGHT JOIN به شرح زیر است:
SELECT column_name(s) FROM tableA RIGHT JOIN tableB ON tableA.column_name = tableB.column_name;
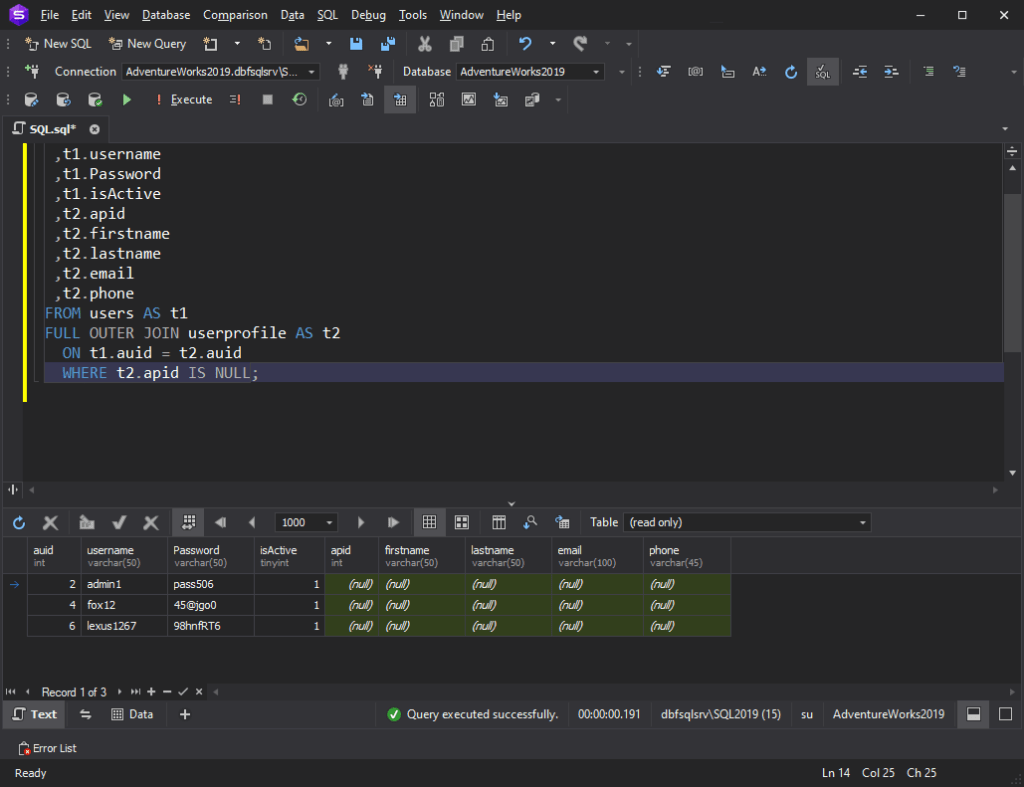
SQL FULL OUTER JOIN
FULL OUTER JOIN همه رکوردها را زمانی که یک تطابق در رکوردهای جدول چپ (جدول A) یا راست (جدول B) وجود دارد، برمی گرداند.

سینتکس عبارت SQL FULL OUTER JOIN به شرح زیر است:
SELECT column_name(s) FROM tableA FULL OUTER JOIN tableB ON tableA.column_name = tableB.column_name WHERE condition;
SQL CROSS JOIN
SQL CROSS JOIN، هم چنین به عنوان JOIN دکارتی شناخته می شود. این نوع از JOIN تمام ترکیب سطر ها را از هر جدول بازیابی می کند. در این نوع JOIN، در صورت عدم ارائه شرط اضافی، با ضرب دکارتی هر سطر از جدول A در تمام سطر های جدول B، مجموعه نتیجه برگردانده می شود.برای درک بهتر CROSS JOIN، بیایید نگاهی به نمودار زیر بیاندازیم.
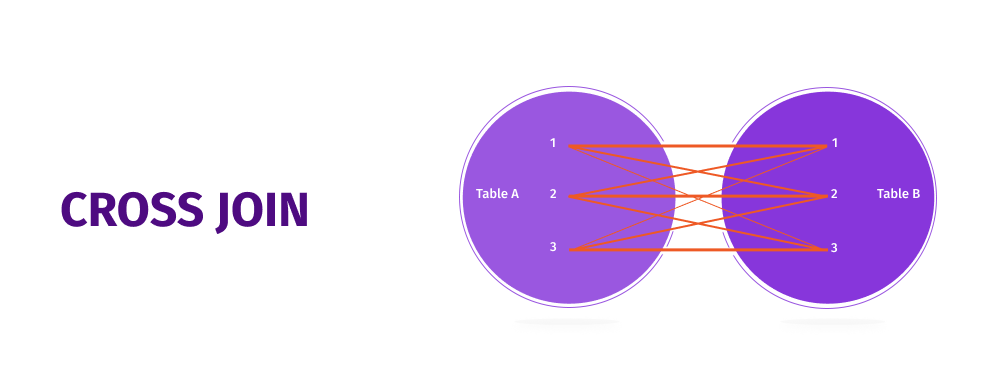
سینتکس SQL CROSS JOIN به شرح زیر است:
SELECT * FROM tableA CROSS JOIN tableB;
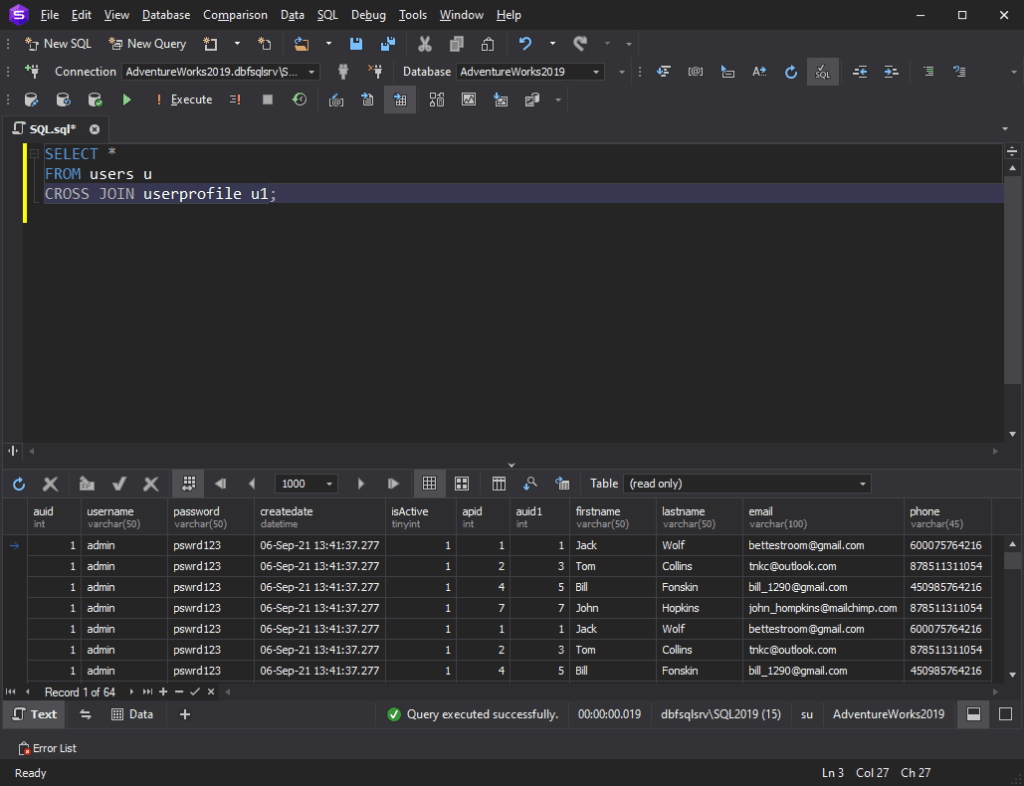
SQL Self JoIN
Self JoIN یک JOIN معمولی است، اما جدول با خودش پیوند میخورد. این به این معنی است که هر سطر از جدول با خودش و سپس با هر سطر دیگر از جدول ترکیب می شود.
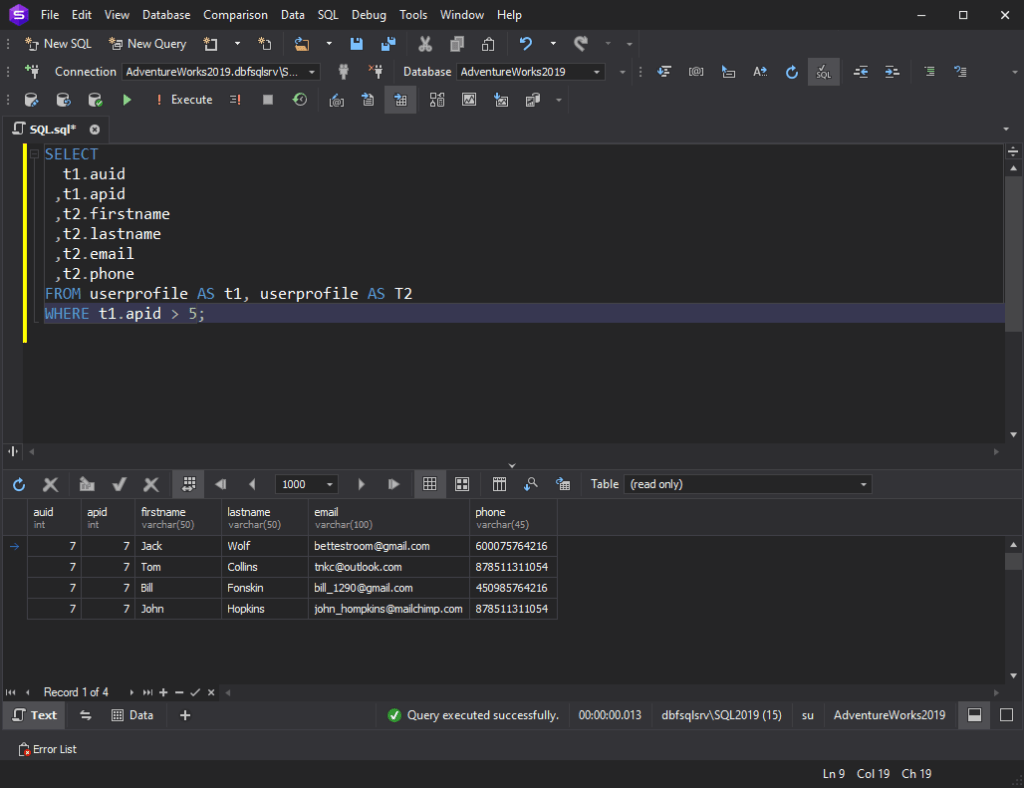
سینتکس SQL self JOIN به شرح زیر است:
SELECT column_name(s) FROM table1 T1, table1 T2 WHERE condition;
کاربردهای SQL
همان طور در پیش گفته شد، SQL یکی از پرکاربردترین زبان های کوئری در پایگاه های داده است. من قصد دارم در زیر تعدادی از کاربردهای SQL را بیاورم:
- به کاربران امکان دسترسی به داده ها در سیستم های مدیریت پایگاه داده رابطه ای را می دهد.
- به کاربران امکان می دهد داده ها را توصیف کنند.
- به کاربران اجازه می دهد تا داده ها را در پایگاه داده تعریف کرده و آن داده ها را دستکاری کنند.
- با استفاده از ماژولهای SQL، کتابخانهها و پیشکامپایلرها، امکان جاسازی در زبانهای دیگر را میدهد.
- به کاربران اجازه می دهد تا پایگاه داده ها و جدول ها را ایجاد و پاک کنند.
- به کاربران اجازه می دهد تا View، رویه های ذخیره شده و توابع را در پایگاه داده ایجاد کنند.
- به کاربران اجازه می دهد تا مجوزها را روی جدول ها، رویه ها و View ها تنظیم کنند.
انتقادها
طراحی
SQL به طرق مختلف از مبانی نظری خود، مدل رابطه ای و حساب چندگانه منحرف می شود. در مبانی SQL، یک جدول مجموعه ای از تاپل ها است، در حالی که SQL در عمل، جدول ها و نتایج کوئری لیستی از سطر ها هستند. یک سطر ممکن است چندین بار تکرار شود (به عنوان در عبارت LIMIT). منتقدان باور دارند که SQL باید با زبانی جایگزین شود که کاملا به اصول خود پایبند است.
کامل بودن
مشخصات اولیه SQL از ویژگی های اصلی مانند کلیدهای اصلی پشتیبانی نمی کرد. مجموعه نتایج را نمیتوانستیم نامگذاری کنیم و زیر کوئری ها نیز تعریف نشده بودند. این توانمندی ها در سال 1992 اضافه شدند. نبود sum types مانعی برای استفاده کامل از انواع تعریف شده توسط کاربر SQL تعریف شده است. برای مثال، پشتیبانی از JSON با استاندارد جدیدی در سال 2016 تعریف شد.
Null
مفهوم Null یا تهی بحث برانگیز است. Null نبودن یک مقدار را نشان می دهد و با اعداد صحیح یا یک رشته خالی فرق می کند. مفهوم Null منطق 3 ارزشی را در SQL اعمال می کند، که یک پیاده سازی ویژه از منطق کلی 3 ارزشی است.
آیتم های تکراری
یکی دیگر از انتقاداتی که به SQL می شود این است که اجازه میدهد سطر های تکراری وجود داشته باشند. هم چنین در یکپارچهسازی با زبانهایی مانند پایتون مشکلاتی را ایجاد می کند.معمولا با تعریف یک کلید اصلی یا استفاده از یک محدودیت به نامunique در یک یا چند ستون، این مشکل حل می شود.
عدم تطابق امپدانس
عدم تطابق امپدانس شی-رابطه ای، عدم تطابق بین زبان SQL تعریفی و زبان های رویه ای که SQL معمولا در آن ها تعبیه شده است رخ می دهد.












