آشنایی با کتابخانه Pandas در پایتون
Pandas Library

سلام و خسته نباشید به دانشجویان گرامی روکسو! این مقاله، پیش زمینه ای برای ورود به کار با کتابخانه پانداس در پایتون می باشد و می توانید با مطالعه آن مفاهیم کلی آن را یاد بگیرید. باید در نظر داشته باشید که این مقاله یک دوره کامل محسوب نمی شود، بلکه فقط پیش زمینه شروع کار شما است.
آشنایی با کتابخانه پانداس در پایتون
کتابخانه pandas کتابخانه ای بسیار بزرگ و محبوب برای زبان پایتون است. این کتابخانه مهم ترین ابزار تحلیل گران داده و data science می باشد اما در عین حال می تواند استفاده های زیادی برای افراد عادی نیز داشته باشد. اگر می خواهید وارد حوزه علوم داده و تحلیل آن شوید، یادگیری pandas یک امر ضروری است و امکان ندارد که بتوانید از یادگیری آن سر باز بزنید. همچنین اگر شما در فضای تحلیل داده فعالیت نمی کنید و به عنوان یک توسعه دهنده عادی پایتون نیاز به استفاده از pandas دارید، این مقاله به شما کمک بزرگی خواهد کرد.

کاربردهای کتابخانه Pandas چیست؟
کاربردهای مختلف کتابخانه پانداس در پایتون آنچنان زیاد است که لیست کردن ناتوانی هایش بسیار راحت تر از لیست کردن توانایی هایش می باشد! شما می توانید با استفاده از کتابخانه پانداس در پایتون داده های خود را تمیز کرده و مرتب کنید. این ابزار با ابزارهای مشهور دیگر مانند matplotlib نیز کار می کند تا بتواند data visualization (بصری سازی داده) را نیز انجام دهد.
به طور مثال فرض کنید که می خواهید داده های ذخیره شده در یک فایل CSV را تحلیل کنید. pandas داده های درون این فایل CSV را خوانده و به صورت یک DataFrame در می آورد که در عمل یک جدول است و سپس به شما اجازه می دهد عملیات مختلفی را روی آن انجام دهید:
- انجام محاسبات آماری روی داده ها مانند محاسبه بزرگترین و کوچکترین مقدار، محاسبه میانگین داده ها، محاسبه صدک ها و الی آخر.
- نگاهی به نحوه توزیع داده ها در یک ستون
- بررسی احتمال وابسته بودن ستون ها به یکدیگر
- پاک سازی داده ها: مثلا حذف کردن ردیف هایی که مقادیر ناقص دارند و یا حذف کامل بخش هایی که مقداری ندارند و خالی هستند، یا مرتب سازی یا فیلتر کردن ستون های خاص بر اساس شرط هایی خاص و الی آخر.
- همکاری با پکیج های بزرگ دیگر مانند Matplotlib برای بصری سازی داده ها: تولید نمودار های مختلف، هیستوگرام ها و الی آخر.
- ذخیره سازی داده های پاک سازی شده در یک فایل (CSV یا Excel و ...)
قبل از اینکه بخواهید دوره های یادگیری کتابخانه پانداس در پایتون را بگذرانید و وارد مباحث پیشرفته شوید، باید درک صحیحی از ساختار pandas و data frame های آن داشته باشید تا بدانید pandas چطور کار می کند و چه نگاهی به داده ها دارد.
جایگاه کتابخانه pandas در علوم داده
کتابخانه پانداس در پایتون نقشی اساسی و بزرگ در حوزه علوم داده دارد. pandas در اصل روی پکیج NumPy ساخته شده است بنابراین بسیاری از ساختارهای NumPy در pandas نیز تکرار شده اند. داده های تولید شده یا محاسبه شده در pandas معمولا به پکیج هایی مانند SciPy پاس داده می شوند تا تحلیل های آماری پیشرفته تر روی آن ها انجام شود. همچنین این داده ها معمولا به کتابخانه هایی مانند Matplotlib پاس داده می شوند که به data visualization (بصری سازی داده ها) کمک می کنند و نهایتا با پکیج هایی مانند Scikit-learn داده ها را به الگوریتم های یادگیری ماشینی پاس می دهیم تا به سراغ مبحث یادگیری ماشینی یا machine learning برویم.

معمولا برای استفاده پیشرفته از pandas آن را درون Jupyter Notebooks استفاده می کنند اما شما می توانید از ویرایشگرهای معمولی مانند visual studio code نیز برای میزبانی pandas استفاده کنید. تفاوت ویرایشگرهای عادی کد مانند visual studio code با Jupyter Notebooks در این است که ویرایشگرهای کد معمولا کدهای شما را در واحد فایل اجرا می کنند، یعنی به محض نوشتن و اجرای یک کد پایتون در یک فایل، کل آن کد توسط ویرایشگر اجرا خواهد شد. این در حالی است که Jupyter Notebooks می توانند کدهای شما را به بخش های مختلفی تقسیم کرده و اجرای آن را در سطح این بخش ها انجام بدهند.
شاید در نگاه اول متوجه مزیت تقسیم کد به قسمت های مختلف نشوید اما اگر خوب به کاربرد کتابخانه پانداس در پایتون فکر کنید متوجه خواهید شد که چرا اجرای کد در بخش های مختلف و کوچکتر برای ما کاربردی است. pandas با داده ها کار می کند و در زمینه تحلیل آن ها فعالیت دارد و این داده ها معمولا صد یا دویست ردیف نیستند! اگر داده های ما در این حد محدود بودند اصلا نیازی به استفاده از ابزار های آماری سنگین نبود بلکه می توانستیم خودمان با کاغذ و خودکار تحلیل های آماری را روی آن انجام بدهیم. داده هایی که سر و کارشان با pandas است معمولا صد ها هزار یا میلیون ها ردیف داده هستند و حجم عظیمی دارند. طبیعتا انجام عملیات مختلف روی این داده ها زمان زیادی خواهد برد بنابراین اگر بخواهیم تمام کار ها را به صورت یکجا روی داده ها انجام بدهیم ممکن است سیستم ما crash یا هنگ کند. Jupyter Notebooks با تقسیم کردن بار کاری روی بخش های مختلف، از این مشکل جلوگیری می کنند و زمان انجام عملیات را کاهش می دهند. علاوه بر این Jupyter Notebooks کار بصری سازی داده ها را بسیار ساده تر می کنند و دائما داده های ما را در وضعیت های مختلف به ما نشان می دهند.
چه زمانی از کتابخانه پانداس استفاده کنم؟
در صورتی که با زبان پایتون آشنا نیستید نباید به هیچ عنوان به سراغ کتابخانه پانداس در پایتون (pandas) بروید چرا که فقط خودتان را سردرگم می کنید. البته برای کار با pandas نیاز به یادگیری پایتون در سطح مهندسین نرم افزار ندارید اما باید آشنایی متوسطی با پایتون داشته باشید؛ مثلا انواع داده های tuple یا dictionary و غیره یا آشنایی با مفاهیم توابع و حلقه ها و گردش بین داده ها و امثال آن. آشنایی با این مباحث و داشتن پایه ای نسبتا خوب از برنامه نویسی با پایتون به شما کمک بزرگی در استفاده از pandas می کند. همچنین به دلیل توضیحاتی که دادم، پیشنهاد می شود با کتابخانه NumPy نیز آشنا شوید اما این فقط یک توصیه بوده و اجباری نیست.
نحوه نصب کتابخانه پانداس در پایتون
نصب کتابخانه پانداس در پایتون بسیار ساده و راحت است. برای انجام این کار ابتدا مطمئن باشید که پایتون روی سیستم شما نصب شده است. برای اطمینان از این موضوع به روش زیر عمل کنید.
کاربران مک و لینوکس: ترمینال خود را باز کرده و دستور python یا python3 را در آن اجرا کنید. این دستور شما را وارد shell می کند که در آن می توانید کدهای python بنویسید (دستور ورود در برخی سیستم ها python و در برخی از سیستم ها python3 است) بنابراین اگر با اجرای یکی از این دو دستور وارد محیط shell شدید و نتیجه زیر را دریافت کردید یعنی پایتون برای شما نصب شده است:
Python 3.8.6 (default, Jan 27 2021, 15:42:20) [GCC 10.2.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>>
می توانید با فشردن کلیدهای Ctrl + D از این محیط خارج شوید.
کاربران ویندوز: Command Prompt را باز کرده و دستور python یا python3 را در آن اجرا کنید. این دستور شما را وارد shell می کند که در آن می توانید کدهای python بنویسید(دستور ورود در برخی سیستم ها python و در برخی از سیستم ها python3 است) بنابراین اگر با اجرای یکی از این دو دستور وارد محیط shell شدید و نتیجه زیر را دریافت کردید یعنی پایتون برای شما نصب شده است:
Python 3.8.6 (default, Jan 27 2021, 15:42:20) [GCC 10.2.0] on win32 Type "help", "copyright", "credits" or "license" for more information. >>>
می توانید با فشردن کلیدهای Ctrl + D از این محیط خارج شوید.
حالا چه از ویندوز و چه از مک و لینوکس استفاده می کنید، باید ترمینال یا command prompt خود را باز کرده و دستور زیر را اجرا کنید:
pip install pandas
در صورتی که با محیط Conda کار می کنید باید به جای دستور بالا، دستور زیر را در سیستم خود اجرا کنید:
conda install pandas
همچنین اگر با یک Jupyter notebook کار می کنید باید به جای دستورات قبلی این دستور را اجرا کنید:
!pip install pandas
علامت ! در ابتدای دستور بالا باعث می شود که این دستور به صورت یک دستور ترمینال اجرا شود.
زمانی که پکیج pandas را با هر کدام از روش های بالا نصب کردید، باید آن را در کدهایتان import کنید. این کار برای کاربرانی که از ویرایشگرهایی مانند visual studio code یا از Jupyter Notebook استفاده می کنند یکسان است:
import pandas as pd
استفاده از کتابخانه پانداس در پایتون با نام pd تقریبا به یک استاندارد تبدیل شده است و همه این کار را انجام می دهند چرا که تایپ آن سریع تر و راحت تر است.
نکته: من در این دوره با Jupyter Notebook ها کار می کنم اما شما می توانید از ویرایشگرهایی مانند visual studio code نیز استفاده نمایید.
قلب pandas؛ آشنایی با DataFrames و Series
pandas از دو بخش بسیار مهم به نام های Series و DataFrames ساخته شده است، بنابراین یادگیری کتابخانه پانداس در پایتون حتما باید از این دو بخش اساسی شروع شود. این دو بخش قلب pandas را تشکیل می دهند و درک آن ها به شما کمک می کند که نحوه نگاه pandas به داده ها را درک کنید.
با اینکه Series و DataFrames مباحث بسیار مهمی هستند اما در عین حال هیچ پیچیدگی خاصی ندارند و بسیار ساده هستند! هر series یک ستون ساده است و هر DataFrame یک جدول است که یعنی مجموعه ای از series ها می باشد.
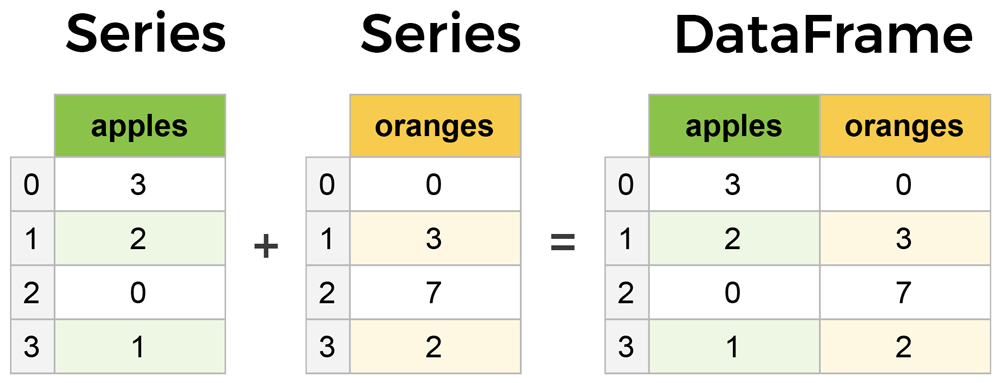
برای اینکه با کتابخانه پانداس در پایتون کار کنیم باید یک DataFrame داشته باشیم. طبیعتا سوالی مطرح می شود که این DataFrame را از کجا بیاوریم؟ روش های بسیار زیادی برای انجام این کار وجود دارد؛ مثلا می توانید از فایل های Excel و CSV استفاده کنید اما من فرض می کنم که شما به هیچ داده آماده ای دسترسی ندارید. در این حالت می توانیم از یک دیکشنری ساده استفاده کنیم:
data = {
'apples': [3, 2, 0, 1],
'oranges': [0, 3, 7, 2]
}
حالا می توانید این داده را به constructor کتابخانه پانداس در پایتون بدهید:
purchases = pd.DataFrame(data) purchases
من در کد بالا متغیر purchases را با نام ذکر کرده ام اما هیچ کاری برایش انجام نداده ام. چرا؟ به دلیل اینکه من از Jupyter Notebook ها استفاده می کنم و انجام این کار در Jupyter Notebook ها باعث چاپ مقادیر درون متغیر purchases می شود. اگر این کار را در ویرایشگرهای کد عادی مانند visual studio code انجام می دهید می توانید به جای آن از دستور print استفاده کنید اما تفاوت هایی وجود دارد. Jupyter Notebook ها داده ها را در جدول هایی بسیار زیبا و با نظم خاصی نشان می دهند. همچنین اگر حجم داده ها زیاد باشد (هزاران ردیف داده) آنگاه فقط ۲۰ یا ۳۰ ردیف اول و آخر را نمایش می دهند تا سیستم شما درگیر نمایش داده نشود. این در حالی است که استفاده از دستور print هیچ کدام از این مزایا را ندارد.
با اجرای کد بالا نتیجه زیر را می گیرید:
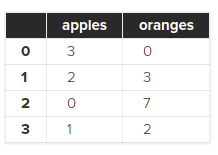
به عبارتی هر جفت key, value در شیء data باعث ایجاد یک ستون در DataFrame می شود. در ضمن شماره هایی که در کنار این جدول مشاهده می کنید همان index جدول هستند و هنگام ساخت جدول توسط pandas ایجاد شده و به ما داده می شوند اما شما می توانید خودتان نیز ایندکس های DataFrame خود را مشخص کنید. برای انجام این کار باید آرگومان index را به constructor پاس بدهید:
purchases = pd.DataFrame(data, index=['June', 'Robert', 'Lily', 'David']) purchases
من با این کار چند نام تصادفی را به عنوان ایندکس های خودم تعیین کرده ام. با اجرای این کد نتیجه زیر را دریافت می کنید:
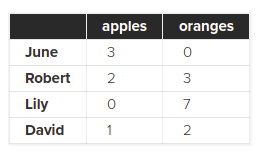
طبیعتا حالا می توانیم سفارشات یک مشتری را بر اساس نام آن مشتری پیدا کنیم:
purchases.loc['June']
اجرای این کد نتیجه زیر را به ما نشان می دهد:
apples 3 oranges 0 Name: June, dtype: int64
خواندن داده ها از فایل
استفاده از یک دیکشنری ساده برای ساخت DataFrame فقط جهت آشنایی شما با این داده ها بود اما در پروژه های بزرگ تر و برای کارهای جدی تر باید داده هایی واقعی داشته باشیم. این داده ها معمولا در قالب یک فایل CSV یا Excel است بنابراین می خواهم در این بخش، نحوه ایجاد DataFrame از فایل های CSV و JSON و حتی پایگاه های داده MySQL را نیز به شما نشان بدهم.
ساخت DataFrmae از فایل CSV
فایل های CSV فایل هایی هستند که داده هایشان با استفاده از ویرگول از هم جدا شده اند بنابراین ساختاری بسیار ساده دارند و برای بارگذاری آن ها در pandas فقط یک خط ساده کد لازم است:
df = pd.read_csv('purchases.csv')
df
متد read_csv این کار را به راحتی برایمان انجام می دهد. در ضمن محتویات فایل purchases.csv به شکل زیر است:
,apples,oranges June,3,0 Robert,2,3 Lily,0,7 David,1,2
با اجرای کد بالا چنین نتیجه ای را می گیریم:
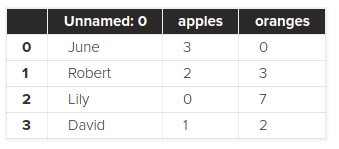
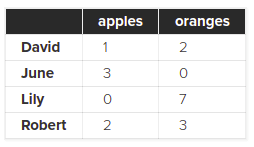
همانطور که گفتم فایل های CSV بسیار ساده هستند بنابراین دارای ایندکس نمی باشند. زمانی که pandas می بیند فایل ما دارای ایندکس نیست، به صورت خودکار یک ایندکس را به آن اضافه می کند که همان ستون شماره ها در تصویر بالا است. برای حذف این ستون می توانید آرگومان index را روی 0 بگذارید:
df = pd.read_csv('purchases.csv', index_col=0)
df
با انجام این کار ستون اعداد حذف می شود:
ساخت DataFrmae از فایل JSON
در صورتی که می خواهید از فایل های JSON (مثلا بکاپ پایگاه داده MongoDB) یک DataFrame بسازید باید از متد read_json استفاده کنید:
df = pd.read_json('purchases.json')
df
محتویات فایل purchases.json به شکل زیر است:
{
"apples": {
"June": 3,
"Robert": 2,
"Lily": 0,
"David": 1
},
"oranges": {
"June": 0,
"Robert": 3,
"Lily": 7,
"David": 2
}
}
نتیجه اجرای این کد عینا مانند تصویر قبلی است، یعنی ستون ایندکس عددی به آن اضافه نشده است. چرا؟ تو در تو بودن فایل های JSON که به nesting معروف است به pandas اجازه می دهد که از مقادیر تو در تو به عنوان ایندکس استفاده کند. البته در برخی از اوقات pandas نمی تواند فایل های JSON را به درستی تبدیل به DataFrame کند و نیاز است که آرگومان orient را نیز به تابع read_json بدهید (اطلاعات بیشتر در documentation رسمی pandas).
ساخت DataFrmae از پایگاه داده SQL
برخی اوقات می خواهیم داده های درون پایگاه داده خود را تحلیل کنیم. پکیج pandas می تواند به صورت مستقیم به یک پایگاه داده SQL متصل شود. برای این کار باید پکیج pysqlite3 را نصب کنیم. برای نصب از طریق ترمینال، دستور زیر را اجرا کنید:
pip install pysqlite3
برای نصب از طریق Jupyter Notebooks دستور زیر را اجرا کنید:
!pip install pysqlite3
ما می توانیم با استفاده از این پکیج به پایگاه داده خود متصل شویم:
import sqlite3
con = sqlite3.connect("database.db")
طبیعتا بسته به پایگاه داده خودتان (PostgreSQL یا MySQL یا امثال آن) باید پکیج مناسبی را برای اتصال به آن انتخاب کنید. در مرحله بعدی متغیر con را به pandas پاس می دهیم:
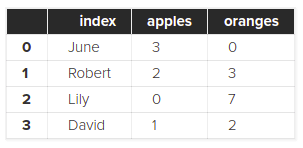
df = pd.read_sql_query("SELECT * FROM purchases", con)
df
آرگومان اول یا همان کوئری SELECT * FROM purchases باعث دریافت تمام داده ها از جدول purchases می شود:
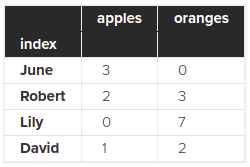
البته ما می توانیم ایندکس خود را نیز روی ستون index از پایگاه داده خود نیز ثبت کنیم:
df = df.set_index('index')
df
در این صورت نتیجه به شکل زیر خواهد بود:
ما می توانیم از متد set_index روی هر DataFrame و در هر زمانی و روی هر ستونی استفاده کنیم.
برگرداندن داده به فرمت های JSON و SQL و CSV
فرض کنید کار شما با داده ها تمام شده است (مثلا داده ها را پاک سازی کرده اید) و حالا می خواهید آن ها را در قالب یک فایل در سیستم خود ذخیره کنید. چطور می توانیم DataFrame هایمان را به فایل برگردانیم؟ برای انجام این کار از متدهای to_json و to_csv و to_sql استفاده می کنیم:
df.to_csv('new_purchases.csv')
df.to_json('new_purchases.json')
df.to_sql('new_purchases', con)
در دو مثال اول (فایل های CSV و JSON) نام فایل جدید خود را داده ایم اما در مثال سوم (sql) در حال ذخیره داده ها به صورت یک فایل نیستیم بلکه در حال insert کردن (ثبت) یک جدول جدید در پایگاه داده SQL خود هستیم و به همین دلیل است که con را نیز باید پاس بدهیم.
مهم ترین عملیات DataFrame
DataFrame های پانداس صدها متد مختلف دارند که کار های بسیار زیادی انجام می دهند اما به شما به عنوان یک تازه کار باید فقط بخشی از آن ها را یاد بگیرید که عملیات ساده را برایتان انجام می دهند. این عملیات ها معمولا پایه ویرایش داده هایتان هستند و در عین سادگی کاربردهای مختلفی دارند و به همین دلیل است که نقطه شروع خوبی محسوب می شوند.
برای انجام متدها و عملیات این قسمت باید داده های بزرگ ترین داشته باشیم، بنابراین من یک مجموعه داده مربوط به فیلم های سینمایی را برایتان آماده کرده ام. این مجموعه داده یک فایل CSV است که حاوی هزاران فیلم سینمایی و سریال و اطلاعات مربوط به آن ها (سال اکران، کارگردان، فروش و غیره) است. من بخشی از این داده ها را در بخش پایین قرار داده ام تا با آن آشنا بشوید:
Rank,Title,Genre,Description,Director,Actors,Year,Runtime (Minutes),Rating,Votes,Revenue (Millions),Metascore 1,Guardians of the Galaxy,"Action,Adventure,Sci-Fi",A group of intergalactic criminals are forced to work together to stop a fanatical warrior from taking control of the universe.,James Gunn,"Chris Pratt, Vin Diesel, Bradley Cooper, Zoe Saldana",2014,121,8.1,757074,333.13,76 2,Prometheus,"Adventure,Mystery,Sci-Fi","Following clues to the origin of mankind, a team finds a structure on a distant moon, but they soon realize they are not alone.",Ridley Scott,"Noomi Rapace, Logan Marshall-Green, Michael Fassbender, Charlize Theron",2012,124,7,485820,126.46,65 3,Split,"Horror,Thriller",Three girls are kidnapped by a man with a diagnosed 23 distinct personalities. They must try to escape before the apparent emergence of a frightful new 24th.,M. Night Shyamalan,"James McAvoy, Anya Taylor-Joy, Haley Lu Richardson, Jessica Sula",2016,117,7.3,157606,138.12,62 4,Sing,"Animation,Comedy,Family","In a city of humanoid animals, a hustling theater impresario's attempt to save his theater with a singing competition becomes grander than he anticipates even as its finalists' find that their lives will never be the same.",Christophe Lourdelet,"Matthew McConaughey,Reese Witherspoon, Seth MacFarlane, Scarlett Johansson",2016,108,7.2,60545,270.32,59 5,Suicide Squad,"Action,Adventure,Fantasy",A secret government agency recruits some of the most dangerous incarcerated super-villains to form a defensive task force. Their first mission: save the world from the apocalypse.,David Ayer,"Will Smith, Jared Leto, Margot Robbie, Viola Davis",2016,123,6.2,393727,325.02,40 6,The Great Wall,"Action,Adventure,Fantasy",European mercenaries searching for black powder become embroiled in the defense of the Great Wall of China against a horde of monstrous creatures.,Yimou Zhang,"Matt Damon, Tian Jing, Willem Dafoe, Andy Lau",2016,103,6.1,56036,45.13,42 7,La La Land,"Comedy,Drama,Music",A jazz pianist falls for an aspiring actress in Los Angeles.,Damien Chazelle,"Ryan Gosling, Emma Stone, Rosemarie DeWitt, J.K. Simmons",2016,128,8.3,258682,151.06,93 8,Mindhorn,Comedy,"A has-been actor best known for playing the title character in the 1980s detective series ""Mindhorn"" must work with the police when a serial killer says that he will only speak with Detective Mindhorn, whom he believes to be a real person.",Sean Foley,"Essie Davis, Andrea Riseborough, Julian Barratt,Kenneth Branagh",2016,89,6.4,2490,,71 9,The Lost City of Z,"Action,Adventure,Biography","A true-life drama, centering on British explorer Col. Percival Fawcett, who disappeared while searching for a mysterious city in the Amazon in the 1920s.",James Gray,"Charlie Hunnam, Robert Pattinson, Sienna Miller, Tom Holland",2016,141,7.1,7188,8.01,78 10,Passengers,"Adventure,Drama,Romance","A spacecraft traveling to a distant colony planet and transporting thousands of people has a malfunction in its sleep chambers. As a result, two passengers are awakened 90 years early.",Morten Tyldum,"Jennifer Lawrence, Chris Pratt, Michael Sheen,Laurence Fishburne",2016,116,7,192177,100.01,41 11,Fantastic Beasts and Where to Find Them,"Adventure,Family,Fantasy",The adventures of writer Newt Scamander in New York's secret community of witches and wizards seventy years before Harry Potter reads his book in school.,David Yates,"Eddie Redmayne, Katherine Waterston, Alison Sudol,Dan Fogler",2016,133,7.5,232072,234.02,66 12,Hidden Figures,"Biography,Drama,History",The story of a team of female African-American mathematicians who served a vital role in NASA during the early years of the U.S. space program.,Theodore Melfi,"Taraji P. Henson, Octavia Spencer, Janelle Monáe,Kevin Costner",2016,127,7.8,93103,169.27,74 13,Rogue One,"Action,Adventure,Sci-Fi","The Rebel Alliance makes a risky move to steal the plans for the Death Star, setting up the epic saga to follow.",Gareth Edwards,"Felicity Jones, Diego Luna, Alan Tudyk, Donnie Yen",2016,133,7.9,323118,532.17,65 14,Moana,"Animation,Adventure,Comedy","In Ancient Polynesia, when a terrible curse incurred by the Demigod Maui reaches an impetuous Chieftain's daughter's island, she answers the Ocean's call to seek out the Demigod to set things right.",Ron Clements,"Auli'i Cravalho, Dwayne Johnson, Rachel House, Temuera Morrison",2016,107,7.7,118151,248.75,81 15,Colossal,"Action,Comedy,Drama","Gloria is an out-of-work party girl forced to leave her life in New York City, and move back home. When reports surface that a giant creature is destroying Seoul, she gradually comes to the realization that she is somehow connected to this phenomenon.",Nacho Vigalondo,"Anne Hathaway, Jason Sudeikis, Austin Stowell,Tim Blake Nelson",2016,109,6.4,8612,2.87,70 16,The Secret Life of Pets,"Animation,Adventure,Comedy","The quiet life of a terrier named Max is upended when his owner takes in Duke, a stray whom Max instantly dislikes.",Chris Renaud,"Louis C.K., Eric Stonestreet, Kevin Hart, Lake Bell",2016,87,6.6,120259,368.31,61 17,Hacksaw Ridge,"Biography,Drama,History","WWII American Army Medic Desmond T. Doss, who served during the Battle of Okinawa, refuses to kill people, and becomes the first man in American history to receive the Medal of Honor without firing a shot.",Mel Gibson,"Andrew Garfield, Sam Worthington, Luke Bracey,Teresa Palmer",2016,139,8.2,211760,67.12,71 18,Jason Bourne,"Action,Thriller",The CIA's most dangerous former operative is drawn out of hiding to uncover more explosive truths about his past.,Paul Greengrass,"Matt Damon, Tommy Lee Jones, Alicia Vikander,Vincent Cassel",2016,123,6.7,150823,162.16,58 19,Lion,"Biography,Drama","A five-year-old Indian boy gets lost on the streets of Calcutta, thousands of kilometers from home. He survives many challenges before being adopted by a couple in Australia. 25 years later, he sets out to find his lost family.",Garth Davis,"Dev Patel, Nicole Kidman, Rooney Mara, Sunny Pawar",2016,118,8.1,102061,51.69,69
نام CSV مخفف Comma Separated Values (مقادیر جداشده توسط ویرگول) می باشد و همانطور که می بییند. برای دانلود این فایل روی این لینک کلیک کنید.
این فایل یک فایل CSV است بنابراین برای خواندن آن در pandas و ساخت DataFrame باید از متد read_csv استفاده نماییم:
movies_df = pd.read_csv("IMDB-Movie-Data.csv", index_col="Title")
من در کد بالا title یا عنوان فیلم ها را به عنوان index خودمان تعیین کرده ام.
نمایش داده ها
اولین متد کاربردی در pandas مربوط به نمایش داده ها است. چرا باید داده ها را چاپ کنیم؟ به دلیل اینکه برای کار با هر داده ای ابتدا باید با ساختار آن داده آشنا باشیم، مثلا بدانیم نام ستون ها چیست، و این کار با مشاهده بخشی از داده ممکن می شود. اگر بخواهیم از متد print در زبان پایتون کمک بگیریم، تمام داده ها برایمان چاپ می شود. این مسئله علاوه بر درگیر کردن شدید CPU سیستم، همه چیز را یکجا و به صورت شلوغ نمایش می دهد بنابراین باید به فکر دیگری باشیم. توسعه دهندگان pandas به فکر این موضوع بوده اند و متدی به نام head را تعریف کرده اند. متد head تنها ۵ ردیف اول از داده ها را برایمان برمی گرداند:
movies_df.head()
اگر مثل من از Jupyter Notebooks استفاده می کنید، چاپ شدن این داده ها در یک جدول شکیل و زیبا انجام خواهد شد. اگر شما می خواهید ردیف های بیشتری چاپ شود باید تعداد این ردیف ها را به head پاس بدهید:
movies_df.head(10)
این کد ۱۰ ردیف اول داده را به ما پاس می دهد. البته برخی اوقات ممکن است بخواهید داده های آخر فایل را نیز مشاهده کنید بنابراین متدی به نام tail نیز وجود دارد ۵ ردیف انتهایی داده ها را به شما نشان می دهد مگر آنکه مانند head عدد خاصی به آن پاس داده باشید. مثال:
movies_df.tail(2)
این کد ۲ ردیف انتهایی DataFrame را برایمان چاپ می کند:

در ضمن با دقت بیشتر متوجه می شوید که نام ستون title کمی پایین تر از نام ستون های دیگر است. این یک اشتباه استایلی نیست بلکه نشان می دهد که title همان index ما است. البته به صورت کلی قانونی وجود دارد که اگر می خواهید با DataFrame خود کاری انجام بدهید باید یک بار آن را به شکل بالا چاپ کنید تا متوجه ساختار کلی آن بشوید.
دریافت اطلاعات کلی داده ها
متد کاربردی دیگر دریافت اطلاعاتی کلی راجع به داده هایتان است. این کار با متد ()info انجام می شود:
movies_df.info()
با اجرای کد بالا چنین نتیجه یا را دریافت می کنید:
<class 'pandas.core.frame.DataFrame'> Index: 1000 entries, Guardians of the Galaxy to Nine Lives Data columns (total 11 columns): Rank 1000 non-null int64 Genre 1000 non-null object Description 1000 non-null object Director 1000 non-null object Actors 1000 non-null object Year 1000 non-null int64 Runtime (Minutes) 1000 non-null int64 Rating 1000 non-null float64 Votes 1000 non-null int64 Revenue (Millions) 872 non-null float64 Metascore 936 non-null float64 dtypes: float64(3), int64(4), object(4) memory usage: 93.8+ KB
خوب به گزارش بالا دقت کنید. در قسمت Index عبارت 1000entries, Guardians of the Galaxy to Nine Lives نوشته شده است که یعنی ۱۰۰۰ ردیف یا ۱۰۰۰ فیلم مختلف داریم. اولین فیلم Guardians of the Galaxy و آخرین فیلم Nine Lives می باشد. در ضمن ترتیب ردیف ها (یا در این مثال، فیلم ها) به همان ترتیب ذخیره شده در فایل CSV است و pandas کاری با آن نمی کند. در بخش بعدی که Data columns می باشد عبارت total 11 columns را مشاهده می کنیم که یعنی داده های ما مجموعا ۱۱ ستون دارد. در ادامه تک تک این ستون ها با ساختار زیر ذکر شده اند:
Genre 1000 non-null object
این گزارش به ما می گوید که ستون Genre (ژانر سینمایی) هزار ردیف دارد که null نیستند و نوع داده آن ها نیز object یا string object است. در انتهای گزارش نیز دو ستون dtypes و memory usage را داریم که به ترتیب به data type (نوع داده های جدول) و میزان استفاده از مموری سیستم اشاره می کنند. میزان مصرف مموری یا memory usage به این دلیل نمایش داده شده است که در زمان استفاده از کتابخانه pandas داده هایتان در مموری بارگذاری می شوند چرا که کار با آن ها از روی هارد دیسک بسیار کند خواهد بود. در صورتی که به ستون های Revenue و Metascore در گزارش بالا توجه کنید متوجه می شوید که تعداد ردیف هایشان کمتر از ۱۰۰۰ تا است (به ترتیب ۸۷۲ و ۹۳۶ ردیف) بنابراین ناقص هستند. در ادامه این مقاله توضیح خواهیم داد که با آن ها چه کار کنیم.
یکی از مثال های ساده کاربرد info زمانی است که داده هایی را وارد pandas کرده اید. داده های شما در ظاهر کاملا عددی است اما زمانی که عملیاتی را روی آن ها انجام می دهد خطای unsupported operand را دریافت می کنید. قدم اول برای حل این مسئله استفاده از تابع info است تا بتوانید نوع داده های جدول خود را مشاهده کنید. معمولا زمانی که افراد خطای unsupported operand می گیرند، متوجه می شوند که داده هایشان در واقع رشته ای بوده است اما از آنجایی که درون رشته ها عدد می باشد تصور کرده اند که داده ها عددی است.
متد دیگری به نام shape نیز وجود دارد که بسیار خلاصه تر است و تنها یک tuple از ردیف ها و ستون ها برمی گرداند:
movies_df.shape
نتیجه اجرای این کد به شکل زیر می باشد:
(1000, 11)
عدد اول (۱۰۰۰) تعداد ردیف ها و عدد دوم (۱۱) تعداد ستون ها است.
حذف مقادیر تکراری
یکی از کاربردهای دیگر کتابخانه پانداس در پایتون (pandas)، حذف مقادیر تکراری از داده های شما است. ما در داده هایمان هیچ ردیف تکراری نداریم بنابرین باید یک ردیف تکراری را ایجاد کنیم. من برای انجام این کار از متد append استفاده می کنم که به ما اجازه می دهد داده هایی را به یک DataFrame اضافه کنیم:
temp_df = movies_df.append(movies_df) temp_df.shape
همانطور که می بینید من DataFrame خودمان را به خودش اضافه کرده ام! یعنی چه؟ یعنی یک کپی از داده هایمان گرفته ایم تا داده ها دو برابر شوند. در نظر داشته باشید که append به داده های اصلی دست نمی زند بلکه یک DataFrame کاملا جدید را برمی گرداند. به همین دلیل است که ما نتیجه آن را در متغیر temp_df ذخیره کرده ایم. در حال حاضر نصف داده های درون temp_df تکراری هستند بنابراین با اجرای کد بالا نتیجه زیر را می گیریم:
(2000, 11)
همانطور که می بینید تعدد ردیف هایمان دو برابر شده است. حالا اگر می خواهید داده های تکراری را از DataFrame خود حذف کنید، باید متد drop_duplicates را صدا بزنید:
temp_df = temp_df.drop_duplicates() temp_df.shape
در نظر داشته باشید که متد drop_duplicates نیز داده های اصلی را ویرایش نمی کند بلکه یک کپی ویرایش شده از داده ها را برمی گرداند. به همین دلیل است که من آن را در متغیری به نام temp_df ذخیره کرده ام. با این کار مقادیر قبلی متغیر temp_df حذف شده و این مقدار جدید جایگزین آن می شود. با اجرای این کد نتیجه زیر را دریافت می کنیم:
(1000, 11)
بسیاری از افراد دوست دارند که مستقیما DataFrame اصلی را ویرایش کنند نه اینکه نتیجه را در متغیرهای مختلفی دریافت کنند. pandas آرگومانی به نام inplace دارد که به شما اجازه این کار را می دهد اما باید در نظر داشته باشید که این کار خطرناک است و باید کاملا حواستان را جمع کنید:
temp_df.drop_duplicates(inplace=True)
اگر inplace را روی True بگذارید، DataFrame اصلی ویرایش خواهد شد. این آرگومان روی بسیاری از متدهای pandas کار می کند و منحصر به این متد خاص نیست.
یکی دیگر از آرگومان های مهم برای متد drop_duplicates آرگومانی به نام keep است که یکی از سه مقدار زیر را می گیرد:
- first (گزینه پیش فرض): زمانی که به داده های تکراری رسیدیم فقط داده اول را نگه داشته و دیگر داده ها را حذف می کنیم. مثلا اگر دو ردیف تکراری داشته باشیم، ردیف دوم حذف می شود.
- last: زمانی که به داده های تکراری رسیدیم فقط داده آخر را نگه داشته و دیگر داده ها را حذف می کنیم. مثلا اگر دو ردیف تکراری داشته باشیم، ردیف اول حذف می شود.
- false: زمانی که به داده های تکراری رسیدیم تمام آن ها را حذف می کنیم به طوری که حتی یک نمونه از آن داده نیز دیگر باقی نماند. مثلا اگر دو ردیف تکراری داشته باشیم، هر دو ردیف حذف می شوند.
ما این آرگومان را در کدهای قبلی مشخص نکرده بودیم بنابراین به صورت پیش فرض حالت first را انتخاب می کند. به مثال زیر توجه کنید:
temp_df = movies_df.append(movies_df) # ساخت یک کپی temp_df.drop_duplicates(inplace=True, keep=False) temp_df.shape
من در این مثال از تمام DataFrame خودمان (movies_df) یک کپی گرفته و آن را به خودش اضافه کرده ام. با انجام این کار تمام داده های موجود در temp_df تکراری هستند (از هر ردیف، دو عدد داریم). حالا متد drop_duplicates را صدا زده ایم اما این بار keep را روی false گذاشته ایم که یعنی تمام موارد تکراری را حذف کند. با اجرای کد بالا چنین نتیجه ای می گیریم:
(0, 11)
از آنجایی که تمام داده ها تکراری بودند، تمام داده ها حذف شده اند و حالا تعداد ردیف های ما به صفر رسیده است.
پاکسازی ستون ها
در بسیاری از اوقات data set های ما (مجموعه داده ها) دارای ستون هایی با نام های عجیب و غریب و پر اشکال هستند؛ مثلا از علامت های خاصی استفاده کرده اند، حروف کوچک و بزرگ انگلیسی را رعایت نکرده اند، اشتباهات املایی دارند و الی آخر. معمولا زمانی که می خواهیم به سراغ یک مجموعه داده برویم، روش آسان تر این است که در همان ابتدا کمی ستون ها را تمیزتر کنیم. برای این کار ابتدا باید ستون ها را ببینیم:
movies_df.columns
با اجرای کد بالا نتیجه زیر را می گیریم:
Index(['Rank', 'Genre', 'Description', 'Director', 'Actors', 'Year', 'Runtime (Minutes)', 'Rating', 'Votes', 'Revenue (Millions)', 'Metascore'], dtype='object')
من از وجود علامت پرانتز ناراضی هستم و می خواهم نام ستون هایم بسیار ساده باشند بنابراین از متدی به نام rename در pandas استفاده می کنم تا نامشان را تغییر بدهم:
movies_df.rename(columns={
'Runtime (Minutes)': 'Runtime',
'Revenue (Millions)': 'Revenue_millions'
}, inplace=True)
movies_df.columns
همانطور که می بینید من یک دیکشنری ساده را به آرگومان columns داده ام به طوری که هر key نام فعلی ستون و value نام جدید ستون خواهد بود. آرگومان inplace نیز برای این است که داده ها به صورت مستقیم ویرایش شوند. با اجرای کد بالا نتیجه زیر را می گیریم:
Index(['Rank', 'Genre', 'Description', 'Director', 'Actors', 'Year', 'Runtime', 'Rating', 'Votes', 'Revenue_millions', 'Metascore'], dtype='object')
متد rename زمانی استفاده می شود که می خواهید عنصر خاصی را در داده هایتان دوباره نام گذاری کنید اما گر می خواهید تمام ستون ها را تغییر دهید، بهتر است از همان خصوصیت columns استفاده نمایید. مثلا من می خواهم تمام ستون ها را با حروف کوچک انگلیسی بنویسم:
movies_df.columns = ['rank', 'genre', 'description', 'director', 'actors', 'year', 'runtime', 'rating', 'votes', 'revenue_millions', 'metascore'] movies_df.columns
با اجرای این کد نتیجه به شکل زیر خواهد بود:
Index(['rank', 'genre', 'description', 'director', 'actors', 'year', 'runtime', 'rating', 'votes', 'revenue_millions', 'metascore'], dtype='object')
بنابراین همه چیز ویرایش شده است.
البته در برخی از موارد تعداد ستون ها به صد عدد نیز می رسد! طبیعتا در چنین حالتی نمی توانیم تک تک ستون ها را نام گذاری کنیم بنابراین باید راه بهتری برای بازنویسی ستون ها با حروف کوچک باشیم. بهترین راه استفاده از یک list comprehension است که یکی از قابلیت های زبان پایتون می باشد. اگر با list comprehension آشنا نیستید به صورت خلاصه و با یک مثال برایتان توضیح می دهم. فرض کنید می خواهیم روی کاراکتر های یک رشته گردش کنیم. در حالت عادی از حلقه ای مانند حلقه For استفاده می کنیم:
h_letters = [] for letter in 'human': h_letters.append(letter) print(h_letters)
با اجرای این کد نتیجه زیر را دریافت می کنیم:
['h', 'u', 'm', 'a', 'n']
این روش کاربردی بوده و مشکلی ندارد اما پایتون روش خلاصه تری به نام list comprehension را ارائه می دهد. شما می توانید با استفاده از این روش، از یک لیست موجود لیست جدیدی بسازید. من عملیات بالا را به همان شکل قبلی انجام می دهم:
h_letters = [ letter for letter in 'human' ] print( h_letters)
با انجام این کار باز هم همان نتیجه قبلی را می گیرید:
['h', 'u', 'm', 'a', 'n']
با این حساب ما می توانیم از list comprehension برای گردش روی ستون های خود استفاده کنیم:
movies_df.columns = [col.lower() for col in movies_df] movies_df.columns
حتما می دانید که متد ()lower در زبان پایتون باعث تبدیل حروف بزرگ انگلیسی به حروف کوچک می شود بنابراین با گردش بین ستون های movies_df و اجرای متد lower روی تک تک آن ها، باعث کوچک شدن حروف نام ستون ها خواهیم شد. با اجرای کد بالا نتیجه زیر برایتان برگردانده می شود:
Index(['rank', 'genre', 'description', 'director', 'actors', 'year', 'runtime', 'rating', 'votes', 'revenue_millions', 'metascore'], dtype='object')
کار با مقادیر غایب
زمانی که با داده های بزرگ کار می کنید اغلب به مقادیر null یا مقادیر غایب روبرو می شوید، یعنی خانه هایی که اصلا مقداری ندارند. این مقادیر در زبان پایتون معمولا به صورت None و در کتابخانه هایی مانند NumPy به صورت np.nan نمایش داده می شوند. روش برخورد با این مقادیر بسته به شرایط متفاوت خواهد بود اما معمولا دو روش کلی وجود دارد:
- ستون ها یا ردیف هایی که null هستند را به طور کامل حذف کنید.
- استفاده از تکنیکی به نام imputation که در آن مقادیر غایب را با مقادیر خاصی جا به جا می کنیم.
در ابتدا باید تعداد خانه های خالی در DataFrame خود را محاسبه کنیم:
movies_df.isnull()
متد isnull این کار را به راحتی برایمان انجام می دهد و نتیجه زیر را دارد:
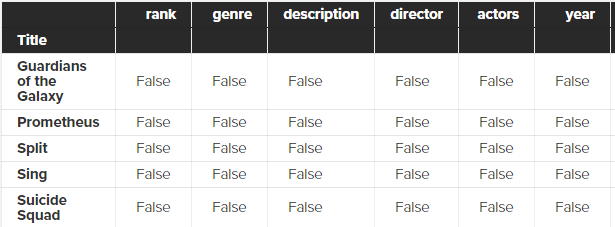
همانطور که می بینید جدولی برایمان نشان داده می شود که ستون های داده ما را دارد (من فقط بخشی از جدول را در تصویر بالا آورده ام). هر خانه از این جدول یا true و یا false خواهد بود و بدین شکل می بینید که چه خانه هایی از جدول شما null هستند (true) و یا نیستند (False).
طبیعتا انجام چنین کاری در جدول های بزرگ بسیار سخت بوده و بهتر است از روش دیگری برای شماره خانه های null استفاده کنیم:
movies_df.isnull().sum()
با اجرای کد بالا نتیجه ای به شکل زیر دریافت می کنید:
rank 0 genre 0 description 0 director 0 actors 0 year 0 runtime 0 rating 0 votes 0 revenue_millions 128 metascore 64 dtype: int64
همانطور که می بینید در ستون های revenue_millions و metascore به ترتیب 128 و 64 ردیف خالی داریم. زمانی که تابع Sum را به تابع isnull زنجیره کنیم کار شمارش این ردیف ها به صورت خودکار انجام می شود.
همانطور که قبلا توضیح دادم دو روش اصلی برای مقابله با این داده های خالی وجود دارد. روش اول حذف آن ها بود. در نظر داشته باشید که تحلیل گران داده معمولا به سختی بین این دو روش انتخاب می کنند بنابراین این انتخاب سختی است و به طبیعت داده های شما مربوط است. روش حذف داده فقط زمانی انجام می شود که حجم داده های null شما بسیار کم باشد. برای انجام این کار باید از متد dropna استفاده کنید:
movies_df.dropna()
این دستور هر ردیفی را که حداقل یک خانه null و خالی داشته باشد حذف می کند اما نتیجه را به شکل یک DataFrame جدید برمی گرداند و به DataFrame اصلی دست نمی زند. طبیعتا اگر می خواهید DataFrame اصلی را ویرایش کنید باید آرگومان inplace=True را به این متد پاس بدهید. با این حساب اجرا کردن دستور بالا باعث حذف 128 ردیف کامل در revenue_millions و حذف 64 ردیف از metascore می شود.
البته می توانید به جای ردیف ها، ستون ها را نیز حذف کنید. این کار با پاس دادن آرگومان axis انجام می شود:
movies_df.dropna(axis=1)
با اجرای کد بالا ستون های revenue_millions و metascore به طور کامل حذف می شوند. شاید بپرسید axis=1 از کجا آمده است. اگر یادتان باشد ما خصوصیتی به نام shape را داشتیم که به شکل زیر بود:
movies_df.shape
و زمانی که آن را روی داده هایمان اجرا کردیم چنین نتیجه ای گرفتیم:
(1000, 11)
اگر دقت کنید متوجه می شوید که ردیف ها (عد ۱۰۰۰) در ایندکس صفر و ستون ها (عدد ۱۱) در ایندکس یک قرار دارند. axis مشخص می کند که از کدام یک از این ایندکس ها برای انجام عملیات استفاده کنیم و زمانی که axis را روی 1 می گذاریم یعنی از ستون ها استفاده شود.
طبیعتا انجام هر دوی این کارها در داده های ما عاقلانه نیست چرا که در این دو روش کل ردیف یا ستون حذف شده و داده های مناسبی که برای ستون ها یا ردیف های دیگر داشتیم را نیز از دست خواهیم داد.
در موقعیتی مثل موقعیت ما بهتر است از تکنیک imputation (جانهی) استفاده کنیم. در این تکنیک داده های خالی را با داده ای دیگر پُر می کنیم. با چه داده ای؟ معمولا با mean (میانگین) یا median (میانه) همان ستون پُر می شوند. به طور مثال با revenue_millions شروع می کنیم. ابتدا باید این ستون را در قالب یک متغیر جداگانه استخراج کنیم بنابراین:
revenue = movies_df['revenue_millions']
زمانی که می خواهید یک ستون خاص از یک DataFrame را استفاده کنید، معمولا از علامت های براکت (علامت های []) استفاده می کنیم. با انجام این کار متغیر revenue شامل مجموعه ای از مقادیر خودش خواهد بود. برای اثبات این موضوع کد زیر را می نویسیم:
revenue.head()
همانطور که قبلا گفتم head دقیقا ۵ ردیف اول از یک ستون را برمی گرداند بنابراین با اجرای آن این نتیجه را دریافت می کنیم:
Title Guardians of the Galaxy 333.13 Prometheus 126.46 Split 138.12 Sing 270.32 Suicide Squad 325.02 Name: revenue_millions, dtype: float64
در مرحله بعدی میانگین (mean) این ستون را حساب می کنیم:
revenue_mean = revenue.mean() revenue_mean
با اجرای این کد عدد 82.95637614678897 چاپ خواهد شد که همان میانگین این ستون است. حالا از متد fillna استفاده می کنیم که کارش پُر کردن خانه های خالی جدول با یک مقدار خاص است:
revenue.fillna(revenue_mean, inplace=True)
من متغیر revenue_mean را به fillna پاس داده ام که یعنی تمام خانه های خالی را با این متغیر پر کن. همچنین با پاس دادن inplace=True باعث ویرایش DataFrame اصلی شده ایم. حالا یک بار دیگر خانه های خالی را در کل DataFrame بررسی می کنیم:
movies_df.isnull().sum()
با اجرای این کد نتیجه زیر را دریافت می کنیم:
rank 0 genre 0 description 0 director 0 actors 0 year 0 runtime 0 rating 0 votes 0 revenue_millions 0 metascore 64 dtype: int64
همانطور که می بینید دیگر هیچ خانه خالی در ستون revenue_millions وجود ندارد! مثالی که در این بخش مشاهده کردید یک مثال بسیار ساده و ابتدایی با هدف آموزش بود. در دنیای واقعی معمولا به دنبال داده های ریزتری می گردیم. به طور مثال به جای اینکه میانگین کل ستون را به دست بیاوریم، بر اساس ژانر فیلم سینمایی عمل می کردیم؛ یعنی اگر خانه خالی ما در ژانر کمدی باشد باید میانگین فروش فیلم های کمدی را در این قسمت قرار می دادیم.
جزئیات داده ها
ما تا این بخش با متدهای مختلفی برای مشاهده جزئیات DataFrame آشنا شده ایم. همانطور که می دانید با اجرای متد describe روی یک DataFrame می توانیم جزئیات آماری این DataFrame را مشاهده کنیم:
movies_df.describe()
با اجرای این متد بدین شکل، نتیجه زیر را دریافت می کنیم:
rank year runtime rating votes revenue_millions metascore count 1000.000000 1000.000000 1000.000000 1000.000000 1.000000e+03 1000.000000 936.000000 mean 500.500000 2012.783000 113.172000 6.723200 1.698083e+05 82.956376 58.985043 std 288.819436 3.205962 18.810908 0.945429 1.887626e+05 96.412043 17.194757 min 1.000000 2006.000000 66.000000 1.900000 6.100000e+01 0.000000 11.000000 25% 250.750000 2010.000000 100.000000 6.200000 3.630900e+04 17.442500 47.000000 50% 500.500000 2014.000000 111.000000 6.800000 1.107990e+05 60.375000 59.500000 75% 750.250000 2016.000000 123.000000 7.400000 2.399098e+05 99.177500 72.000000 max 1000.000000 2016.000000 191.000000 9.000000 1.791916e+06 936.630000 100.000000
این داده ها زمانی کاربرد خواهند داشت که بخواهیم با کتابخانه های بصری سازی، جداولی را رسم کنیم. البته شما می توانید describe را روی ستون خاصی نیز صدا بزنید. به طور مثال:
movies_df['genre'].describe()
با اجرای این کد نتیجه زیر را می گیریم:
count 1000 unique 207 top Action,Adventure,Sci-Fi freq 50 Name: genre, dtype: object
top به معنی پرتکرارترین های این ستون است و از آنجایی که ستون ما همان ژانر سینمایی است، پرتکرارترین ژانر سینمایی را به ما نشان داده است. بخش freq به معنای frequency یا تناوب این ژانرها است و در گزارش بالا نشان می دهد که این ژانر های top دقیقا 50 بار تکرار شده اند. همچنین unique به معنای «یکتا» یا «منحصر به فرد» است و به ما می گوید که این ستون ۲۰۷ مقدار یکتا (تکرار نشده) دارد.
البته متدی به نام value_counts نیز وجود دارد که تناوب مقادیر یک ستون را به ما می دهد:
movies_df['genre'].value_counts().head(10)
من در کد بالا ۱۰ تناوب اول را از ستون genre گرفته و نمایش داده ام:
Action,Adventure,Sci-Fi 50 Drama 48 Comedy,Drama,Romance 35 Comedy 32 Drama,Romance 31 Action,Adventure,Fantasy 27 Comedy,Drama 27 Animation,Adventure,Comedy 27 Comedy,Romance 26 Crime,Drama,Thriller 24 Name: genre, dtype: int64
رابطه بین متغیرهای پیوسته
pandas متدی به نام corr (مخفف correlation یا همبستگی) را دارد که برای نمایش روابط بین متغیرهای پیوسته استفاده می شود. به مثال زیر توجه کنید:
movies_df.corr()
با اجرای این دستور نتیجه زیر را دریافت می کنید:
rank year runtime rating votes revenue_millions metascore rank 1.000000 -0.261605 -0.221739 -0.219555 -0.283876 -0.252996 -0.191869 year -0.261605 1.000000 -0.164900 -0.211219 -0.411904 -0.117562 -0.079305 runtime -0.221739 -0.164900 1.000000 0.392214 0.407062 0.247834 0.211978 rating -0.219555 -0.211219 0.392214 1.000000 0.511537 0.189527 0.631897 votes -0.283876 -0.411904 0.407062 0.511537 1.000000 0.607941 0.325684 revenue_millions -0.252996 -0.117562 0.247834 0.189527 0.607941 1.000000 0.133328 metascore -0.191869 -0.079305 0.211978 0.631897 0.325684 0.133328 1.000000
اعداد مثبت نشان دهنده همبستگی مثبت هستند؛ یعنی زمانی که یکی از آن ها بالا برود دیگری نیز بالا می رود. از طرف دیگر اعداد منفی نشان دهنده همبستگی منفی هستند؛ یعنی زمانی که یک عدد بالا برود دیگر پایین می رود. همچنین عدد 1.0 نشان دهنده همبستگی کامل و ۱۰۰% است. به طور مثال با بررسی جدول بالا می بینیم که ستون rank با خودش همبستگی کامل (1.0) دارد که طبیعی است چرا که عینا خودش را با خودش مقایسه کرده ایم. از طرف دیگر همبستگی بین votes و revenue_millions برابر با 0.6 است. زمانی که به مبحث plotting برسیم به استفاده های مختلف این آمار پی خواهید برد.
برش DataFrame و استخراج از آن
ما تا این بخش یاد گرفته ایم که می توانیم با استفاده از علامت های براکت (علامت های []) ستون خاصی را از DataFrame ها استخراج کنیم اما در این بخش می خواهیم با روش های پیشرفته تری برای استخراج داده از DataFrame یا برش زدن قسمتی از آن آشنا شویم. با اینکه بسیاری از متدها در DataFrame ها و Series ها یکی هستند اما این دو، خصوصیت های خودشان را دارند بنابراین همیشه باید حواستان باشد که با کدام یک از آن ها کار می کنید تا به خطای های مختلف attribute برخورد نکنید.
استخراج ستون
همانطور قبلا هم گفتیم برای استخراج یک ستون کامل باید از علامت های براکت استفاده کنید:
genre_col = movies_df['genre'] type(genre_col)
با اجرای کد بالا نتیجه pandas.core.series.Series را می گیریم که همان type یا نوع داده برگردانده شده است. اگر یادتان باشد گفتم که series ها فقط یک ستون هستند و زمانی که در کنار هم قرار بگیرند یک DataFrame را تشکیل می دهند. با این حساب دستور بالا یک series را به ما برگردنده است. اگر می خواهید ستون استخراج شده شما به جای Series یک DataFrame باشد باید لیستی از نام های ستون های مورد نظر را پاس بدهید. اگر فقط یک ستون مد نظر شما است بنابراین همان را پاس می دهیم:
genre_col = movies_df[['genre']] type(genre_col)
با اجرای این کد نتیجه زیر را دریافت می کنیم:
pandas.core.frame.DataFrame
همانطور که می بینید نوع داده ما این بار نوع داده ما یک DataFrame است. طبیعتا شما می توانید هر تعداد ستونی را به این روش استخراج کنید:
subset = movies_df[['genre', 'rating']] subset.head()
نتیجه این کد به شکل زیر خواهد بود:
Title genre rating Guardians of the Galaxy Action,Adventure,Sci-Fi 8.1 Prometheus Adventure,Mystery,Sci-Fi 7.0 Split Horror,Thriller 7.3 Sing Animation,Comedy,Family 7.2 Suicide Squad Action,Adventure,Fantasy 6.2
استخراج ردیف
برای استخراج ردیف ها دو گزینه loc و iloc را داریم که به ترتیب بر اساس نام و بر اساس ایندکس عمل می کنند. ایندکس جدول ما title یا نام فیلم بود بنابراین می توانیم از آن برای دریافت یک ردیف استفاده کنیم. به مثال زیر از loc توجه کنید:
prom = movies_df.loc["Prometheus"] prom
با اجرای این کد نتیجه زیر را دریافت می کنید:
rank 2 genre Adventure,Mystery,Sci-Fi description Following clues to the origin of mankind, a te... director Ridley Scott actors Noomi Rapace, Logan Marshall-Green, Michael Fa... year 2012 runtime 124 rating 7 votes 485820 revenue_millions 126.46 metascore 65 Name: Prometheus, dtype: object
همانطور که می بینید تمام اطلاعات این ردیف را دریافت کرده ایم! از طرف دیگر روش iloc را داریم که به جای نام ایندکس، شماره ایندکس را دریافت می کند:
prom = movies_df.iloc[1]
با اینکار اولین ایندکس از ردیف ها را دریافت می کنید. در ضمن در نظر داشته باشید که می توانیم از روش list slicing پایتون، در این حالت نیز استفاده کنیم. به طور مثال:
movie_subset = movies_df.loc['Prometheus':'Sing'] movie_subset = movies_df.iloc[1:4] movie_subset
کد بالا می گوید از فیلم سینمایی Prometheus تا فیلم سینمایی Sing را جدا کرده و در متغیر movie_subset قرار بدهیم. در روش دوم نیز از ایندکس ۱ تا ۴ (یعنی ردیف های ۱ و ۲ و ۳) را جدا کرده ایم و ایندکس چهارم را شامل نمی شود. نتیجه اجرای این کد به شکل زیر است:
Title rank genre description director actors year runtime rating votes revenue_millions metascore Prometheus 2 Adventure,Mystery,Sci-Fi Following clues to the origin of mankind, a te... Ridley Scott Noomi Rapace, Logan Marshall-Green, Michael Fa... 2012 124 7.0 485820 126.46 65.0 Split 3 Horror,Thriller Three girls are kidnapped by a man with a diag... M. Night Shyamalan James McAvoy, Anya Taylor-Joy, Haley Lu Richar... 2016 117 7.3 157606 138.12 62.0 Sing 4 Animation,Comedy,Family In a city of humanoid animals, a hustling thea... Christophe Lourdelet Matthew McConaughey,Reese Witherspoon, Seth Ma... 2016 108 7.2 60545 270.32 59.0
نکته مهم اینجاست که اگر از روش اول یا همان loc استفاده کنید، فیلم Sing نیز در نتایج خواهد بود اما اگر از روش iloc استفاده کنید، ایندکس چهارم (فیلم Suicide Squad) در نتایج نخواهد بود.
استخراج شرطی
در دو بخش قبلی در رابطه با انتخاب ستون ها و ردیف ها صحبت کردیم اما چطور می توانیم این داده ها را بر اساس شرط خاصی استخراج کنیم؟ به طور مثال چطور می توانیم فقط فیلم هایی را از DataFrame خود استخراج کنیم که برابر با 8 باشند؟ یا مثلا چطور می توان فقط فیلم هایی را استخراج کرد که آقای Ridley Scott کارگردانشان باشد؟ انجام این کار بسیار ساده است! تنها کافی است که یک ستون را گرفته و یک شرط boolean را به آن اضافه کنید. مثال:
condition = (movies_df['director'] == "Ridley Scott") condition.head()
همانطور که می بینید ما تنها یک شرط بسیار ساده را نوشته ایم. با اجرای کد بالا نتیجه زیر را می گیریم:
Title Guardians of the Galaxy False Prometheus True Split False Sing False Suicide Squad False Name: director, dtype: bool
همانطور که می بینید در اینجا یک سری فیلم سینمایی برایمان برگردانده شده است که هر کدام دارای مقدار true یا false است که مشخص می کند کارگردان این فیلم ها آقای Ridley Scott می باشد یا خیر. این یک قدم به سوی هدف است اما هنوز حالت ایده آل ما نیست. ما می خواهیم فقط فیلم هایی را داشته باشیم که توسط آقای Ridley Scott کارگردانی شده اند نه اینکه گزارشی از این موضوع دریافت کنیم. به زبان ساده تر باید فیلم هایی که در گزارش بالا false هستند را از نتایج حذف کنیم. پاسخ این مسئله یک کد بسیار ساده است. من از شما می خواهم که خودتان به این موضوع فکر کنید و سعی کنید پاسخش را پیدا کنید و سپس به پاسخ من نگاه کنید:
movies_df[movies_df['director'] == "Ridley Scott"]
ما باید شرطی که در کد قبلی نوشته بودیم را به عنوان index روی DataFrame خود استفاده کنیم! با انجام این کار تک تک فیلم ها را بدون دردسر جدا کرده ایم چرا که برای هر فیلم شرط خاصی را داریم که یا true و یا false است و می توانیم آن فیلم را به عنوان ایندکس خودش استفاده کنیم. با اجرای کد بالا نتیجه زیر را دریافت می کنید:
Title rank genre description director actors year runtime rating votes revenue_millions metascore rating_category Prometheus 2 Adventure,Mystery,Sci-Fi Following clues to the origin of mankind, a te... Ridley Scott Noomi Rapace, Logan Marshall-Green, Michael Fa... 2012 124 7.0 485820 126.46 65.0 bad The Martian 103 Adventure,Drama,Sci-Fi An astronaut becomes stranded on Mars after hi... Ridley Scott Matt Damon, Jessica Chastain, Kristen Wiig, Ka... 2015 144 8.0 556097 228.43 80.0 good Robin Hood 388 Action,Adventure,Drama In 12th century England, Robin and his band of... Ridley Scott Russell Crowe, Cate Blanchett, Matthew Macfady... 2010 140 6.7 221117 105.22 53.0 bad American Gangster 471 Biography,Crime,Drama In 1970s America, a detective works to bring d... Ridley Scott Denzel Washington, Russell Crowe, Chiwetel Eji... 2007 157 7.8 337835 130.13 76.0 bad Exodus: Gods and Kings 517 Action,Adventure,Drama The defiant leader Moses rises up against the ... Ridley Scott Christian Bale, Joel Edgerton, Ben Kingsley, S... 2014 150 6.0 137299 65.01 52.0 bad
همانطور که می بینید فقط فیلم های ساخته شده به کارگردانی Ridley Scott برایمان برگردانده شده اند. در ابتدا کار با این شرط ها کمی عجیب و غریب به نظر خواهد رسید اما نگران نباشید، به مرور زمان به آن عادت خواهید کرد.
حالا به سراغ مثال دوم می رویم. فرض کنید بخواهیم فیلم هایی با امتیاز برابر با یا بیشتر از 8.6 را استخراج کنیم. در این حالت می توان گفت:
movies_df[movies_df['rating'] >= 8.6].head(3)
از آنجایی که فیلم های بالای 8.6 زیاد هستند من با متد head فقط 3 عدد از آن ها را دریافت کرده ام:
Title rank genre description director actors year runtime rating votes revenue_millions metascore Interstellar 37 Adventure,Drama,Sci-Fi A team of explorers travel through a wormhole ... Christopher Nolan Matthew McConaughey, Anne Hathaway, Jessica Ch... 2014 169 8.6 1047747 187.99 74.0 The Dark Knight 55 Action,Crime,Drama When the menace known as the Joker wreaks havo... Christopher Nolan Christian Bale, Heath Ledger, Aaron Eckhart,Mi... 2008 152 9.0 1791916 533.32 82.0 Inception 81 Action,Adventure,Sci-Fi A thief, who steals corporate secrets through ... Christopher Nolan Leonardo DiCaprio, Joseph Gordon-Levitt, Ellen... 2010 148 8.8 1583625 292.57 74.0
هر سه فیلم برگردانده شده بالای 8.6 یا مساوی با آن هستند.
ما می توانیم با استفاده از اپراتور | که به معنی or یا «یا» می باشد شرط های خودمان را قوی تر کنیم. مثلا فرض کنید به دنبال فیلم هایی می گردیم که توسط Christopher Nolan یا Ridley Scott کارگردانی شده باشند. در چنین حالتی می توانیم با استفاده از اپراتور | شرط خود را بنویسیم:
movies_df[(movies_df['director'] == 'Christopher Nolan') | (movies_df['director'] == 'Ridley Scott')].head()
با اجرای این دستور نتیجه زیر را می گیریم:
Title rank genre description director actors year runtime rating votes revenue_millions metascore Prometheus 2 Adventure,Mystery,Sci-Fi Following clues to the origin of mankind, a te... Ridley Scott Noomi Rapace, Logan Marshall-Green, Michael Fa... 2012 124 7.0 485820 126.46 65.0 Interstellar 37 Adventure,Drama,Sci-Fi A team of explorers travel through a wormhole ... Christopher Nolan Matthew McConaughey, Anne Hathaway, Jessica Ch... 2014 169 8.6 1047747 187.99 74.0 The Dark Knight 55 Action,Crime,Drama When the menace known as the Joker wreaks havo... Christopher Nolan Christian Bale, Heath Ledger, Aaron Eckhart,Mi... 2008 152 9.0 1791916 533.32 82.0 The Prestige 65 Drama,Mystery,Sci-Fi Two stage magicians engage in competitive one-... Christopher Nolan Christian Bale, Hugh Jackman, Scarlett Johanss... 2006 130 8.5 913152 53.08 66.0 Inception 81 Action,Adventure,Sci-Fi A thief, who steals corporate secrets through ... Christopher Nolan Leonardo DiCaprio, Joseph Gordon-Levitt, Ellen... 2010 148 8.8 1583625 292.57 74.0
نکته بسیار مهم در کد بالا این است که حتما باید شرط خود را مثل من درون پرانتز بگذارید تا پایتون بداند اولویت شرط ها با کدام است. البته روش بهتری برای انجام این کار نیز وجود دارد؛ در pandas متدی به نام isin وجود دارد که مشخص می کند یک مقدار درون ستون خاصی وجود دارد یا خیر. ما با این متد می توانیم حضور کارگردان خاصی را در یک فیلم بررسی کنیم:
movies_df[movies_df['director'].isin(['Christopher Nolan', 'Ridley Scott'])].head()
طبیعتا با اجرای این کد نتیجه زیر را می گیریم:
Title rank genre description director actors year runtime rating votes revenue_millions metascore Prometheus 2 Adventure,Mystery,Sci-Fi Following clues to the origin of mankind, a te... Ridley Scott Noomi Rapace, Logan Marshall-Green, Michael Fa... 2012 124 7.0 485820 126.46 65.0 Interstellar 37 Adventure,Drama,Sci-Fi A team of explorers travel through a wormhole ... Christopher Nolan Matthew McConaughey, Anne Hathaway, Jessica Ch... 2014 169 8.6 1047747 187.99 74.0 The Dark Knight 55 Action,Crime,Drama When the menace known as the Joker wreaks havo... Christopher Nolan Christian Bale, Heath Ledger, Aaron Eckhart,Mi... 2008 152 9.0 1791916 533.32 82.0 The Prestige 65 Drama,Mystery,Sci-Fi Two stage magicians engage in competitive one-... Christopher Nolan Christian Bale, Hugh Jackman, Scarlett Johanss... 2006 130 8.5 913152 53.08 66.0 Inception 81 Action,Adventure,Sci-Fi A thief, who steals corporate secrets through ... Christopher Nolan Leonardo DiCaprio, Joseph Gordon-Levitt, Ellen... 2010 148 8.8 1583625 292.57 74.0
حالا می توانیم شروط خود را بسیار پیچیده تر هم داشته باشیم. به طور مثال فرض کنید فیلم هایی را می خواهیم که بین سال های 2005 تا 2010 ساخته شده باشند و امتیازشان بالای 8 باشد اما از نظر فروش پایین تر از صدک ۲۵ اُم باشند. باز هم از شما می خواهم که سعی کرده و خودتان به این مسئله پاسخ بدهید و بعدا به پاسخ من نگاه کنید:
movies_df[ ((movies_df['year'] >= 2005) & (movies_df['year'] <= 2010)) & (movies_df['rating'] > 8.0) & (movies_df['revenue_millions'] < movies_df['revenue_millions'].quantile(0.25)) ]
با اجرای این کد می توانیم چنین نتیجه ای را بگیریم:
Title rank genre description director actors year runtime rating votes revenue_millions metascore 3 Idiots 431 Comedy,Drama Two friends are searching for their long lost ... Rajkumar Hirani Aamir Khan, Madhavan, Mona Singh, Sharman Joshi 2009 170 8.4 238789 6.52 67.0 The Lives of Others 477 Drama,Thriller In 1984 East Berlin, an agent of the secret po... Florian Henckel von Donnersmarck Ulrich Mühe, Martina Gedeck,Sebastian Koch, Ul... 2006 137 8.5 278103 11.28 89.0 Incendies 714 Drama,Mystery,War Twins journey to the Middle East to discover t... Denis Villeneuve Lubna Azabal, Mélissa Désormeaux-Poulin, Maxim... 2010 131 8.2 92863 6.86 80.0 Taare Zameen Par 992 Drama,Family,Music An eight-year-old boy is thought to be a lazy ... Aamir Khan Darsheel Safary, Aamir Khan, Tanay Chheda, Sac... 2007 165 8.5 102697 1.20 42.0
اگر یادتان باشد صدک ۲۵ ام در فروش برابر با 17.4 بود. از کجا یادتان باشد؟ زمانی که با متد describe کار می کردیم تمام صدک ها یا همان percentile ها را مشاهده کردیم. زمانی که بخواهیم به این صدک دسترسی داشته باشیم باید از متد quantile استفاده کرده و آن را با دو رقم اعشار، یعنی 0.25، پاس بدهیم. در نتیجه بالا می بینید که فقط ۴ فیلم در کل DataFrame ما وجود دارند که این شرط بر آن ها صدق می کند.
اجرای توابع روی DataFrame
گردش روی DataFrame های مختلف مانند گردش در حلقه ها کاملا ممکن است اما از نظر سرعت بسیار طول خواهد کشید. عملیات گردش معمولا سریع انجام می شوند اما DataFrame هایی که موجود است معمولا بسیار بزرگ هستند (صدها هزار ردیف داده) و به همین خاطر است که مثل حلقه های معمولی سریع انجام نمی شوند.
راه حل این مشکل استفاده از متدی به نام apply است؛ این متد تعریف یک تابع دیگر را گرفته و روی داده های ما اجرا می کند. ما به جای اینکه بخواهیم روی تک تک داده ها گردش کرده و عملیات خاصی را انجام بدهیم، می توانیم از این تابع برای روش های ساده تر استفاده کنیم. به طور مثال من می خواهم فیلم هایی که امتیاز بالاتری از ۸ را دارند به عنوان فیلم خوب (good) و بقیه فیلم ها را به عنوان فیلم بد (bad) در نظر بگیرم. در نهایت ستون جدیدی را مخصوص این داده ها تعریف می کنیم. برای این کار باید تابع دلخواه خودتان را بنویسید. من از این تابع استفاده می کنم:
def rating_function(x): if x >= 8.0: return "good" else: return "bad"
همانطور که می بینید این تابع یک پارامتر به نام x دارد. x به صورت خودکار توسط متد apply به آن پاس داده خواهد شد بنابراین:
movies_df["rating_category"] = movies_df["rating"].apply(rating_function) movies_df.head(2)
در نظر داشته باشید که نباید برای نام تابع rating_function از علامت پرانتز استفاده کنید بلکه فقط باید نام تابع را به آن پاس بدهید. در کد بالا می بینید که ما ستون جدیدی به نام rating_category را ایجاد کرده ایم که یا مقدار good و یا bad را خواهد داشت. ستون اضافه شده چطور خواهد بود؟ ما ستون rating را انتخاب کرده و سپس متد rating_function را روی آن اجرا کرده ایم و نتیجه آن (good یا bad) را به ستون جدید داده ایم. با اجرای کد بالا نتیجه زیر را می گیرید:
Title rank genre description director actors year runtime rating votes revenue_millions metascore rating_category Guardians of the Galaxy 1 Action,Adventure,Sci-Fi A group of intergalactic criminals are forced ... James Gunn Chris Pratt, Vin Diesel, Bradley Cooper, Zoe S... 2014 121 8.1 757074 333.13 76.0 good Prometheus 2 Adventure,Mystery,Sci-Fi Following clues to the origin of mankind, a te... Ridley Scott Noomi Rapace, Logan Marshall-Green, Michael Fa... 2012 124 7.0 485820 126.46 65.0 bad
در نظر داشته باشید که این کار هنوز هم گردش حساب می شود چرا که متد apply تمام مقادیر ستون rating را به تابع rating_function داده و یک series جدید برمی گرداند اما تفاوت اینجاست که دیگر بین تک تک مقادیر تک تک ستون ها گردش نمی کنیم.
برای استفاده از متد apply الزامی به استفاده از توابع عادی نیست بلکه می توانید از anonymous functions (توابع ناشناس) نیز استفاده کنید. به طور مثال من تابع بالا را به صورت یک تابع lambda نوشته ام:
movies_df["rating_category"] = movies_df["rating"].apply(lambda x: 'good' if x >= 8.0 else 'bad') movies_df.head(2)
اجرای این کد نتیجه ای مانند همان نتیجه قبلی را خواهد داشت:
Title rank genre description director actors year runtime rating votes revenue_millions metascore rating_category Guardians of the Galaxy 1 Action,Adventure,Sci-Fi A group of intergalactic criminals are forced ... James Gunn Chris Pratt, Vin Diesel, Bradley Cooper, Zoe S... 2014 121 8.1 757074 333.13 76.0 good Prometheus 2 Adventure,Mystery,Sci-Fi Following clues to the origin of mankind, a te... Ridley Scott Noomi Rapace, Logan Marshall-Green, Michael Fa... 2012 124 7.0 485820 126.46 65.0 bad
حالا که می دانیم این روش نیز هنوز هم گردش است، شاید بپرسید که مزیت استفاده از apply نسبت به گردش ساده بین این مقادیر چیست؟ متد apply از پکیج pandas در پس زمینه مانند حلقه های عادی نیست بلکه از قابلیتی به نام vectorization استفاده می کند. این قابلیت به ما اجازه می دهد که به جای اعمال یک داده روی تک تک اعضای لیست، عملیات ها را روی کل آرایه اجرا می کند. اگر با natural language processing (پردازش طبیعی زبان، به اختصار NLP) کار کرده باشید حتما استفاده های مختلف apply را در آن دیده اید.
آشنایی خلاصه با Plotting
Plot ها نمودار های گرافیکی خاصی هستند که معمولا رابطه بین دو یا چند متغیر را نشان می دهند. همانطور که گفتم کتابخانه pandas می تواند با کتابخانه Matplotlib یکپارچه شود و با کمک آن plot های خوبی را رسم کنیم. در این روش می توانید مستقیما DataFrames ها یا series های خود را به Matplotlib تزریق کرده و plot آماده را تحویل بگیرید. طبیعتا برای انجام این کار و در قدم اول باید کتابخانه Matplotlib را نصب کنیم:
pip install matplotlib
پس از نصب باید این پکیج را وارد اسکریپت خود کنید:
import matplotlib.pyplot as plt
plt.rcParams.update({'font.size': 20, 'figure.figsize': (10, 8)}) # set font and plot size to be larger
من در کد بالا می خواستم اندازه فونت را کمی بیشتر کنم بنابراین مقدار ۲۰ را به آن داده ام. همچنین figure.figsize نیز که مشخص کننده اندازه نمودار است را به صورت ۱۰ در ۸ تعیین کرده ایم.
نکته: برای ترسیم نمودار های مختلف در Matplotlib باید بر اساس داده های موجود، نمودار های مرتبط با آن ها را رسم کنید و برای هر داده ای از نمودار های صحیح استفاده کنید. به عنوان قانونی کلی به یاد داشته باشید که برای داده های رسته ای از Bar Chart (نمودار میله ای) و Boxplot ها استفاده کنید. برای متغیرهای پیوسته نیز از Histograms (هیستوگرام) و Scatterplots و Line graph و Boxplots استفاده کنید.
فرض کنید ما بخواهیم رابطه بین امتیاز (rating) و میزان فروش (revenue) را در یک plot مقایسه کنیم. تنها کاری که باید برای رسم چنین plot ای انجام بدهیم، صدا زدن تابع plot روی DataFrame خودمان است:
movies_df.plot(kind='scatter', x='rating', y='revenue_millions', title='Revenue (millions) vs Rating');
طبیعتا برای درک این کد و جزئیات آن باید با کتابخانه Matplotlib آشنا باشید که دوره جداگانه ای لازم خواهد داشت. با اجرای کد بالا نتیجه زیر را دریافت می کنید:
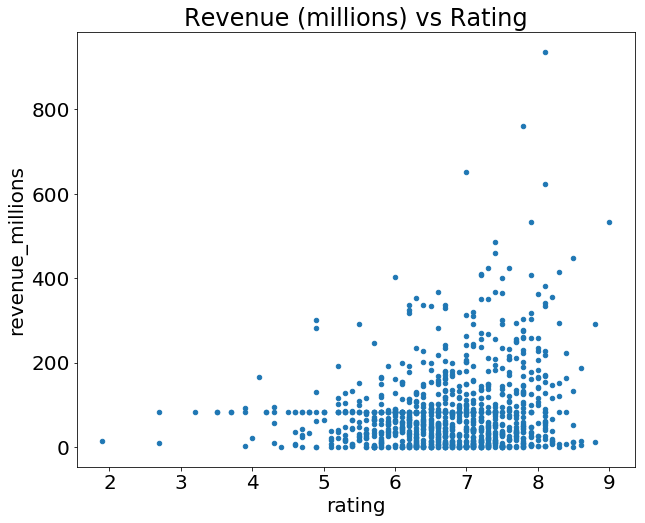
در ضمن در کد بالا از علامت ; در انتهای دستور استفاده کرده ایم. این علامت خطای نگارشی نیست بلکه برای جلوگیری از چاپ شدن خروجی های جانبی (<matplotlib.axes._subplots.AxesSubplot at 0x26613b5cc18>) می باشد.
همچنین برای رسم یک Histogram بر اساس یک ستون خاص می توانیم دستور plot را روی همان ستون خاص صدا بزنیم:
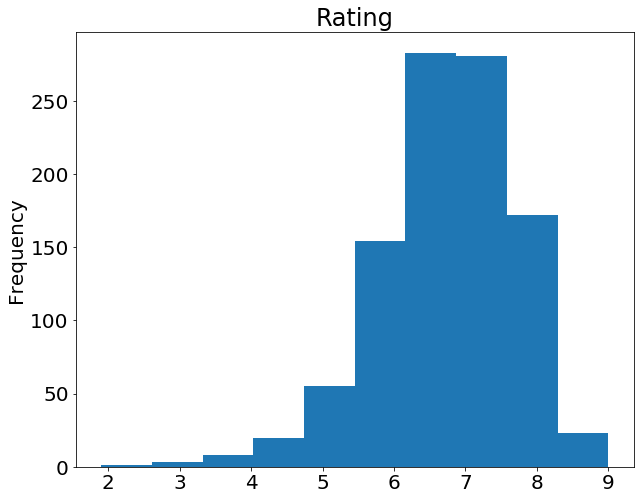
movies_df['rating'].plot(kind='hist', title='Rating');
با اجرای این کد نتیجه زیر را دریافت می کنیم:
همچنین روشی برای نمایش گرافیکی متد describe و دامنه بین چارکی وجود دارد که به آن Boxplot می گوییم. بگذارید یک بار دیگر به کد زیر توجه کنیم:
movies_df['rating'].describe()
با اجرای کد بالا گزارشی از ستون rating دریافت می کردیم:
count 1000.000000 mean 6.723200 std 0.945429 min 1.900000 25% 6.200000 50% 6.800000 75% 7.400000 max 9.000000 Name: rating, dtype: float64
این مقادیر بین چارکی می توانند به شکل زیر و به صورت گرافیکی نمایش داده شوند:
movies_df['rating'].plot(kind="box");
با اجرای این کد نتیجه زیر را دریافت می کنید:
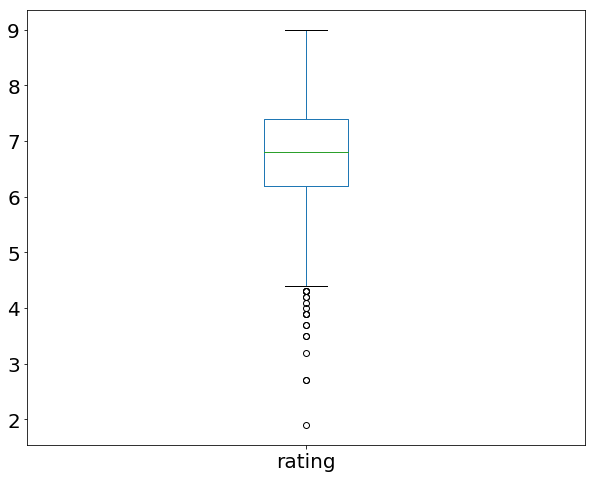
این یک نوع نمودار خاص است و برای خواندن آن می توانید از راهنمای زیر کمک بگیرید:

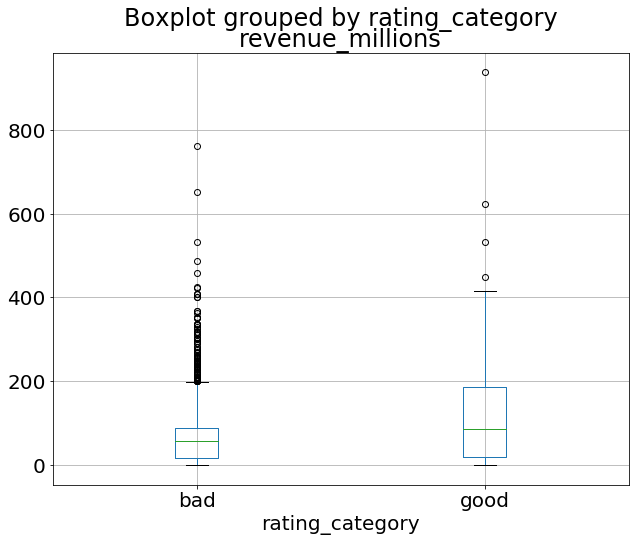
همچنین ما می توانیم با ترکیب داده های همبسته و داده های رسته ای، یک Boxplot از میزان فروش (ستون revenue_millions) فیلم ها را به دست آوریم. ما می توانیم از ستون ساخته شده توسط خودمان (Rating Category) برای دسته بندی داده ها استفاده کنیم:
movies_df.boxplot(column='revenue_millions', by='rating_category');
با اجرای این کد نتیجه زیر را دریافت می کنید:
امیدوارم این مقاله شروعی برای فعالیت شما در حوزه تحلیل داده باشد.
منبع: وب سایت learndatasci










در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.
در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.
در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.
در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.
در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.
در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.
در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.
در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.