نصب پایگاه داده PostgreSQL و پیکربندی آن
?How to Install and Configure the PostgreSQL Database

یکی از پایگاه های داده بسیار مشهور در دنیا PostgreSQL است که شباهت بسیار زیادی به MySQL دارد (مثلا هر دو از زبان SQL استفاده می کنند) اما قابلیت های آن نسبت به MySQL بسیار بیشتر است و همچنین آمادگی بیشتری برای کار با داده های بسیار بزرگ را دارد. ما در این مقاله قصد داریم به فرآیند نصب این پایگاه داده و پیکربندی آن بپردازیم. توجه داشته باشید که برای کار با PostgreSQL باید زبان SQL را یاد بگیرید، بنابراین این مقاله آموزش PostgreSQL نیست بلکه آموزش نصب و پیکربندی اولیه آن به همراه چند مثال می باشد.
سطح مقاله: این مقاله برای افرادی در نظر گرفته شده است که با پایگاه های داده رابطه ای (relational database) مانند MySQL آشنا هستند و می دانند «جدول» یا «روابط بین داده» چیست. بنابراین با اینکه بسیاری از مفاهیم را توضیح می دهیم، ممکن است مطالعه این مقاله برای افراد مبتدی دشوار باشد. به طور مثال ما از ابزار های گرافیکی (GUI) برای مدیریت پایگاه داده استفاده نمی کنیم بلکه با ترمینال کار خواهیم کرد.
در حال حاضر PostgreSQL پیشرفته ترین پایگاه داده رابطه ای و متن باز (open source) در دنیا است. بله، PostgreSQL به طور کامل متن باز است و حدود ۳۰ سال است که در حال توسعه می باشد بنابراین پختگی کاملی دارد. در ابتدا نحوه نصب و پیکربندی PostgreSQL را برای کاربران ویندوز و لینوکس توضیح می دهم و سپس وارد کدنویسی آن می شویم.
نصب PostgreSQL در ویندوز
برای نصب PostgreSQL باید ابتدا به آدرس postgresql.org/download رفته و ویندوز را انتخاب کنید. با کلیک روی Windows به صفحه دیگری منتقل می شوید که از شما می خواهد از وب سایت EDB نسخه خاصی را انتخاب کنید. اگر نمی توانید این صفحه را پیدا کنید مستقیما به این لینک مراجعه کنید. در این صفحه روی گزینه download کلیک کنید تا دانلود شروع شود.
زمانی که فایل نصبی دانلود شد آن را باز کنید و روی گزینه next کلیک کنید تا اینکه فرآیند نصب شروع شود. فرآیند نصب بسیار ساده است، در عین حال من بخش های مهم آن را در تصاویر زیر آورده ام:
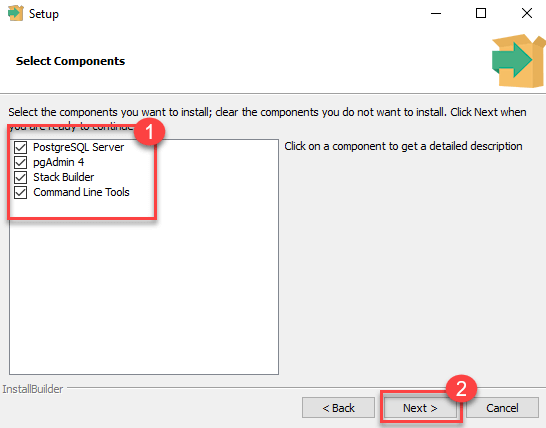
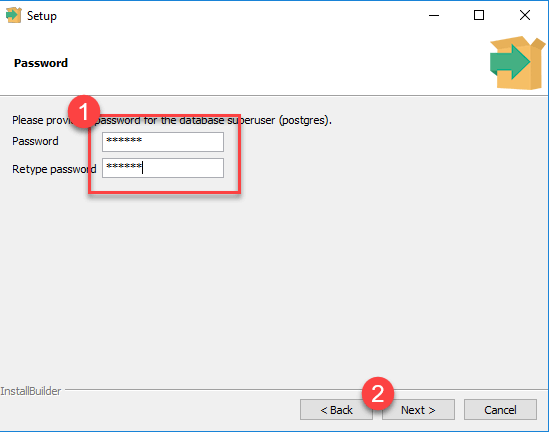
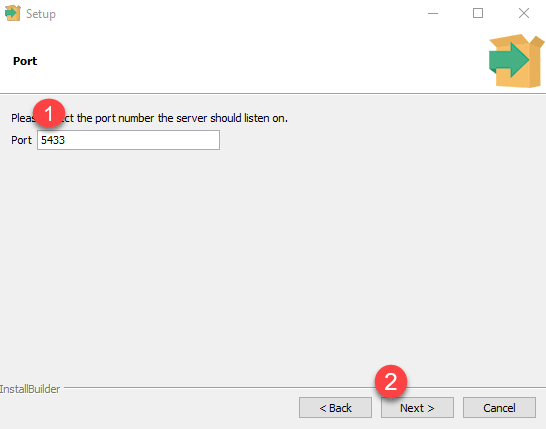
پس از آنکه فرآیند نصب پایان یافت بهتر است تیک گزینه Stack Builder را غیرفعال کرده و سپس finish را بزنید. در حال حاضر می بینید که برنامه مدیریت گرافیکی pgAdmin در برنامه های نصب شده در سیستم شما موجود می باشد.
همانطور که گفتم من شخصا از GUI ها استفاده نمی کنم و با ترمینال پیکربندی را انجام می دهیم. اگر شما می خواهید از pgAdmin استفاده کنید که کارتان تمام شده است و بخش «پیکربندی» از این مقاله را با pgAdmin انجام خواهید داد اما اگر می خواهید مثل من از ترمینال (CMD یا PowerShell یا Git for windows و غیره) استفاده کنید باید مسیر نصب PostgreSQL را به PATH سیستم خود اضافه کنید.
انجام این کار بسیار آسان است؛ از منوی استارت عبارت Edit the system environment variables را جست و جو کنید. اولین گزینه نمایش داده شده را که همین نام را دارد انتخاب کنید. از پنجره باز شده به سربرگ advanced رفته و روی گزینه Environment Variables کلیک کنید:
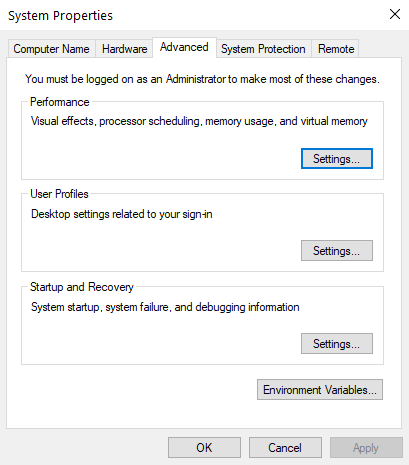
با انتخاب این گزینه صفحه ای باز می شود که در آن دو باکس وجود دارد. باکس دوم به نام System variables را ببنید. درون آن یک گزینه به نام path وجود دارد:
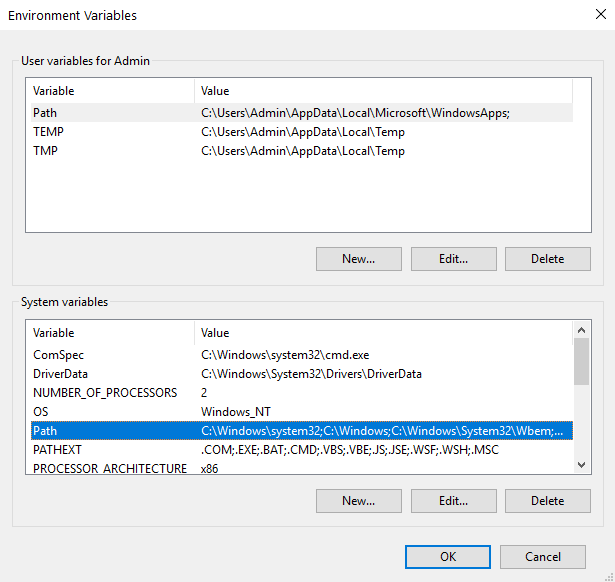
روی آن دو بار کلیک کنید تا باز شود. حالا از پنجره باز شده روی new کلیک کرده و مسیر نصب PostgreSQL را به آن اضافه کنید:
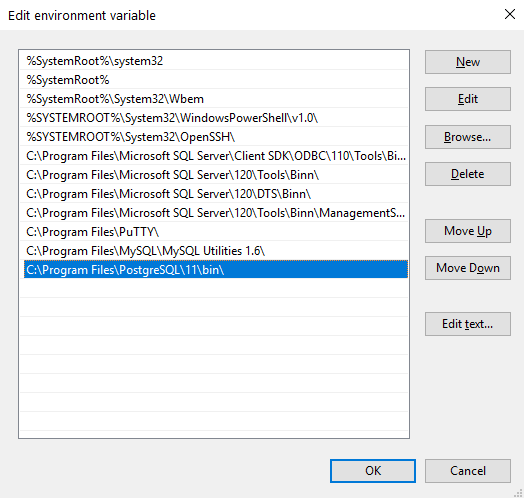
حالا به بخش «پیکربندی PostgreSQL» از این مقاله بروید.
نصب PostgreSQL در Ubuntu
برای نصب PostgreSQL در اوبونتو دو راه دارید؛ یا از repository های خود Ubuntu استفاده کنید یا از repository های PostgreSQL استفاده کنید. من روش اول را پیشنهاد می کنم. برای نصب از repository های خود Ubuntu دستورات زیر را به ترتیبی که می بینید در ترمینال اجرا کنید (خطوطی که با # شروع می شوند کامنت هستند و برای توضیحات نوشته شده اند):
# به روز رسانی لیست پکیج ها sudo apt update # PostgreSQL نصب آخرین نسخه از sudo apt install postgresql postgresql-contrib
پکیج postgresql-contrib ویژگی های بیشتری را در اختیار شما قرار می دهد تا بتوانید راحت تر با PostgreSQL کار کنید.
بسیار پیش می آید که یکی از این دو repository از دیگری به روز تر باشد، مثلا repository های PostgreSQL به روز تر از repository های Ubuntu باشند اما تفاوت به روز رسانی در آن ها بسیار کم است (در حد اعشار پکیج) بنابراین اصلا نیازی به نصب از روش دوم نیست. در عین حال اگر به دلیلی نیاز دارید که آخرین نسخه موجود تا آخرین رقم اعشار را دریافت کنید احتمالا repository های PostgreSQL به روز تر باشند (در عین حال خودتان بررسی کنید):
# به سیستم خودمان repo اضافه کردن sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list' # وارد کردن کلید امضا wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add - # به روز رسانی لیست پکیج ها sudo apt-get update # PostgreSQL نصب آخرین نسخه از sudo apt-get -y install postgresql
هر دو روش نسخه ای به روز شده را برایتان نصب می کنند گرچه من روش اول را پیشنهاد می کنم.
ورود به PostgreSQL با ترمینال
همانطور که گفتم من از ابزار های گرافیکی (GUI) برای مدیریت پایگاه داده PostgreSQL استفاده نمی کنم بنابراین اگر از کاربران ویندوز هستید مطمئن باشید که مسیر نصب PostgreSQL را به PATH سیستم اضافه کرده اید. همچنین پیشنهاد می کنم از ترمینال Git for Windows یا CMDER استفاده کنید.
برای پیکربندی PostgreSQL باید با مفاهیم اصلی این پایگاه داده برای مدیریت فرآیند احراز هویت آشنا باشیم. پایگاه داده PostgreSQL از مفهومی به نام roles (به معنی «نقش») استفاده می کند. پس از نصب PostgreSQL، این پایگاه داده حساب کاربری ویندوز یا لینوکس شما را به عنوان صاحب پایگاه داده می شناسد و به صورت خودکار یک حساب کاربری به نام postgres برایتان ساخته است که حساب مدیریتی و اصلی است. شما می توانید با نام حساب کاربری ویندوز/لینوکس یا با نام postgres وارد حساب PostgreSQL شوید. توجه داشته باشید که این دو، دو حساب جداگانه هستند.
کاربران ویندوز
در حال حاضر کاربران ویندوز احتمالا می توانند با اجرای دستور زیر وارد حسابشان شوند:
psql
در صورتی که خطا دریافت کردید با فلگ U- نام حساب کاربریتان را نیز مشخص کنید:
psql -U userName
البته به جای username باید نام کاربری حساب ویندوز یا postgres را قرار بدهید. با اجرای دستور بالا از شما خواسته می شود که رمز عبور خود را وارد کنید. این همان رمز عبوری است که هنگام نصب مشخص کرده بودید. تبریک می گویم حالا وارد حساب کاربری خود شده اید.
نکته مهم برای کاربران ویندوز: در بسیاری از نسخه های PostgreSQL پس از نصب، یک آیکون به نام SQL shell (psql) نمایش داده می شود. این یک برنامه خاص است که به شما اجازه می دهد وارد حساب PostgreSQL خود شده و دستوراتتان را در آن اجرا کنید. اگر این آیکون را دارید نیازی به ورود به صورت دستی به حساب کاربری (به روش بالا) نیست و می توانید روی آن کلیک کرده و دستورات این آموزش را در آن اجرا کنید. زمانی که این برنامه را باز می کنید ابتدا از شما آدرس سرور خواسته می شود. ما می خواهیم به صورت محلی کار کنیم بنابراین بدون وارد کردن هیچ مقداری، enter بزنید. در مرحله بعدی از شما خواسته می شود نام پایگاه داده خود را وارد کنید. باز هم بدون وارد کردن هیچ مقداری enter بزنید تا به پایگاه داده پیش فرض (به نام postgres) متصل شویم. برای سوالات بعدی (پورت و نام کاربری) نیز همان مقادیر پیش فرض را تایید کنید. اگر یادتان باشد ما یک رمز عبور را تعیین کرده بودیم. این مورد نیز از شما خواسته می شود که باید وارد کنید و در نهایت وارد پایگاه داده PostgreSQL می شوید.
کاربران اوبونتو
کاربران ubuntu اگر به صورت خالی دستور psql را اجرا کنند به خطایی شبیه به خطای زیر برخورد می کنند:
psql: error: FATAL: role "amir" does not exist
البته به جای amir نام کاربری شما قرار خواهد داشت. برای حل این مشکل بهتر است از حساب کاربری postgres وارد شویم:
sudo -i -u postgres
با اجرای این دستور از حساب کاربری ساده لینوکس خود به حساب postgres وارد می شوید:
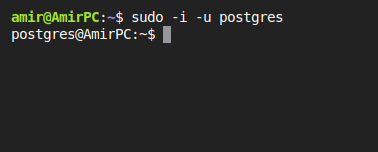
در همین حالت دستور psql را اجرا کنید. با این کار وارد پایگاه داده PostgreSQL خود می شوید. عبارت postgres در بخش prompt نشان دهنده نام پایگاه داده ای است که به صورت پیش فرض به آن متصل شده ایم. توجه داشته باشید که در حال حاضر درون psql هستید که یک پوسته برای PostgreSQL می باشد. برای خروج از این حالت می توانید دستور q/ را در ترمینال اجرا کرده یا از کلید های Ctrl + D استفاده کنید.
مشکل این روش این است که ما حساب کاربری لینوکس خودمان را تغییر می دهیم (وارد یک حساب دیگر می شویم)! من پیشنهاد می کنم به جای روش بالا از دستور زیر برای ورود به حساب کاربری خود استفاده کنید:
sudo -u postgres psql
همانطور که قبلا هم گفتم postgres نام حساب کاربری است که به صورت خودکار برایمان ساخته شده است. البته در ادامه یک role جدید ساخته و با آن وارد خواهیم شد.
تعریف role جدید
قبلا هم توضیح دادم که postgres حساب کاربری اصلی و ادمین ما است. ما می توانیم با دستور createuser یک کاربر جدید را ایجاد کنیم:
sudo -u postgres createuser --interactive
با اجرای این دستور در ترمینال از شما دو سوال پرسیده می شود: اول اینکه نام role جدید باید چه باشد و دوم اینکه آیا این کاربر جدید یا role جدید ادمین باشد؟ من یک نقش جدید به نام amir را ایجاد کرده ام که ادمین یا superuser است:
Enter name of role to add: amir Shall the new role be a superuser? (y/n) y
البته برای اینکه کاربران لینوکس بتوانند با چنین کاربری وارد پایگاه داده شوند باید یک حساب کاربری لینوکس با همین نام داشته باشند. من از لینوکس استفاده می کنم و نام حساب کاربری ام در کامپیوتر خودم amir است. به همین دلیل چنین role ای را ایجاد کرده ام تا بتوانم به راحتی با آن متصل شوم.
حالا برای اتصال به یک پایگاه داده با این role جدید چه کار باید کرد؟ به جای اجرای sudo -u برای تغییر حساب کاربری لینوکس خود، کافی است به صورت خالی از psql استفاده کنیم:
psql -d postgres
زمانی که دستور psql را صدا می زنیم، حساب کاربری به صورت خودکار همان نام حساب کاربری کامپیوتر شما (حساب لینوکس) است که برای من amir می باشد. از طرفی psql به دنبال پایگاه داده ای با همین نام می گردد که در مثال ما وجود ندارد. برای حل این مشکل من فلگ d- را به آن پاس داده ام و سپس نام postgres را پاس داده ام. این پایگاه داده به صورت خودکار برای ما ساخته شده است بنابراین به آن متصل می شویم.
دستورات ابتدایی PSQL
اگر در ترمینال خود (در حالی که درون PSQL هستید) دستور help را تایپ کرده و اجرا کنید نتیجه زیر را دریافت می کنید:
postgres=# help You are using psql, the command-line interface to PostgreSQL. Type: \copyright for distribution terms \h for help with SQL commands \? for help with psql commands \g or terminate with semicolon to execute query \q to quit
همانطور که می بینید مجموعه دستورات مختلفی در PSQL وجود دارد. دستور copyright\ باعث نمایش قوانین کپی رایت می شود، دستور h\ باعث نمایش دستورات SQL پشتیبانی شده می شود، دستور ?\ باعث نمایش دستورات خاص psql می شود، دستور g\ باعث اجرای کوئری نوشته شده توسط شما می شود و q\ نیز باعث خروج از psql می شود.
ما می خواهیم در این بخش با دستورات psql آشنا شویم که معمولا مجموعه ای از دستورات مدیریتی به شکل زیر هستند (با اجرای دستور ?\ آن ها را می بینید):
General \copyright show PostgreSQL usage and distribution terms \crosstabview [COLUMNS] execute query and display results in crosstab \errverbose show most recent error message at maximum verbosity \g [(OPTIONS)] [FILE] execute query (and send results to file or |pipe); \g with no arguments is equivalent to a semicolon \gdesc describe result of query, without executing it \gexec execute query, then execute each value in its result \gset [PREFIX] execute query and store results in psql variables \gx [(OPTIONS)] [FILE] as \g, but forces expanded output mode \q quit psql \watch [SEC] execute query every SEC seconds Help \? [commands] show help on backslash commands \? options show help on psql command-line options \? variables show help on special variables \h [NAME] help on syntax of SQL commands, * for all commands // بقیه لیست دستورات
اولین دستور از این بخش، دستور l\ (حرف کوچک L) است که باعث می شود تمام پایگاه های داده موجود برایمان لیست شود. من با اجرای این دستور چنین نتیجه ای می گیرم:
List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+----------+----------+---------+---------+----------------------- postgres | postgres | UTF8 | C.UTF-8 | C.UTF-8 | template0 | postgres | UTF8 | C.UTF-8 | C.UTF-8 | =c/postgres + | | | | | postgres=CTc/postgres template1 | postgres | UTF8 | C.UTF-8 | C.UTF-8 | =c/postgres + | | | | | postgres=CTc/postgres (3 rows)
همانطور که می بینید ما سه پایگاه داده داریم که به صورت خودکار برای ما ساخته شده اند: postgres و template0 و template1.
حذف و ساخت پایگاه داده جدید
من دوست دارم یک پایگاه داده جدید را برای خودمان بسازیم. شما می توانید هر نامی را برایش انتخاب کنید اما من نام roxo را انتخاب می کنم:
CREATE DATABASE roxo;
یادتان باشد که ما در حال نوشتن دستور SQL هستیم بنابراین حتما باید علامت ; را در انتهای آن قرار بدهید در غیر این صورت دستور اجرا نمی شود. با اجرای این دستور نتیجه زیر را می گیرید:
postgres=# CREATE DATABASE roxo; CREATE DATABASE
همانطور که می بینید پس از اجرای دستور، عبارت CREATE DATABASE برایمان برگردانده شده است که یعنی عملیات موفق آمیز بوده است. حالا دوباره دستور l\ را اجرا می کنیم تا لیست پایگاه های داده را دوباره ببینیم:
List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+----------+----------+---------+---------+----------------------- postgres | postgres | UTF8 | C.UTF-8 | C.UTF-8 | roxo | postgres | UTF8 | C.UTF-8 | C.UTF-8 | template0 | postgres | UTF8 | C.UTF-8 | C.UTF-8 | =c/postgres + | | | | | postgres=CTc/postgres template1 | postgres | UTF8 | C.UTF-8 | C.UTF-8 | =c/postgres + | | | | | postgres=CTc/postgres (4 rows)
همانطور که می بینید پایگاه داده roxo نیز به این لیست اضافه شده است. همانطور که می بینید ویژگی هایی مانند کدبندی (Encoding) پایگاه داده به صورت خودکار انتخاب شده اند. شاید شما بخواهید خودتان چنین مسائلی را به صورت ریزتر مشخص کنید. در این حالت باید از دستور کامل ساخت پایگاه داده استفاده نمایید. برای تمرین کردن این موضوع بیایید ابتدا پایگاه داده جدید roxo را حذف کنیم و سپس یک بار دیگر آن را با گزینه های کامل بسازیم.
PostgreSQL از زبان SQL پشتیبانی می کند بنابراین عملیات ساخت پایگاه داده یا حذف آن تفاوتی با MySQL ندارد. ما می توانیم بگوییم:
DROP DATABASE databaseName;
طبیعتا باید به جای databaseName نام پایگاه داده خودتان را قرار بدهید. استفاده از دستور DROP بدین شکل اصولی نیست چرا که اگر پایگاه داده مشخص شده توسط شما وجود نداشته باشد، PostgreSQL یک خطا را به ما می دهد. به طور مثال:
DROP DATABASE AA;
پایگاه داده ای به نام AA وجود ندارد بنابراین با اجرای این دستور چنین خطایی می گیریم:
ERROR: database "aa" does not exist
روش اصولی تر حذف پایگاه داده بدین شکل است:
DROP DATABASE IF EXISTS AA;
در این دستور گفته ایم اگر پایگاه داده ای با نام AA وجود داشت، آن را حذف کن. از آنجایی که چنین پایگاه داده ای وجود ندارد یک notice (هشدار) به ما برگردانده می شود و خطا نمی گیریم:
NOTICE: database "aa" does not exist, skipping
پیشنهاد می کنم تا حد ممکن از ایجاد خطا در پایگاه داده خود دوری کنید. حالا می توانیم پایگاه داده roxo را حذف کنیم:
DROP DATABASE IF EXISTS roxo;
نکته: معمولا قرارداد است که دستورات SQL را با حروف بزرگ می نویسند و من هم پیشنهاد می کنم شما نیز این کار را انجام بدهید، گرچه هیچ اجباری در آن نیست.
با اجرای کد بالا چنین نتیجه ای را می گیریم:
DROP DATABASE
همانطور که گفتم اگر عین دستور برایمان برگردانده شد یعنی عملیات موفقیت آمیز بوده است. برای بررسی این موضوع یک بار دیگر دستور l\ را اجرا می کنیم:
List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+----------+----------+---------+---------+----------------------- postgres | postgres | UTF8 | C.UTF-8 | C.UTF-8 | template0 | postgres | UTF8 | C.UTF-8 | C.UTF-8 | =c/postgres + | | | | | postgres=CTc/postgres template1 | postgres | UTF8 | C.UTF-8 | C.UTF-8 | =c/postgres + | | | | | postgres=CTc/postgres (3 rows)
حالا دیگر هیچ خبری از roxo نیست. این بار برای ساخت roxo از دستور ساده CREATE DATABASE استفاده نمی کنیم چرا که این دستور تمام مقادیر پیش فرض را قبول می کند اما من می خواهم تمام مقادیر را خودم تعیین کنم. ساختار کامل دستور CREATE DATABSE بدین شکل است:
CREATE DATABASE db_name OWNER = role_name TEMPLATE = template ENCODING = encoding LC_COLLATE = collate LC_CTYPE = ctype TABLESPACE = tablespace_name CONNECTION LIMIT = max_concurrent_connection
بیایید این گزینه ها را با هم بررسی کنیم:
- باید به جای db_name همان نام کاربری خود را قرار بدهید. نام پایگاه های داده یکتا هستند بنابراین نمی توانید نامی را انتخاب کنید که قبلا انتخاب شده است.
- OWNER همان صاحب پایگاه داده است. نام role مورد نظرتان را برایش قرار بدهید. این مقدار به صورت پیش فرض postgres است.
- TEMPLATE در این بخش می توانید یک قالب را مشخص کنید تا پایگاه داده جدید بر اساس آن ساخته شود.
- ENCODING یا کدبندی نیز که حتما برایتان آشنا است و به صورت پیش فرض روی UTF8 تنظیم شده است.
- دستورات دسته COLLATE مربوط به مسائل فرهنگی هستند. مثلا LC_COLLATE نحوه مرتب شدن رشته ها را مشخص می کند، LC_CTYPE دسته بندی الفبا را مشخص می کند (حروف بزرگ و کوچک و غیره)، LC_MESSAGES پیام خطاهای خروجی را مشخص می کند، LC_MONETARY واحد پول را مشخص می کند، LC_NUMERIC فرمت اعداد را مشخص می کند و LC_TIME فرمت زمان پایگاه داده را مشخص می کند. اطلاعات بیشتر در documentation رسمی PostgreSQL موجود است. بسیاری از این قابلیت ها برای زبان فارسی پشتیبانی نمی شود.
- TABLESPACE محل ذخیره سازی جدول ها و ایندکس ها و امثال آن ها است.
- CONNECTION LIMIT تعداد اتصالات واحد به این پایگاه داده را مشخص می کند که به صورت پیش فرض روی ۱- (یعنی بی نهایت) قرار دارد.
من پیشنهاد می کنم مقادیر Collate را تغییر ندهید چرا که به صورت پیش فرض روی C.UTF8 است و از زبان های مختلف پشتیبانی می کند. من فقط می خواهم صاحب پایگاه داده را تغییر داده و روی role جدیدی که ساخته بودیم (amir) قرار بدهم:
postgres=# CREATE DATABASE roxo postgres-# OWNER = amir postgres-# ENCODING = UTF8 postgres-# ;
همانطور که می بینید من برای خوانایی کد ها آن ها را در خطوط مختلف نوشته ام. تنها در خط آخر علامت نقطه ویرگول (;) را گذاشته ام که مشخص کننده پایان یافتن دستور است و دستور را اجرا می کند. حالا با اجرای دستور l\ می توانید نتیجه را مشاهده کنید:
List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+----------+----------+---------+---------+----------------------- postgres | postgres | UTF8 | C.UTF-8 | C.UTF-8 | roxo | amir | UTF8 | C.UTF-8 | C.UTF-8 | template0 | postgres | UTF8 | C.UTF-8 | C.UTF-8 | =c/postgres + | | | | | postgres=CTc/postgres template1 | postgres | UTF8 | C.UTF-8 | C.UTF-8 | =c/postgres + | | | | | postgres=CTc/postgres (4 rows)
اتصال به یک پایگاه داده و تعیین رمز برای role ها
ما تا این لحظه به سرور پایگاه داده وصل شده بودیم (محیط PSQL) اما در ظاهر به هیچ پایگاه داده خاصی در این سرور متصل نشده ایم. البته در اصل زمانی که دستور psql را اجرا می کنیم، PostgreSQL به دنبال پایگاه داده ای با نام کاربری موجود (postgres) می گردد بنابراین به آن متصل بوده ایم. بگذارید شفاف تر توضیح بدهم. ما تا این لحظه از دستور زیر برای اتصال به سرور پایگاه داده استفاده کرده ایم:
sudo -u postgres psql
این دستور حساب کاربری سیستم عامل ما را به postgres تغییر می دهد (این حساب کاربری به صورت خودکار ساخته می شود) و سپس psql را در قالب آن اجرا می کنیم بنابراین به دنبال پایگاه داده ای به نام postgres می گردیم.
برای اتصال به یک پایگاه داده دو روش وجود دارد. اگر در محیط PSQL هستید باید از دستور c\ استفاده کرده و سپس نام پایگاه داده را بیاورید. مثلا:
\c roxo
با اجرای این دستور نتیجه زیر برایمان برگردانده می شود:
You are now connected to database "roxo" as user "postgres".
این نتیجه می گوید که شما با حساب کاربری postgres به پایگاه داده roxo متصل شده اید. با اینکه صاحب پایگاه داده roxo فردی به نام amir است اما در نظر داشته باشید که حساب postgres حساب اصلی و ادمین کل پایگاه های داده است. چرا با حساب postgres به این پایگاه داده متصل شده ایم؟ به دلیل اینکه ما هنوز با دستور sudo -u وارد حسابمان می شویم و طبیعتا چنین دستوری باعث می شود از حساب postgres استفاده کنیم.
روش دوم برای اتصال به یک پایگاه داده این است که از همان ابتدا با role دیگری وارد بشویم:
psql -d roxo
فلگ d- مخفف database یا پایگاه داده است و مشخص می کند که دقیقا به چه پایگاه داده ای متصل شویم. هر زمان که خواستید ببینید به چه پایگاه داده ای متصل هستید به بخش prompt از ترمینال خود نگاه کنید:
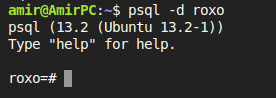
سوالی که پیش می آید این است که اگر پایگاه داده remote بود (روی سرور دیگری قرار داشت) چطور باید به آن متصل شویم؟ در این حالت از دستور زیر پیروی کنید:
psql -h localhost -p 5432 -U amir roxo
h- نشان دهنده host است. من در سیستم شخصی خودم هستم بنابراین از localhost استفاده کرده ام اما در اصل باید IP سرور مورد نظرتان را در این بخش قرار بدهید. فلگ p- مشخص کننده پورت است که من همان پورت پیش فرض را روی آن گذاشته ام (5432). فلگ U- نیز مشخص کننده user یا همان role است که من amir را انتخاب کرده ام و نهایتا نام پایگاه داده را می آورید که من roxo را انتخاب کرده ام.
در حال حاضر role من (amir) رمز عبور ندارد چرا که من از لینوکس استفاده می کنم بنابراین اگر دستور بالا را در سیستم خودم اجرا کنم دچار مشکل می شوم. برای حل این مشکل ابتدا وارد سرور پایگاه داده شوید (از هر role ای که می خواهید استفاده کنید)، سپس در محیط PSQL دستور password username\ را اجرا کنید و به جای username نام کاربری یا همان نقش مورد نظرتان را قرار دهید. مثلا:
postgres=# \password amir Enter new password: Enter it again:
همانطور که در این کد می بینید من برای amir رمز عبور تعیین کرده ام. دو بار از من خواسته شده است که رمز را وارد کنم و پس از آن رمز جدید تنظیم می شود. زمانی که روی سیستم شخصی خود هستید psql از سیستم ident استفاده می کند به همین خاطر نیازی به رمز نیست.
حالا می توانید این دستور را اجرا کنید:
psql -h localhost -p 5432 -U amir roxo
این بار از شما رمز خواسته می شود و پس از وارد کردن آن وارد پایگاه داده می شوید.
ساخت جدول جدید در پایگاه داده
ساخت جدول در یک پایگاه داده PostgreSQL تفاوت زیادی با MySQL ندارد چرا که باز هم با زبان SQL انجام می شود.ساختار کلی دستور ساخت جدول در SQL به شکل زیر است:
CREATE TABLE IF NOT EXISTS table_name ( column1 datatype(length) column_contraint, column2 datatype(length) column_contraint, column3 datatype(length) column_contraint, table_constraints );
به جای table_name نام مورد نظرتان برای جدول را قرار می دهید، به جای column1 نام ستون اول را قرار می دهید، به جای datatype از نوع داده مورد نظرتان استفاده می کنید و نهایتا به جای column_contraint یک constraint از زبان SQL را انتخاب می کنید (مانند Primary Key و Not null و Unique و امثال آن). شما می توانید با constraint ها در این مقاله آشنا شوید. این مسئله ارتباطی به PostgreSQL ندارد بنابراین اگر با زبان SQL آشنا نیستید حتما باید آن را یاد بگیرید. به طور مثال datatype های پشتیبانی شده در PostgreSQL در documentation رسمی آن موجود است و می توانید آن ها را مطالعه کنید. در عین حال من به صورت بسیار خلاصه constraint های موجود در PostgreSQL را توضیح می دهم:
NOT NULL: این constraint بدین معنی است که ستون مورد نظر نمی تواند خالی باشد. اگر ستونی از جدول شما NOT NULL را نداشته باشد، در هنگام وارد کردن مقادیر در آن جدول می توانید مقدار آن ستون را خالی بگذارید اما اگر NOT NULL وجود داشته باشد و بخواهید آن ستون را خالی بگذارید با مشکل روبرو می شوید.
UNIQUE: این constraint بدین معنی است که هیچ دو ردیفی نمی توانند مقداری یکسان با این ستون داشته باشند. مثلا اگر ستون email در یک جدول را از نوع Unique (به معنی «یکتا») بگذاریم دیگر ممکن نیست دو ردیف با یک ایمیل یکسان در پایگاه داده ما وجود داشته باشند. حتی اگر کاربری بخواهد با ایمیلی یکسان ثبت نام کند اجازه نخواهد داشت چرا که این مقدار تکراری در پایگاه داده ثبت نخواهد شد.
PRIMARY KEY: هر جدول فقط می تواند یک PRIMARY KEY داشته باشد. استفاده اصلی PRIMARY KEY ها این است که ستونی از جدول را به عنوان کلید اصلی تعیین کنید. از این به بعد می توانید از طریق مقادیر این ستون به سرعت به داده هایتان دسترسی داشته باشید چرا که ستون PRIMARY KEY به صورت خودکار ایندکس می شود. معمولا از ستون id یا user_id به عنوانPRIMARY KEY استفاده می شود.
CHECK: این constraint باعث می شود که داده های یک ستون داده ها را بر اساس یک شرط قبول کند. چه شرطی؟ هر شرطی که شما تعیین کنید. CHECK پس از پردازش شرط به true یا false تبدیل می شود و فقط زمانی که true باشد داده های جدید اجازه ثبت شدن در پایگاه داده را دارند. به طور مثال اگر بخواهیم مطمئن شویم افراد سال تولد خود را بیهوده انتخاب نمی کنند (مثلا ۲۰۰ سال پیش را انتخاب نمی کنند) می توانیم یک CHECK را برای این ستون تعیین کنیم:
CREATE TABLE employees ( id SERIAL PRIMARY KEY, first_name VARCHAR (50), last_name VARCHAR (50), birth_date DATE CHECK (birth_date > '1900-01-01'), joined_date DATE CHECK (joined_date > birth_date), salary numeric CHECK(salary > 0) );
در اینجا می بینید که من شرط گذاشته ام که ستون birth_date همیشه باید بیشتر از سال ۱۹۰۰ میلادی باشد در غیر این صورت داده ها ثبت نشده و خطا می گیریم.
FOREIGN KEY: این constraint برای ایجاد روابط بین جداول استفاده می شود و باعث می شود داده ای در یک جدول حتما در جدول دیگری نیز وجود داشته باشد. برخلاف PRIMARY KEY ها شما می توانید چندین FOREIGN KEY را در یک جدول داشته باشید. بحث روابط بین جدول ها از مباحث SQL است و اختصاصی به PostgreSQL ندارد بنابراین توضیحات بیشتری را در این زمینه نمی دهم.
فرض کنید من بخواهم در پایگاه داده roxo جدولی به نام accounts (به معنی «حساب ها») را بسازم. این جدول باید فیلد های زیر را داشته باشد:
- user_id که آیدی کاربر است.
- username که نام حساب کاربری او است.
- password که رمز عبور کاربر است.
- email که ایمیل کاربر است.
- created_on زمان ساخت حساب کاربری را نشان می دهد.
- last_login که آخرین زمان ورود به حساب کاربری را مشخص می کند.
با این حساب ابتدا به پایگاه داده roxo متصل شده و سپس دستور SQL زیر را بنویسید:
CREATE TABLE accounts ( user_id serial PRIMARY KEY, username VARCHAR ( 50 ) UNIQUE NOT NULL, password VARCHAR ( 50 ) NOT NULL, email VARCHAR ( 255 ) UNIQUE NOT NULL, created_on TIMESTAMP NOT NULL, last_login TIMESTAMP );
از آنجایی که من مطمئن بودم جدول accounts از قبل وجود ندارد دیگر نیازی به نوشتن IF NOT EXISTS نیست. همانطور که می بینید نوع داده ستون اول serial است. serial یک نوع داده خاص است که توسط PostgreSQL معرفی شده است و در SQL عادی وجود ندارد. در واقع اصلا نوع داده ای به نام serial وجود ندارد، بلکه PostgreSQL در پشت صحنه کار هایی را برای آن انجام می دهد. البته از نسخه ۱۰ به بعد پیشنهاد می شود از serial استفاده نکنید چرا که در برخی اوقات رفتار عجیبی دارد. به جای آن می توانید از identity استفاده نمایید:
CREATE TABLE accounts ( user_id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY, username VARCHAR ( 50 ) UNIQUE NOT NULL, password VARCHAR ( 50 ) NOT NULL, email VARCHAR ( 255 ) UNIQUE NOT NULL, created_on TIMESTAMP NOT NULL, last_login TIMESTAMP );
serial روش قدیمی تولید ستون id در PostgreSQL است و بعضا رفتار های عجیبی از خود نشان می دهد بنابراین بهتر است به جای آن از روش بالا استفاده کنید. برای username از VARCHAR استفاده کرده ام و آن را به ۵۰ کاراکتر محدود کرده ام. طبیعتا username باید یکتا باشد بنابراین Unique را نیز به همراه NOT NULL برایش قرار داده ایم. بقیه موارد مانند TIMESTAMP ساده و بر اساس استاندارد SQL هستند. با اجرای دستور بالا عبارت CREATE TABLE برایتان برگردانده می شود که یعنی همه چیز با موفقیت انجام شده است. برای مشاهده جدول ساخته شده در محیط PSQL کافی است دستور d\ را اجرا کنید. نتیجه به شکل زیر خواهد بود:
List of relations Schema | Name | Type | Owner --------+----------------------+----------+------- public | accounts | table | amir public | accounts_user_id_seq | sequence | amir (2 rows)
به همین سادگی یک جدول را ساخته ایم و همانطور که می بینید نامش accounts است. شاید بپرسید جدول دوم (accounts_user_id_seq) از کجا آمده است؟ باید بدانید که accounts_user_id_seq اصلا جدول نیست. اگر به ستون type نگاه کنید می بینید که این یک شیء sequence است. اشیاء sequence در PostgreSQL برای تولید مقدار جدید برای ستون id ما استفاده می شوند که با GENERATED AS IDENTITY مشخص کرده بودیم. در واقع دستور d\ تمام table ها و view ها و index ها و sequence ها و امثال آن ها را یکجا نمایش می دهد. اگر می خواهید فقط جدول ها را ببینید باید دستور dt\ را اجرا کنید:
List of relations Schema | Name | Type | Owner --------+----------+-------+------- public | accounts | table | amir (1 row)
همانطور که می بینید این بار فقط جدول ها نمایش داده شده اند که در حال حاضر یکی است. البته هنوز نمی توانیم اطلاعات ستون های جدول accounts را به صورت جزئی ببینیم. برای حل این مسئله باید نام جدول را به دستور d\ پاس بدهیم. مثلا با اجرای دستور d accounts\ چنین نتیجه ای را می گیریم:
Table "public.accounts" Column | Type | Collation | Nullable | Default ------------+-----------------------------+-----------+----------+------------------------------ user_id | integer | | not null | generated always as identity username | character varying(50) | | not null | password | character varying(50) | | not null | email | character varying(255) | | not null | created_on | timestamp without time zone | | not null | last_login | timestamp without time zone | | | Indexes: "accounts_pkey" PRIMARY KEY, btree (user_id) "accounts_email_key" UNIQUE CONSTRAINT, btree (email) "accounts_username_key" UNIQUE CONSTRAINT, btree (username)
حالا علاوه بر نام ستون ها و اطلاعات مربوط به آن ها index های این جدول را نیز مشاهده می کنید (یک ایندکس متعلق به PRIMARY KEY و دو ایندکس متعلق به UNIQUE).
ویرایش جدول ها
برای ویرایش جدول ها از دستور ALTER استفاده می کنیم که ساختار زیر را دارد:
ALTER TABLE table_name action;
در این دستور باید به جای action کار خاصی را انجام بدهید. مثلا فرض کنید من بخواهم نام جدول را از accounts به user_accounts تغییر بدهم. برای انجام این کار می گوییم:
ALTER TABLE accounts RENAME TO user_accounts;
البته من کد بالا را اجرا نمی کنم چرا که قصد تغییر نام جدول را ندارم. بیایید مثالی دیگر را بررسی کنیم؛ اگر بخواهید یک ستون جدید را به جدول مورد نظر اضافه کنید بدین شکل عمل می کنید:
ALTER TABLE table_name ADD COLUMN column_name datatype column_constraint;
به جای table_name نام جدول، به جای column_name نام ستون، به جای datatype نوع داده و به جای column_constraint از constraint های دلخواه استفاده کنید. مثلا من در کد زیر دو ستون را به جدول فرضی customers اضافه می کنم:
ALTER TABLE customers ADD COLUMN fax VARCHAR, ADD COLUMN email VARCHAR;
روش های بسیار زیادی برای ویرایش جدول ها و ویژگی های آن ها وجود دارد.
وارد کردن داده در جدول با فایل SQL
PostgreSQL با زبان SQL کار می کند بنابراین برای وارد کردن داده در آن می توانیم از دستور SQL زیر استفاده کنیم:
INSERT INTO table_name(column1, column2, …) VALUES (value1, value2, …);
این کار بسیار ساده است و نیازی به توضیح ندارد (انتظار می رود که شما با زبان SQL آشنا باشید).
اما اگر بخواهیم داده ها را از یک فایل SQL وارد جدول خود کنیم چطور؟ من شخصا فایل SQL ندارم اما وب سایتی به نام mockaroo وجود دارد که به شما داده های جعلی زیادی می دهد. این داده ها برای تمرین هستند و در فرمت هایی مانند SQL یا JSON و غیره موجود می باشند بنابراین با انواع پایگاه های داده سازگاری دارند. من به این وب سایت رفته بر اساس جدول accounts فیلد های مورد نظرم را تعریف می کنیم و نهایتا ۱۰۰۰ کاربر آماده را از آن دانلود می کنم.
شما می توانید در صورت نیاز این فایل را ویرایش کنید چرا که یک فایل SQL ساده است اما در نهایت باید به psql رفته و در آنجا از دستور i\ (مخفف import یا وارد کردن) استفاده کنید. مثلا:
\i downloads/MOCK_DATA.sql
با این کار هزار نفر به جدول شما اضافه می شوند البته به شرطی که داده های درون MOCK_DATA.sql دقیقا با جدول شما یکسان باشند، در غیر این صورت خطا دریافت می کنید.
گرفتن بکاپ از پایگاه داده
بسیاری از اوقات پیش می آید که می خواهیم از یک پایگاه داده بکاپ بگیریم. برای انجام این کار یک روش بسیار ساده وجود دارد و آن هم استفاده از دستور pg_dump است. کافی است ترمینال خود را باز کرده و دستور زیر را در آن اجرا کنید:
pg_dump roxo > database_backup.sql
مطمئن باشید که برای اجرای دستور بالا درون حالت psql نیستید. دستور pg_dump نام یک پایگاه داده را می گیرد که من roxo را به آن پاس داده ام. خروجی این دستور متن SQL برای بازسازی پایگاه داده است بنابراین با اپراتور < آن را درون یک فایل sql با نام دلخواه ذخیره کرده ام.
اگر از کاربران ویندوز هستید ممکن است نیاز باشد ابتدا به آدرس نصب PostgreSQL (مثلا C:\Program Files\PostgreSQL\13\bin) بروید و ترمینال را در آنجا باز کنید. سپس دستوری به شکل زیر را در آن اجرا کنید:
pg_dump -U amir -F p roxo > c:\pgbackup\roxo.sql
فلگ F- مشخص می کند که تایپ بکاپ چه باشد؟ من حرف p را به آن داده ام که یعنی یک فایل SQL را به ما تحویل بدهد. همچنین اگر می خواهید از تمام پایگاه های داده بکاپ بگیرید به جای pg_dump از دستور pg_dumpall استفاده کنید.
ما به این روش از بکاپ گیری SQL dump می گوییم چرا که در آن تمام محتوای پایگاه داده را به صورت یک فایل SQL استخراج کرده ایم اما نوعی دیگر از بکاپ به نام File system level backup نیز وجود دارد. در این نوع بکاپ ما تمام فایل های پایگاه داده را در بخش دیگری کپی می کنیم اما بر اساس توضیحات documentation رسمی این روش معمولا پیشنهاد نمی شود چرا که دو مشکل اساسی دارد:
- برای گرفتن بکاپ بدین شکل حتما باید سرور پایگاه داده به طور کامل خاموش (shut down) شود.
- امکان بکاپ گیری از بخش های خاص وجود ندارد بلکه باید از همه چیز بکاپ بگیرید. در صورتی که بخواهید بخشی از یک فایل را کپی کنید به مشکلات متعددی برخورد خواهید کرد.
روش سوم گرفتن بکاپ، Point-in-Time Recovery است که با ترکیب روش File system level backup و یکی از Log های PostgreSQL به نام WAL انجام می شود. این روش بکاپ گیری پیچیده است و فقط برای برنامه های بسیار بزرگ کاربرد دارد.
نکات امنیتی سرور
زمانی که PostgreSQL را روی سروری نصب می کنید مسائلی امنیتی وجود دارد که بهتر است حتما رعایت کنید. این مسائل امنیتی هم مربوط به برنامه شما می شوند و هم مربوط به تظیمات سرور PostgreSQL.
دسترسی remote : اولین مسئله قطع دسترسی remote به سرور پایگاه داده است. یعنی چه؟ یعنی غیر از خود سرور کسی نباید اجازه داشته باشد با IP به پایگاه داده شما متصل شود. البته در برخی از موارد به چنین چیزی نیاز خواهید داشت اما در اکثر مواقع بهتر است آن را غیرفعال کنید. این کار از فایل postgresql.conf انجام می شود. حتی اگر به remote access نیاز دارید، دسترسی به پایگاه های داده template1 و PostgreSQL را غیرفعال کنید. در حالت عادی اتصال remote باید غیرفعال باشد اما اگر اینطور نبود، از فایل پیکربندی conf به دنبال خصوصیت listen_addresses بگردید و آن را روی localhost قرار بدهید:
#listen_addresses = 'localhost' # what IP address(es) to listen on;
پس از اعمال تغییرات حتما سرور را یک بار ریستارت کنید.
تفاوت هش و رمزنگاری: هش ها (مثلا MD5) یک طرفه هستند اما رمزنگاری (encryption) مثل AES دو طرفه هستند بنابراین اگر قرار است مقداری در پایگاه داده هیچ گاه مشاهده نشود، حتما از هش به جای رمزنگاری استفاده کنید. یک مثال خوب در این زمینه رمز عبور کاربران است که باید هش شود.
پورت های دسترسی: در صورتی که نیاز دارید remote access (دسترسی از کامیپوتر های دیگر به سرور پایگاه داده) را فعال کنید حتما آن را به یک پورت خاص محدود کنید.
فایل pg_hba.conf: این فایل تنظیمات مربوط به اتصال به پایگاه داده را در خود دارد. این فایل معمولا پنج خصوصیت دارد: TYPE (نوع میزبان)، DATABASE (نام پایگاه داده)، USER (نام کاربر یا همان یوزرنیم)، ADDRESS (آدرس IP) و METHOD (متد رمزنگاری). این خصوصیات با ساختار زیر در این فایل قرار دارند:
# local DATABASE USER METHOD [OPTIONS] # host DATABASE USER ADDRESS METHOD [OPTIONS] # hostssl DATABASE USER ADDRESS METHOD [OPTIONS] # hostnossl DATABASE USER ADDRESS METHOD [OPTIONS] # hostgssenc DATABASE USER ADDRESS METHOD [OPTIONS] # hostnogssenc DATABASE USER ADDRESS METHOD [OPTIONS]
تنظیمات مختلفی در این فایل وجود دارد. به طور مثال وادار کردن افراد به اتصال از طریق SSL (اتصال امن و رمزنگاری شده) یکی موارد قابل تنظیم در این بخش است. همچنین از طریق این فایل می توانید remote access را نیز غیرفعال کنید. با این حساب شما می توانید بر اساس نیاز های خود این فایل را ویرایش کنید. پیشنهاد می کنم قبل از ویرایش آن حتما از آن یک بکاپ بگیرید.
به روز رسانی: زمانی که سرور خود را راه اندازی کردید تازه ابتدای کار است. شما باید همیشه حواستان به update های جدید از تیم توسعه PostgreSQL باشد چرا که در بسیاری از اوقات شاهد یک patch برای تصحیح یک مشکل امنیتی هستیم. به عنوان یک قانون کلی همیشه بهتر است که به نسخه بعدی آپدیت کنید تا امنیت پایگاه داده بالاتر باشد.
Logging: عبارت logging به معنی ثبت وقایع رخ داده در پایگاه داده است. فعال کردن logging در سیستم هایتان باعث می شود متوجه بشوید در پشت صحنه داده هایتان چه می گذرد، چه کسانی و با چه IP هایی به پایگاه داده دسترسی پیدا کرده اند، چه درخواست هایی دریافت کرده اید و الی آخر. روش های مختلفی برای log کردن وقایع در PostgreSQL وجود دارد که می توانید آن را از documentation رسمی مطالعه کنید. البته افزونه هایی مانند pgaudit نیز وجود دارد که به شما اجازه می دهد در زمینه خاصی logging را فعال کنید.
امیدوارم با استفاده از این مقاله توانسته باشید اولین سرور PostgreSQL خود را نصب و راه اندازی کنید.
منبع: وب سایت digitalocean









در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.