مرورگرها چطور کار میکنند؟
?How Browsers Work
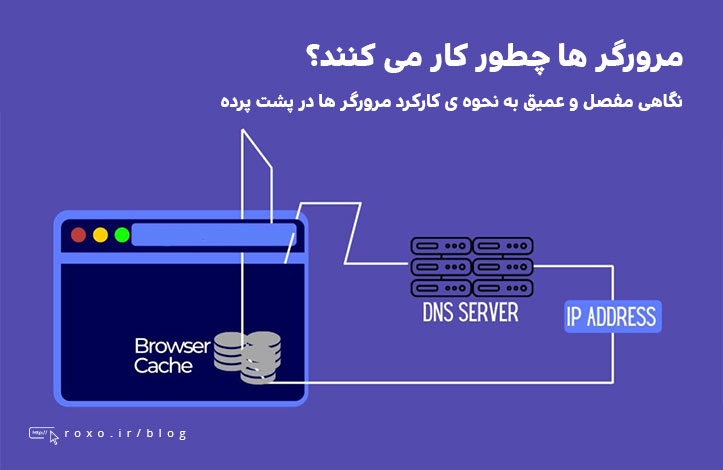
همه ما هر روز از مرورگرها استفاده می کنیم اما آیا با نحوه کارکرد آن ها آشنا هستید؟ بین زمانی که شما به عنوان یک کاربر آدرس سایتی را وارد می کنید و زمانی که آن وب سایت روی صفحه نمایش داده می شود چه اتفاقی می افتد؟ شاید این مسئله برای کاربران عادی مهم نباشد اما ما به عنوان توسعه دهندگان وب باید با این موضوع آشنا باشیم بنابراین در این مقاله به صورت مفصل به این موضوع می پردازیم.
نمایش یک وب سایت در یک مرورگر ۵ مرحله اصلی دارد که هر مرحله زیر مرحله های خودش را نیز دارد. من این مراحل را با نام انگلیسی شان می آورم چرا که واژه های تخصصی هستند و بعدا در هر قسمت اطلاعات مورد نیازشان را توضیح می دهم.
- Navigation (ناوبری)
- ◦ DNS Lookup
- ◦ TCP 3-way handshake
- ◦ TLS negotiation
- Fetching (بارگیری)
- ◦ درخواست HTTP
- ◦ پاسخ HTTP
- Parsing (تجزیه کدها)
- ◦ ساخت DOM tree
- ◦ ساخت CSSOM tree
- ◦ ترکیب دو درخت قبلی به render tree
- ◦ Preload Scanner
- ◦ کامپایل کردن جاوا اسکریپت
- ◦ ساخت Accessibility Tree
- Rendering (نمایش)
- ◦ Critical Rendering Path
- ◦ Layout
- ◦ Paint
- ◦ Compositing
- Finalising (تکمیلی)
- ◦ اشغال جاوا اسکریپت
- ◦ تعامل کاربر با صفحه
قبل از اینکه بخواهیم به سراغ توضیح هر کدام از این موارد برویم باید با مفاهیمی پیش زمینه ای آشنا باشیم. بدون این مفاهیم نمی توانید بسیاری از این مراحل را درک کنید بنابراین بهتر است مقاله را از ابتدا تا انتها مطالعه کنید.
مدل های شبکه
وظیفه مدل ها این است که نحوه انتقال داده ها در شبکه را توضیح بدهند. مدل های مختلفی برای شبکه ها وجود دارد اما یکی از آن ها آنچنان مشهور است که حتی افرادی با تجربه کمتر نیز آن را می شناسند و آن مدل OSI است. مدل OSI مخفف Open Systems Interconnection یا «مدل اتصال متقابل سامانه های باز» یک مدل مفهومی از تعاملات شبکه است که توسط سازمان بین المللی استانداردسازی تعریف و ارائه شده است و از دهه ۱۹۸۰ به عنوان یک مدل استاندارد مورد قبول تمام سازمان های بزرگ قرار گرفته است.
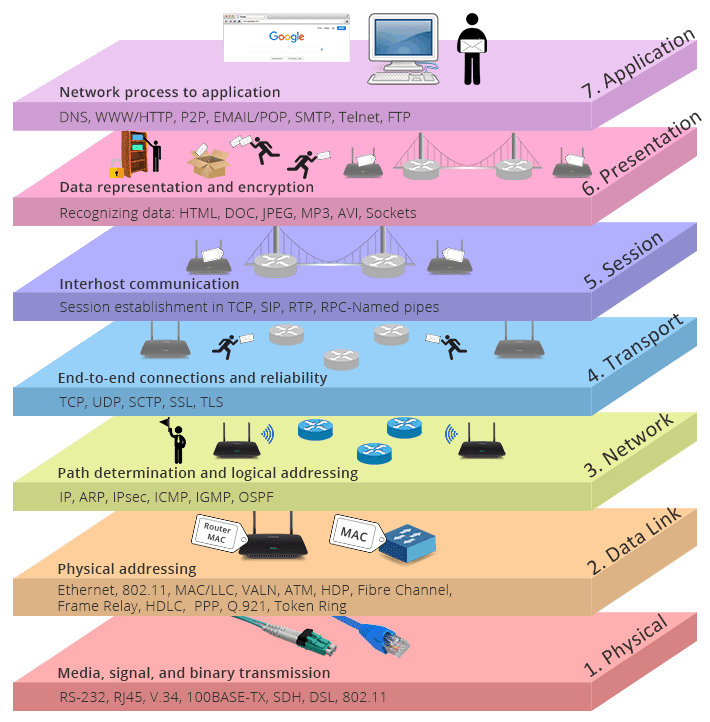
اینترنت مدرن و امروزی ما بر اساس مدل OSI نیست بلکه بر اساس نسخه ای ساده تر از آن که TCP/IP نام دارد ساخته شده است اما هنوز هم درک مدل OSI به شما کمک می کند تا تعاملات یک شبکه را درک کنید. من این هفت لایه را به صورت خلاصه برایتان توضیح می دهم.
لایه برنامه (Application layer): این لایه تنها لایه ای است که به صورت مستقیم با داده های کاربر تعامل دارد. نرم افزار هایی مانند مرورگرهای وب یا کلاینت های ایمیل از این لایه برای شروع تعاملات خود استفاده می کنند.
لایه ارائه (Presentation layer): این لایه مسئول آماده سازی داده هایی است که لایه هفتم (لایه برنامه) از آن ها استفاده خواهد کرد. به زبان دیگر لایه ششم داده ها را برای نرم افزار ها قابل ارائه می کند. این لایه مسئول translation (ترجمه) و encryption (رمزگذاری) و compression (فشرده سازی داده) است.
لایه نشست (Session layer): این لایه ای است که مسئولیت باز کردن و بستن تعاملات بین دو دستگاه را بر عهده دارد. در واقع لایه پنجم، کانال های تعاملی را می سازد که session یا نشست نام دارند. از نظر فنی تر به زمان بین باز شدن اتصال تا بسته شده آن یک نشست می گویند (انگار دو دستگاه با هم یک نشست داشته باشند).
لایه انتقال (Transport layer): لایه انتقال مسئول تعامل مستقیم (end-to-end) بین دو دستگاه است. این لایه داده ها را از لایه پنجم (نشست) گرفته، آن را به بخش های کوچکتری به نام segment تقسیم می کند و در نهایت به لایه سوم پاس می دهد. لایه انتقال در دستگاه دریافت کننده وظیفه دارد داده های ارسالی که قطعه قطعه شده اند (segment ها) را دریافت کرده و آن ها را دوباره سرهم کند تا لایه نشست بتواند آن ها را دریافت کند.
لایه شبکه (Network layer): لایه شبکه مسئول انتقال داده بین دو شبکه متفاوت است. در صورتی که دو دستگاه فرضی ما که در حال ارتباط هستند روی یک شبکه قرار داشته باشند، نیازی به لایه شبکه نیست اما در غیر این صورت به این لایه نیاز داریم.
لایه پیوند داده (Data Link layer): لایه پیوند داده دقیقا مانند لایه شبکه است (مسئولیت انتقال داده ها را دارد) با این تفاوت که کارایی آن برای دستگاه هایی است که روی یک شبکه قرار دارند.
لایه فیزیکی (Physical layer): این پایین ترین لایه است و شامل تجهیزات فیزیکی در فرآیند انتقال داده می شود مانند کابل ها، سوییچ ها و غیره. همچنین این همان لایه ای است که در آن داده ها به شکل bit stream (رشته ای بسیار طولانی از اعداد صفر و یک) در می آیند.
برای مطالعه بیشتر در اینباره به مقاله مدل OSI در روکسو مراجعه کنید.
نکته: مدل شبکه (network model) یک بحث مفهومی برای درک تعاملات شبکه است در حالی که پروتکل ها (protocols) قوانین محکمی هستند که در لایه های مختلف این مدل ها حضور دارند.
از طرفی مدل دیگری نیز به نام TCP/IP وجود دارد که نسبت به OSI ساده تر است. از این مدل برای معماری دنیای اینترنت استفاده می شود و قوانینی را تعریف می کند که توسط تمام تعاملات شبکه پیروی می شوند.
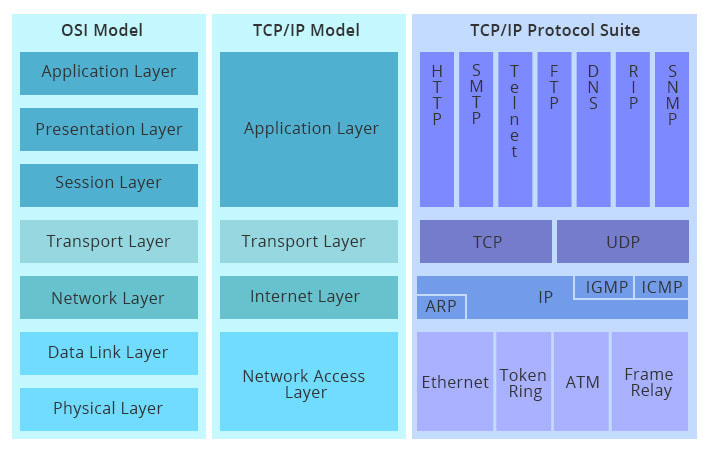
امروزه هر داده ای که بخواهد از یک برنامه به برنامه دیگر ارسال شود باید بین لایه های این شبکه (تصویر بالا) بالا و پایین برود. تعداد دفعات جا به جایی داده بین این لایه ها به عوامل مختلفی بستگی دارد. تصویر زیر این پروسه را بین کلاینت (مرورگر) و سرور نمایش می دهد:
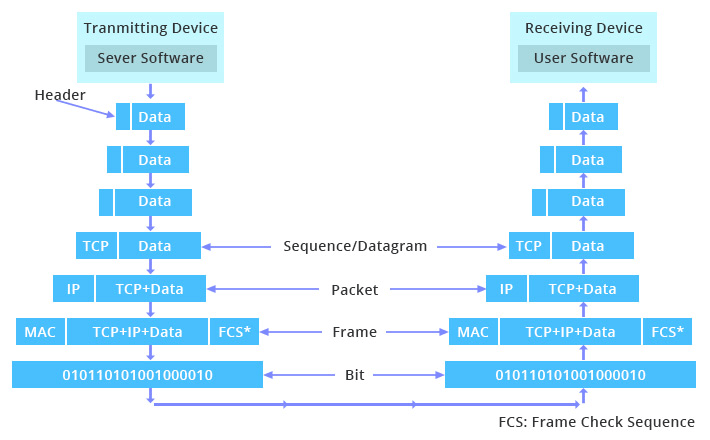
زمانی که کاربر درخواست اتصال به یک سایت را ارسال می کند این درخواست ابتدا به application layer یا لایه برنامه می رود و سپس از آنجا به لایه های پایین تر منتقل می شود و در هر لایه پردازش های لازم روی آن صورت می گیرد. در نهایت داده به physical layer یا لایه فیزیکی شبکه می رسد تا اینکه سرور یا هر دستگاه دیگری آن را دریافت می کند. پس از آن داده دوباره ارسال شده و بین این لایه ها جا به جا می شود تا زمانی که به برنامه یا اسکریپت سرور می رسد. ماشین ها در دنیای وب بدین شکل تعامل می کنند.
نگاهی انتزاعی به مرورگر
در این بخش می خواهیم نگاهی کلی به ساختار یک مرورگر داشته باشیم تا درک کنیم یک مرورگر از چه اجزایی ساخته شده است. من در طول این مقاله به قسمت های مختلفی از این بخش اشاره خواهم کرد بنابراین مطالعه آن مهم است.
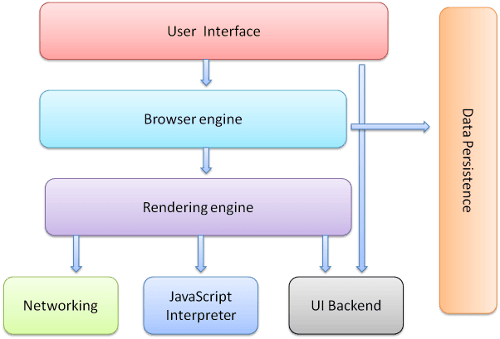
۱. رابط کاربری: رابط کاربری یا user interface همان نمای بصری مرورگر برای شما است. مثلا نوار آدرس، دکمه های صفحه قبل و بعد، منوی بوکمارک ها و دیگر عناصر بصری همگی بخشی از رابط کاربری هستند البته به غیر از window یا همان بخشی که سایت در آن نمایش داده می شود.
۲. موتور مرورگر: مسئول مدیریت عملیات های مختلفی است که بین رابط کاربری و موتور نمایش اتفاق می افتد.
۳. موتور نمایش: موتور نمایش یا rendering engine مسئول نمایش محتوای درخواست شده است. مثلا اگر محتوای درخواست شده HTML باشد، این موتور HTML و CSS و جاوا اسکریپت را گرفته و آن ها را حل کرده و به صورت بصری به شما نشان می دهد.
۴. شبکه: این کامپوننت مسئول مدیریت درخواست های HTTP و دیگر مباحث شبکه است.
۵. بک اند رابط کاربری: این backend برای ایجاد ویجت های مختلف و مدیریت رابط کاربری ساخته شده است و به هیچ پلتفرم خاصی (ویندوز، لینوکس و ...) وابسته نیست بلکه در پس زمینه از متد های سیستم عامل استفاده می کند.
۶. مفسر جاوا اسکریپت: این کامپوننت مسئولیت تجزیه و اجرای کدهای جاوا اسکریپت را دارد.
۷. ذخیره سازی داده: مرورگرها نیاز دارند تا انواع مختلف داده ها مانند کوکی ها را ذخیره کنند و از مکانیسم هایی مانند localStorage و IndexedDB نیز پشتیبانی می کنند. این لایه مسئول کار با ذخیره سازی داده ها و چنین مکانیسم هایی است.
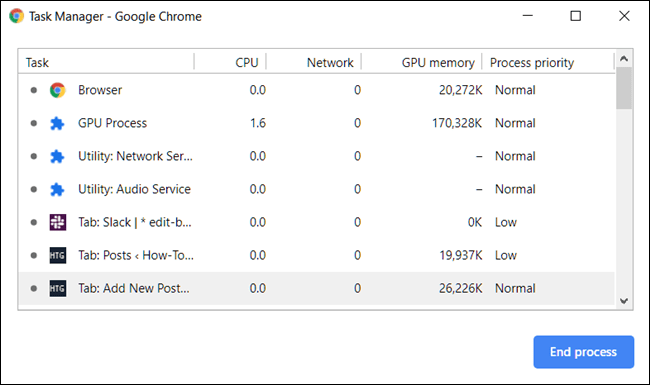
لازم به ذکر است که مرورگرهایی مانند Chrome از یک روش multi-process استفاده می کنند تا سرعت برنامه و همچنین امنیت آن را افزایش بدهند. این مسئله یعنی کروم ممکن است از هر یک از کامپوننت های بالا، چندین نمونه را بسازد. مثلا برای هر سربرگ (tab) یک موتور نمایش جداگانه می سازد. اگر task manager خود کروم را باز کنید این موضوع را می بینید:
به عنوان نکته آخر باید عرض کنم تمام مطالبی که تا این بخش مطالعه کردید یک نگاه بسیار کلی گرایانه بود و در عمل جزئیات و تفاوت های زیادی وجود دارد. مثلا تمام شبکه ها لزوما از مدل OSI یا TCP/IP پیروی نمی کنند یا حتی شبکه هایی که از آن ها پیروی می کنند به طور صد در صد این کار را انجام نمی دهند. همچنین بین مرورگرها تفاوت های مهم وجود دارد؛ مثلا موتور نمایش در آن ها متفاوت است. فایرفاکس از Gecko و Safari از WebKit و مرورگرهای کروم و Edge و Opera را نیز از موتور Blink استفاده می کنند که یک فورک (fork) از WebKit است.
حالا که با مسائل اولیه آشنا شدیم نوبت به بررسی اصل مطلب است.
۱. مرحله اول - Navigation
شما مرورگر خود را باز کرده و آدرس google.com را در آن تایپ کرده و اینتر می زنید. اولین قدم در مرورگرها Navigation یا ناوبری است، یعنی مرورگر باید منابع آن صفحه (تصاویر و ویدیوها و کدها و ...) را پیدا کند. این مسئله برای ما انسان ها ساده است چرا که می گوییم منابع گوگل در google.com است اما در دنیای مرورگرها و سرور ها google.com معنی ندارد بلکه هر منبعی در یک IP خاص قرار گرفته است.
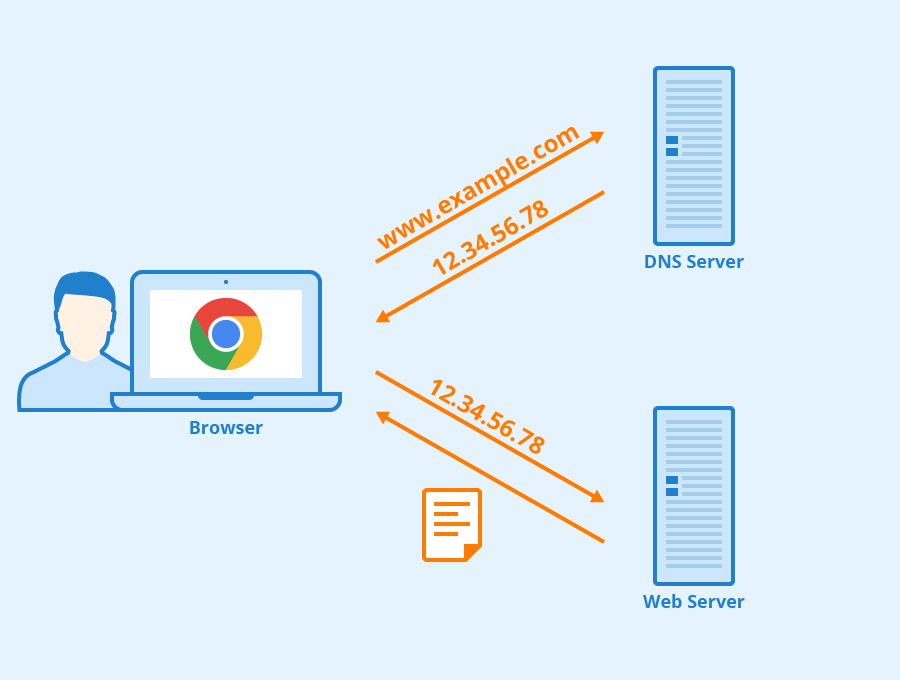
اگر اولین بار است که به یک سایت می روید مرورگر شما از یک سرور DNS درخواست می کند که آدرس آی پی آن سایت را به شما بدهد، سپس با استفاده از این آدرس آی پی به سایت مورد نظر متصل می شود. به این درخواست ارسال شده به سرور های DNS یک DNS lookup یا جست و جوی DNS می گویند. البته اگر بار چندمی است که به یک وب سایت می روید معمولا نیازی به انجام DNS lookup نمی باشد چرا که مرورگر آی پی را در خودش را در سیستم عامل ذخیره می کند.
round-trip time چیست؟
در این مرحله با مفهومی به نام round-trip time یا «زمان تاخیر چرخشی» آشنا می شویم. زمان تاخیر چرخشی در واحد میلی ثانیه اندازه گیری می شود و به زمان بین ارسال درخواست از مرورگر تا دریافت پاسخ از سرور اشاره دارد. فرض کنید بخواهیم یک آدرس سایت (مثلا www.google.com) را حل کنیم. در این حالت:
- مرورگر و کش سیستم عامل بررسی می شود تا در صورتی که IP را داشتیم آن را مستقیما برگردانیم.
- در غیر این صورت مرورگر یک درخواست را به حل کننده DNS (به انگلیسی: DNS resolver) ارسال می کند. این حل کننده DNS کش خود را بررسی می کند و اگر IP را پیدا کرد آن را برمی گرداند.
- در غیر این صورت حل کننده DNS درخواستی را به یک root nameserver ارسال می کند.
- حالا root nameserver آی پی یک TLD nameserver را به حل کننده DNS می دهد. TLD nameserver سرور هایی هستند وب سایت هایی با دامنه سطح بالای یکسان را در خود دارد (مثلا com. یا org. یا biz. و الی آخر).
- حل کننده DNS یک درخواست دیگر را به این TLD nameserver ارسال می کند.
- این بار TLD nameserver آی پی یک authoritative nameserver را برمی گرداند.
- حل کننده DNS برای آخرین بار درخواست خود را به authoritative nameserver ارسال می کند و آی پی سایت اصلی (google.com) را می خواهد.
- authoritative nameserver آی پی سایت را برمی گرداند (در صورتی که چنین سایتی وجود داشته باشد).
- در نهایت حل کننده DNS آدرس آی پی سایت را به مرورگر می دهد.
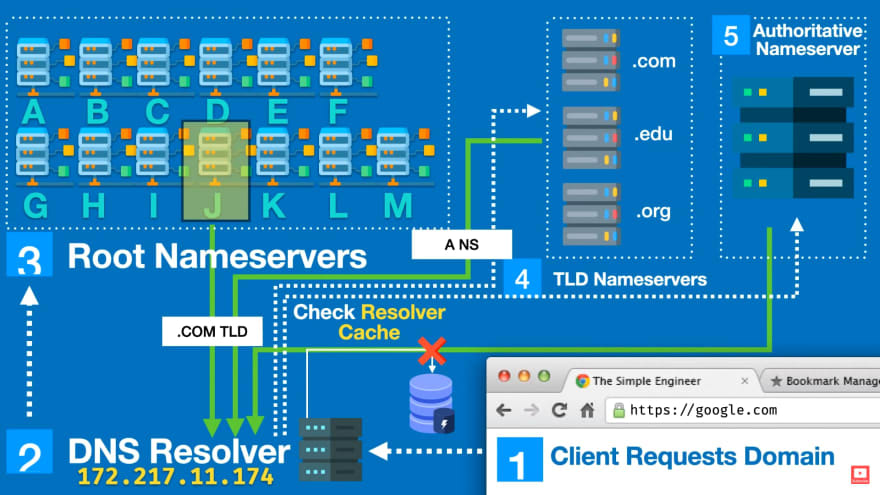
در نظر داشته باشید که این چرخه به ندرت به طور کامل انجام می شود. در اکثر مواقع آی پی از کش مرورگر یا حل کننده DNS پیدا می شود و نیازی به ارسال درخواست های بیشتر به سرور های دیگر DNS نیست بنابراین تصویر بالا بدترین حالت را نشان می دهد. در ضمن این فرآیند بسیار سریع است و در کسری از ثانیه اتفاق می افتد. این اولیه مرحله از round-trip time است.
TCP Handshake چیست؟
پس از آنکه آی پی سرور را به دست آورده ایم باید دست دهی TCP اتفاق بیفتد. در این حالت بین مرورگر و سرور یک دست دهی سه مرحله ای (TCP three-way handshake) اتفاق می افتد. دست دهی سه مرحله ای برای برقراری اتصال در پروتکل TCP استفاده می شود و فرآیند خاصی را دارد. در این نوع ارتباط هر دو دستگاه باید همگام شده (synchronize) و همچنین وجود یکدیگر را اذعان یا تایید (acknowledge) کنند. من می خواهم این فرآیند را در این بخش توضیح بدهم. این مبحث ممکن است کمی پیچیده شود اما نگران نباشید چرا که کم کم این بحث برایتان جا می افتد.
مرحله اول: در این مرحله دستگاه اول (مثلا مرورگر) یک بسته TCP را ارسال می کند که مقدار SYN در آن برابر یک و مقدار ACK برابر صفر است. SYN مخفف synchronize (همگام سازی) و ACK مخفف acknowledge (تایید کردن) است. همچنین درون این بسته عددی خاصی به نام sequence number وجود دارد که ما مقدارش را x در نظر می گیریم. از آنجایی که sequence number اعداد ۳۲ بیتی را قبول می کند احتمال دارد بسته های ارسالی دارای sequence number یکسانی باشند به همین خاطر x به جای اینکه از صفر شروع شود همیشه یک عدد تصادفی خواهد بود.
مرحله دوم: دستگاه دوم (مثلا سرور) این بسته TCP را دریافت می کند و اگر تمایلی به برقراری اتصال (دست دادن) نداشته باشد یک بسته خالی ارسال می کند که RST در آن روی ۱ قرار گرفته باشد اما اگر تمایل به اتصال داشته باشد بسته ای خالی از داده ارسال می کند که در آن SYN روی ۱ و ACK روی ۱ تنظیم شده باشد. همچنین Sequence Number ای تصادفی را می سازد که ما مقدارش را y در نظر می گیریم. علاوه بر آن عددی به نام Acknowledgement Number را نیز می سازد که مقدار آن برابر x+1 است. یعنی عدد تصادفی دستگاه اول (Sequence Number دستگاه اول) را گرفته و یک واحد به آن اضافه می کند. با انجام این کار عدد Acknowledgement Number (عدد تایید) به وجود می آید و با استفاده از آن به دستگاه اول می گوییم که وجود او را تایید می کنیم. حالا دستگاه اول
مرحله سوم: دستگاه اول با ارسال یک بسته ارتباط را تصدیق می کند. این بسته مقدار SYN را صفر و مقدار ACK را یک می کند. همچنین مقدار sequence number را روی x+1 و مقدار ACK را برابر y+1 قرار می دهد.
در طی این دست دهی پارامتر های TCP بین طرفینِ اتصال تعیین می شوند اما اگر اتصال از نوع HTTPS باشد یک دست دهی دیگر نیز نیاز است چرا که اتصالات HTTPS رمزنگاری می شوند بنابراین باید کلید رمزنگاری و همچنین تایید طرفین و رمزگشایی نیز انجام شود.
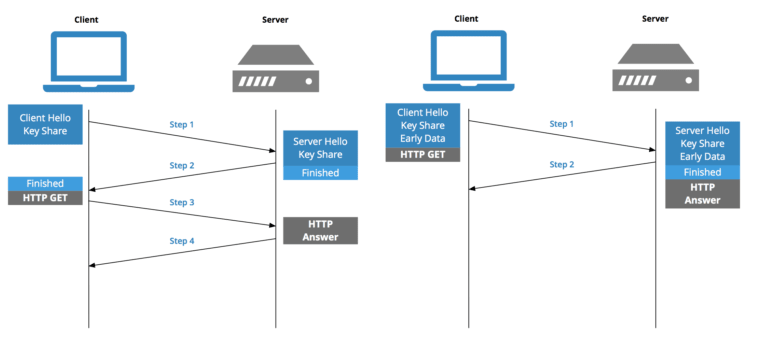
در تصویر بالا به راحتی می بینید که رمزنگاری باعث طولانی تر شدن زمان پاسخ توسط سرور می شود اما امنیتی که توسط آن ارائه می شود ارزش دارد. در قدیم TLS باعث می شد round-trip time یا همان RTT چهار واحد افزایش پیدا کند (یعنی چهار بار بین مرورگر و سرور می چرخیم) اما حالا ۲ یا بعضا ۱ واحد (بسته به شرایط) افزایش پیدا می کند و بسیار سریع تر شده است.
با فرض اینکه DNS لحظه ای باشد و از طرفی یک واحد برای درخواست اولیه Fetch (درخواست سایت از سرور) به RTT اضافه کنیم، به این نتیجه می رسیم که برای نمایش سایت در مرورگر حداقل به چهار RTT نیاز است. با این حساب:
- زمان RTT برای اتصال HTTPS جدید به یک سرور: 4 RTT + DNS
- زمان RTT برای ادامه اتصال به یک سرور: 3 RTT + DNS
۲. مرحله دوم - Fetching یا دریافت
لغت fetch به معنی «دریافت» است. حالا که یک اتصال TCP داریم، مرورگر می تواند شروع به دانلود منابع صفحه کند. برای انجام این کار یک درخواست HTTP به سمت سرور ارسال می شود، البته خود درخواست با TLS رمزنگاری می شود چرا که نوع اتصال ما HTTPS است.
طبیعتا نوع درخواست ارسال شده HTTP GET است. درخواست های GET برای دریافت داده از سمت سرور استفاده می شوند و state آن را تغییر نمی دهند. شکل درخواست من به گوگل به شکل زیر است:
GET / HTTP/2 Host: www.google.com User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8 Accept-Language: en-GB,en;q=0.5 Accept-Encoding: gzip, deflate, br Connection: keep-alive Upgrade-Insecure-Requests: 1 Cache-Control: max-age=0 TE: Trailers
ما فرض می کنیم درخواست ارسال شده حتما معتبر است. زمانی که وب سرور چنین درخواستی را دریافت می کند یک HTPP response یا پاسخ را برای ما برمی گرداند که حاوی header های مناسب و همچنین کدهای HTML است:
HTTP/2 200 OK date: Sun, 18 Jul 2021 00:26:11 GMT expires: -1 cache-control: private, max-age=0 content-type: text/html; charset=UTF-8 strict-transport-security: max-age=31536000 content-encoding: br server: gws content-length: 37418 x-xss-protection: 0 x-frame-options: SAMEORIGIN domain=www.google.com priority=high X-Firefox-Spdy: h2
شما می توانید به راحتی header درخواست ها را مشاهده کنید. کدهای HTML نیز درون بخش body درخواست قرار دارند بنابراین در گزارش بالا مشاهده نمی شوند.
۳. مرحله سوم - Parsing یا تجزیه
زمانی که مرورگر پاسخ خود را از وب سرور دریافت کرد باید این پاسخ را تجزیه یا parse کند. به تبدیل داده های پاسخ HTTP به داده های مناسب برای نمایش یک صفحه یا به طور کل برای اجرای کدها parse کردن یا تجزیه کردن می گویند.
Document Object Model یا به اختصار DOM که در فارسی به نام «مدل شیء گرای سند» شناخته می شود تمثیلی از شیء بزرگی است که ساختار و محتوای صفحه HTML را دارد. این ساختار به شکل درختی است و کل سند HTML را به صورت node های مختلف نمایش می دهد که انواع مختلفی دارند (مثلا Node.DOCUMENT_NODE وNode.TEXT_NODE و Node.ELEMENT_NODE و ...). برنامه نویس ها می توانند به این node ها متصل شده و تغییرات دلخواهشان را اعمال کنند.
از طرف دیگر CSSOM یا CSS Object Model را داریم که مجموعه ای از API های مختلف است. جاوا اسکریپت با استفاده از این API ها به می تواند دستورات CSS صفحه را تغییر داده و در نتیجه باعث تغییر شکل ظاهری صفحه بشود. حتما شما هم متوجه شده اید که CSSOM دقیقا مانند DOM است با این تفاوت که به طور خاص CSS را هدف می گیرد.
نحوه ساخت درخت های DOM و CSSOM
من ابتدا با DOM شروع می کنم. ساخت DOM دو مرحله اصلی دارد: tokenization (توکن سازی) و tree construction (درخت سازی).
در دنیای تجزیه (parsing) می توان گفت که HTML متفاوت از دیگر کدها است چرا که نمی تواند به روش های عادی تجزیه شود. چرا؟ به دلیل اینکه نمی تواند به صورت «دستور زبان مستقل از متن» یا CFG تعریف شود. در عوض فرمت خاصی برای تعریف HTML وجود دارد که به Document Type Definition معروف است. به همین خاطر است که مرورگرها parser (تجزیه کننده) های خودشان را ساخته اند. شما می توانید توضیحات مفصل در این رابطه را در این صفحه مطالعه کنید اما خلاصه آن همان چیزی است که بالاتر هم گفتم:
- tokenization (توکن سازی): در این مرحله دستورات نحوی پردازش شده و توکن تولید می شود.
- tree construction (درخت سازی): در این مرحله بر اساس توکن های ساخته شده یک درخت تولید می شود که همان درخت DOM است.
درخت DOM محتوای سند HTML را به صورت یک رابطه سلسله مراتبی توصیف می کند. تگ <html> اولین تگ و root node (گره ریشه ای) صفحه است. شما می توانید در این درخت تمام روابط بین عناصر را مشاهده کنید. مثلا به تگ هایی که درون تگ های درون قرار گرفته اند child nodes یا گره فرزند می گوییم. شما می توانید یک درخت ساده DOM را در تصویر زیر مشاهده کنید:
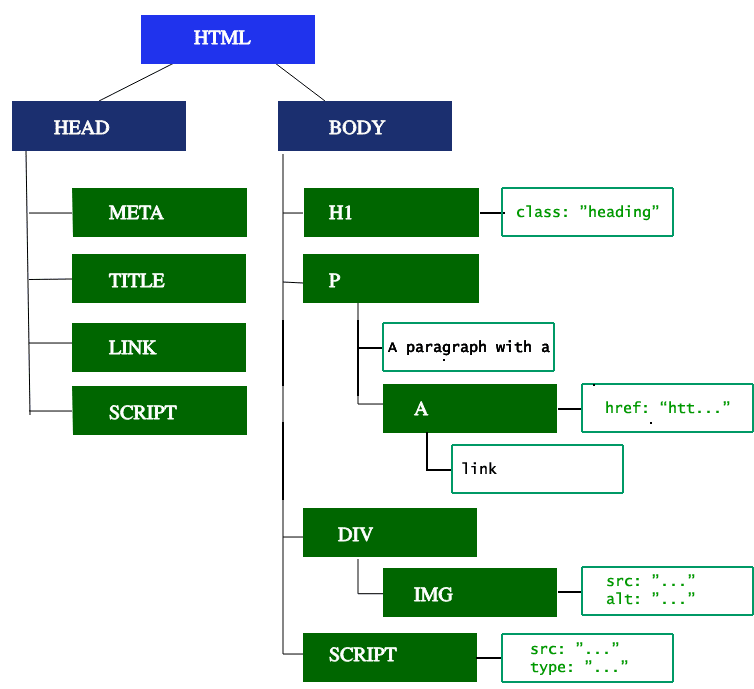
زمانی که مرورگر در حال ساخت درخت DOM است به منابع مختلفی برخورد می کند. برخی از این منابع مانند تصاویر (تگ های img) از نوع non-blocking یا غیر مسدودگر هستند که یعنی بارگذاری آن ها باعث متوقف شدن پردازش صفحه و ساخت DOM نمی شود اما برخی از منابع دیگر مانند فایل های جاوا اسکریپت blocking یا مسدودگر هستند و تجزیه و ساخت درخت DOM را متوقف می کنند. تا زمانی که دانلود این منابع کامل نشود، درخت DOM نیمه کاره باقی می ماند. چرا؟ به دلیل اینکه این فایل ها می توانند ظاهر صفحه را به طور جدی تغییر بدهند بنابراین عاقلانه نیست که ابتدا یک صفحه متنی و خالی HTML را نمایش بدهیم و سپس کدهای جاوا اسکریپت را روی آن اعمال کنیم.
مرحله دوم پردازش فایل های CSS و ساخت درخت CSSOM است. دقیقا مانند فرآیندی که در DOM اتفاق افتاد، مرورگر تک تک قوانین CSS را بررسی می کند و بر اساس سلکتور های CSS، درختی از عناصر مختلف و روابط بین آن ها (روابط فرزندی، خواهر و برادری و ...) می سازد. از نظر تجزیه نیز باید گفت که CSS برخلاف HTML از روش CFG (دستور زبان مستقل از متن) استفاده می کند. مرورگر پس از حل این قوانین CSS به پردازش بقیه کدها ادامه می دهد.
ساخت Render Tree
پس از اینکه درخت های DOM و CCSOM ساخته شدند باید هر دو را درون یک درخت به نام render tree (درخت نمایش) ترکیب کنیم. این درخت به عنوان ورودی پروسه نمایش استفاده خواهد شد و پیکسل هایی که در صفحه مشاهده می کنید نتیجه استفاده از آن است.
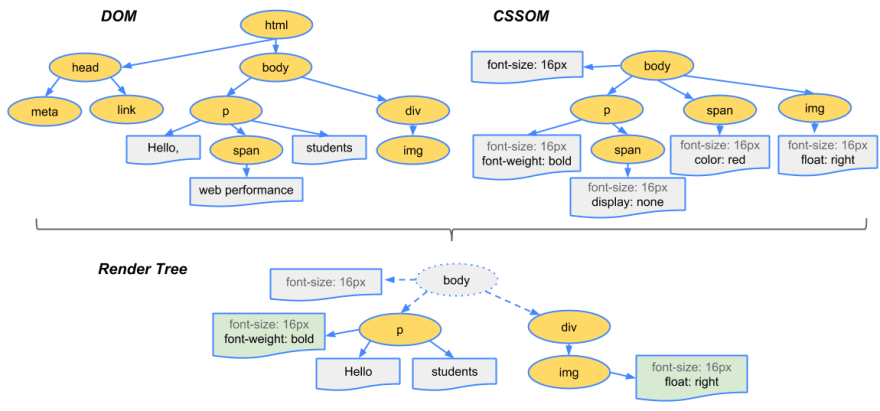
برای ساخت درخت نمایش باید چندین کار مختلف انجام شود. ابتدا باید از ریشه درخت DOM شروع کنیم و روی هر کدام از node های قابل مشاهده حرکت کنیم. برخی از node ها مانند تگ های script یا تگ های meta قابل مشاهده نیستند بنابراین هیچ نقشی در ظاهر صفحه وب ندارند. به همین دلیل است که در فرآیند ساخت درخت نمایش، این دسته از node ها را به طور کل نادیده می گیریم. این مسئله برای node هایی که توسط دستورات CSS مخفی شده اند نیز صادق است. مثلا در تصویر بالا می بینید که یک تگ span را با استایل display: none داشته ایم و به همین دلیل آن را در درخت نمایش مشاهده نمی کنیم.
به هر node قابل مشاهده ای که رسیدیم، دستورات مربوط به CSSOM را برای آن node پیدا کرده و آن ها را روی node مورد نظر اعمال می کنیم. در نهایت این node های آماده شده را در صفحه مرورگر نمایش می دهیم. برای این کار باید به مرحله layout برویم اما قبل از آن دوست دارم در رابطه با Preload Scanner صحبت کنیم.
Preload Scanner چیست؟
زمانی که thread اصلی مرورگر در حال ساخت درخت DOM و انجام عملیات های بالا است، یک worker دیگر شروع به اسکن فایل های مختلف می کند. ما به این worker خاص preload scanner می گوییم. کار preload scanner این است که منابع خاصی مانند فایل های CSS یا جاوا اسکریپت یا فونت های صفحه را پیدا کرده و درخواست های fetch را برایشان آماده کند. این یک بهینه سازی است که مرورگرهای امروزی در مرحله parsing انجام می دهند چرا که اگر بخواهیم منتظر مرورگر بمانیم تا منابع را تک تک پیدا کرده و سپس درخواست های fetch را برایشان تولید کند، زمان لازم برای نمایش صفحات وب بسیار بیشتر می بود.
<link rel="stylesheet" src="styles.css"/> <script src="myscript.js" async></script> <img src="myimage.jpg" alt="image description"/> <script src="anotherscript.js" async></script>
به این مثال نگاه کنید. ما با استفاده از دستوراتی مانند async یا defer به preload scanner می گوییم که این منابع را با چه اولویتی دانلود کند. async بدین معنا است که منبع خاص به صورت ناهمگام و به محض شناسایی دانلود شود در حالی که defer می گوید دانلود آن منبع خاص به بعد از اتمام تجزیه صفحه موکول شود.
کامپایل شدن جاوا اسکریپت
در حالی که مرورگر در حال ساخت CSSOM می باشد، preload scanner در حال دانلود دیگر منابع صفحه مانند فایل های جاوا اسکریپتی است. در این مرحله جاوا اسکریپت تفسیر شده و کامپایل می شود تا بتواند در صفحه اجرا شود.
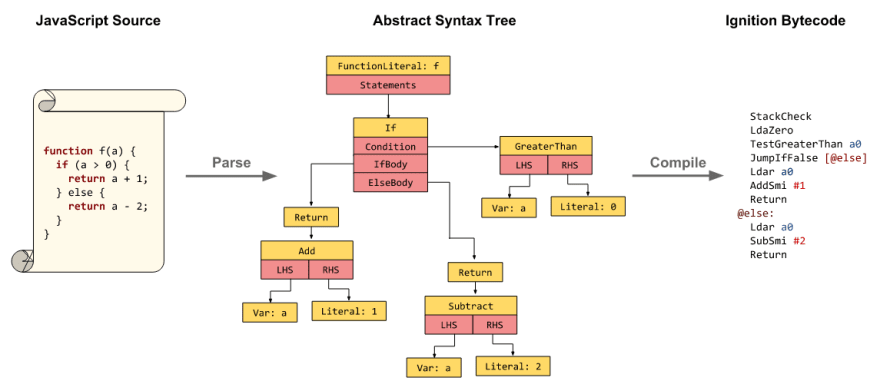
همانطور که در تصویر بالا مشاهده می کنید ابتدا کدهای جاوا اسکریپت به abstract syntax tree (درخت نحو انتزاعی) تبدیل می شوند. در مرحله بعدی مرورگرها درخت نحو انتزاعی را گرفته و آن را به مفسر جاوا اسکریپت پاس می دهند. مفسر کدهای دریافت شده را به bytecode کامپایل می کند تا بتوانند در مرورگر اجرا شوند. به این فرآیند، کامپایل شدن جاوا اسکریپت گفته می شود.
Accessibility Tree چیست؟
درخت دسترسی پذیری یا Accessibility Tree یک درخت خاص از صفحه HTML شما است که برای کاربران دارای معلولیت در نظر گرفته می شود. افرادی که دارای معلولیت هستند (مثلا کم بینا یا نابینا هستند) از دستگاه های صفحه خوان استفاده می کنند. کار این دستگاه ها این است که صفحه وب را برای این کاربران به صورت صوتی بخوانند. هر زمانی که DOM به روز رسانی شود، درخت دسترسی پذیری نیز توسط مرورگر به روز رسانی خواهد شد.
۴. مرحله چهارم - Rendering یا نمایش
پس از اینکه تمام کدها تجزیه و تحلیل شد نوبت به نمایش یا render کردن آن ها است. همانطور که قبلا به صورت خلاصه اشاره کردم، مرورگر از render tree برای نمایش محتوا استفاده می کند. این عملیات چندین مرحله دارد:
- layout
- paint
- compositing (در بعضی موارد خاص)
در اینجا باید در رابطه با Critical Rendering Path (به اختصار CRP) یا «مسیر ضروری رندرینگ» صحبت کنیم. مسیر ضروری رندرینگ در صفحات وب به زنجیره ای از عملیات اطلاق می شود که باید قبل از نمایش صفحه انجام شوند. تصویر زیر این موضوع را به خوبی نمایش می دهد:
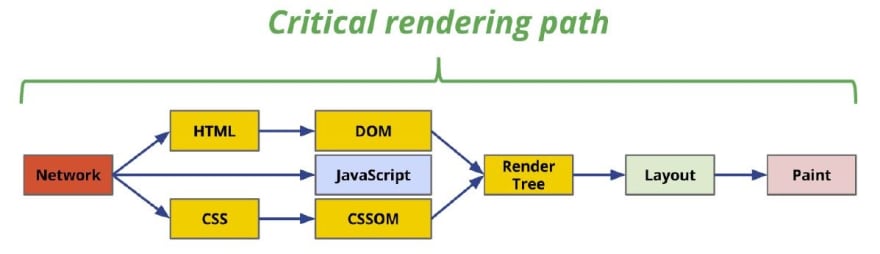
این تصویر مسیری را نمایش می دهد که مرورگر باید طی کند تا محتوای سایت برای ما نمایش داده شود. من در مقاله مسیر ضروری رندرینگ توضیحاتی مفصلی در این رابطه داده ام که در صورت تمایل می توانید آن را مطالعه کنید. به زبان ساده CRP به شما این قدرت را می دهد که با بارگذاری هوشمندانه منابع سایت خود، سرعت نمایش آن را بالاتر ببرید. همانطور که در تصویر بالا مشخص است اولین مرحله نمایش یا رندرینگ Layout است.
فاز Layout
Layout اولین مرحله در نمایش محتوا است. در این مرحله مکان فیزیکی عناصر در صفحه مشخص می شود. کل این پروسه یک پروسه بازگشتی یا recursive است. چرا؟ به دلیل اینکه طی آن ابتدا از اولین عنصر صفحه (تگ <html>) شروع می کنیم و سپس بین عناصر مختلف صفحه حرکت می کنیم و مکان فیزیکی عناصر در آن شاخه را مشخص می کنیم. حالا دوباره بین شاخه های دیگر گردش می کنیم تا زمانی که تمام عناصر را بررسی کرده باشیم.
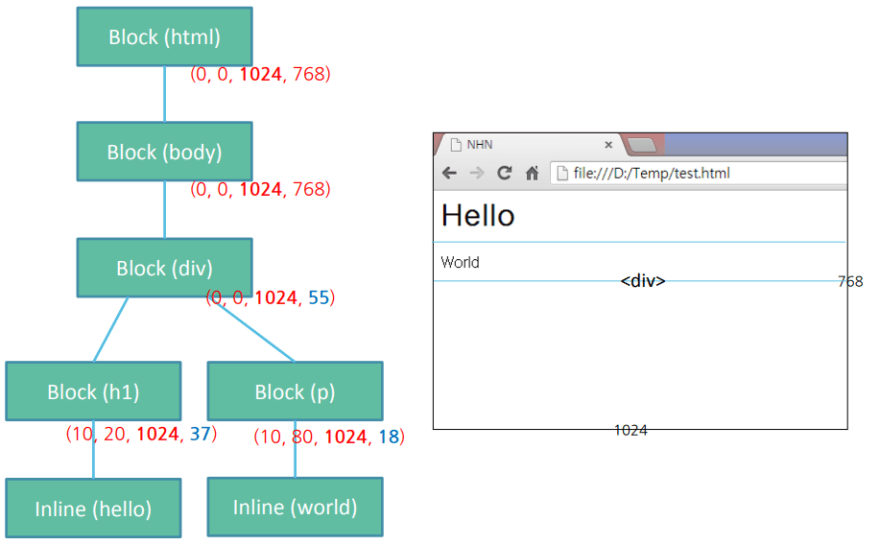
در پایان کار درختی مانند درخت بالا تولید می شود. همانطور که می بینید مختصات هر عنصر برایش مشخص شده است.
طبیعتا زمانی که چیزی در صفحه تغییر می کند (مثلا با کدهای جاوا اسکریپت مکان دکمه ای را تغییر می دهیم) باید دوباره layout اجرا شود اما آیا layout کردن تمام صفحه کار درستی است؟ قطعا خیر! layout کردن همه چیز از صفر باعث کند شدن صفحه می شود بنابراین باید فقط همان قسمت خاص را دوباره layout کنیم. مرورگرها سیستم خاصی به نام dirty bit را برای این کار طراحی کرده اند. در این سیستم رندر کننده می تواند از یکی از دو فلگ زیر استفاده کند:
- dirty: یعنی node ای خاص نیاز به layout شدن دارد.
- children are dirty: یعنی node ای خاص حداقل یک فرزند دارد که نیاز به layout شدن دارد.
همانطور که گفتم تعیین اندازه node ها در بار اول layout شدن نام دارد اما در دفعات بعدی به آن reflow گفته می شود.
فاز Paint
این بخش آخرین بخش رندرینگ است. در این مرحله تمام اطلاعات تولید شده در فاز layout در عمل به پیکسل تبدیل می شوند تا در مرورگر کاربر نمایش داده شوند. در واقع فرآیند paint تمام جوانب ظاهری عناصر صفحه (رنگ متون، سایه ها، دکمه ها و ...) را طراحی می کند و آن را در مرورگر نمایش می دهد.
طبیعتا این فرآیند اولویت خاص خودش را دارد. در نسخه دوم زبان CSS این اولویت بندی به شکل زیر تعریف شد:
- رنگ پس زمینه (background color)
- تصویر پس زمینه (background image)
- حاشیه ها (border)
- فرزندان (children)
- خصوصیت outline
عملیات painting می تواند ساختار عناصر در layout را به لایه های متفاوتی تقسیم کند. مثلا برخی از عناصر مانند <video> یک لایه کاملا جداگانه و اختصاصی را برای خودشان تعریف می کنند. همچنین عناصری که دارای بعضی خصوصیت های CSS مانند opacity و 3D transform باشند نیز لایه های خودشان را می سازند. تعریف لایه های جدید به سرعت برنامه ما کمک می کنند اما از نظر مصرف مموری سنگین هستند بنابراین نباید بیش از حد از آن ها استفاده کنید.
Compositing چیست؟
زمانی که بخش های مختلف یک سند در لایه های مختلف قرار گرفته است و بعضی از این لایه ها روی یکدیگر قرار می گیرند به فرآیندی به نام compositing نیاز خواهیم داشت. فرآیند compositing باعث می شود ترتیب لایه ها حفظ شود تا همه چیز به درستی به کاربر نمایش داده شود. با اینکه فرآیند compositing در پس زمینه پیچیدگی های خاص خودش را دارد اما برای ما به همین سادگی است.
در ضمن زمانی که منابع مختلف یک صفحه بارگذاری می شود ممکن است reflow رخ بدهد. این reflow ها باعث انجام repaint (انجام دوباره paint) و سپس re-composite (انجام دوباره composite) می شوند. مثلا اگر یک تگ img را در صفحه خود قرار بدهید اما سایز آن را به صورت دقیق تعیین نکنید، پروسه رندرینگ به مرحله layout برمی گردد تا اندازه تصویر را تعیین کند بنابراین با جلوگیری از انجام reflow ها سرعت نمایش صفحات خود را افزایش می دهید.
۵. مرحله پنجم - Finalising یا نهایی سازی
شاید تصور کنید بعد از تمام این مراحل کارمان تمام شده است اما لزوما اینطور نیست. اگر بارگذاری اسکریپت های جاوا اسکریپت defer شده باشد (به بعد از بارگذاری کل صفحه موکول شده باشد) thread در حال کار روی آن اسکریپت است بنابراین هنوز نمی توانید آن را اسکرول کرده یا با مرورگر تعامل خاصی داشته باشید.
گوگل از یک معیار اندازه گیری به نام Time to Interactive استفاده می کند که به زمان بین ارسال درخواست و جست و جوی DNS تا تعامل پذیر شدن صفحه برای کاربر اشاره می کند. این زمان از نظر گوگل زیر ۵۰ میلی ثانیه پیشنهاد می شود. بنابراین می توان نتیجه گرفت که باید thread اصلی مرورگرها همیشه خالی برگذارید و برای بارگذاری اسکریپت های خارجی و غیر ضروری از web worker ها استفاده نمایید.
پس از اتمام این مرحله، مرورگر می تواند با کاربران خود تعامل داشته باشید. این نحوه کار مرورگرهای امروزی بود.
منبع: وب سایت dev.to









در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.
در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.