ساخت یک GraphQL API مدرن با React - PostgreSQL - Node (بخش ۱)
Build a Modern GraphQL API with React, PostgreSQL, Node - Part 1

مقدمه و موارد پیش نیاز
به پروژه بزرگ و عملی ما خوش آمدید. در این پروژه می خواهیم یک وب سایت را به صورت full stack طراحی کنیم، یعنی هم front-end و هم back-end را با تکنولوژی های روز دنیا طراحی کنیم تا شما با پروژه های بزرگ و واقعی آشنا شوید. البته توجه داشته باشید که هدف من از این مقاله یادگیری راه اندازی اولیه و ترکیب تکنولوژی های مختلف با یکدیگر است. ما به هیچ عنوان قصد ساخت یک وب سایت کامل را نداریم.
این پروژه برای افرادی طراحی شده است که زمان مناسبی را در دنیای توسعه وب گذرانده اند و می توانند به صورت حرفه ای به طراحی front-end و back-end بپردازند. به عبارتی این پروژه پیشرفته بوده و برای افراد مبتدی در نظر گرفته نشده است (به طور مثال فرآیند نصب تکنولوژی های مختلف مانند PostgreSQL را توضیح نمی دهیم)، در عین حال کاربران تازه کار نیز می توانند از آن استفاده کنند اما نیاز به تحقیق و جست و جو خواهند داشت.
تکنولوژی های مورد نیاز
این پروژه یک پروژه Full Stack است بنابراین از تکنولوژی های زیادی استفاده می کند:
- React: کتابخانه ای بسیار محبوب برای طراحی Front-end سایت
- TypeScript: یک super set برای زبان جاوا اسکریپت (جاوا اسکریپت با قابلیت های بیشتر)
- GraphQL: یک زبان کوئری برای API ها
- URQL: یک کلاینت برای کار با GraphQL API ساخته شده توسط ما
- Node.js: یک runtime برای جاوا اسکریپت که روی سرور اجرا می شود
- PostgreSQL: یک پایگاه داده رابطه ای مانند MySQL با قابلیت های بیشتر
- Redis: یک پایگاه داده که مقادیر را در مموری سیستم (RAM) ذخیره می کند
- Next.js: یک فریم ورک برای کتابخانه React که اجازه می دهد server-side rendering انجام بدهیم.
- TypeGraphQL: یک فریم ورک برای تعریف ساختار GraphQL با تایپ اسکریپت
- MikroORM و TypeORM: هر دو پکیج، یک ORM هستند که کار ارتباط با پایگاه داده را برایمان ساده تر می کنند. برای اینکه با هر دو پکیج آشنا بشوید ابتدا از MikroORM استفاده می کنیم و در اواسط پروژه کدها را به TypeORM تغییر می دهیم.
همانطور که توضیح دادم این پروژه حرفه ای است بنابراین برای دنبال کردن آن برای افراد مبتدی پیشنهاد نمی شود.
پیکربندی اولیه پروژه
برای کار با چنین پروژه بزرگی باید در ابتدا پیکربندی اولیه آن را انجام بدهیم. این کار به چند بخش تقسیم می شود.
راه اندازی git و npm و tsc
من ابتدا پوشه ای به نام codebase را در محلی که می خواهم ایجاد می کنم. حالا ترمینال را درون این پوشه باز کنید و دستورات زیر را اجرا نمایید:
git init npm init -y tsc --init
دستور اول باعث می شود پروژه تحت نظر git باشد و دستور دوم پروژه را در قالب npm تعریف می کند تا بتوانیم پکیج های مختلف را در آن نصب کنیم. نهایتا دستور سوم نیز اعلام می کند که پروژه ما با تایپ اسکرپیت کار می کند بنابراین یک فایل tsconfig.json برایمان ایجاد می شود. تنظیمات اولیه این فایل برای ما مناسب نیست به همین دلیل محتوای آن را با محتوای زیر تغییر بدهید:
{
"compilerOptions": {
"target": "ES6",
"module": "commonjs",
"lib": ["DOM", "ES6", "ES2017", "ESNext.AsyncIterable"],
"sourceMap": true,
"outDir": "./dist",
"strict": true,
"noImplicitAny": true,
"strictNullChecks": true,
"strictFunctionTypes": true,
"noImplicitThis": true,
"noUnusedLocals": true,
"noUnusedParameters": true,
"noFallthroughCasesInSwitch": true,
"baseUrl": ".",
"allowSyntheticDefaultImports": true,
"esModuleInterop": true,
"resolveJsonModule": true,
"experimentalDecorators": true,
"emitDecoratorMetadata": true,
"skipLibCheck": true,
"forceConsistentCasingInFileNames": true
},
"exclude": ["node_modules"],
// "include": ["./src/**/*.tsx", "./src/**/*.tsx"]
}
البته در نظر داشته باشید که این تنظیمات پیشنهادی من است. شما می توانید این تنظیمات را بر اساس سلیقه خود کاملا تغییر بدهید. البته فعال کردن decorator ها الزامی است چرا که MikroORM از آن استفاده می کند. همچنین در نظر داشته باشید که من این تنظیمات را بسیار سخت گیرانه نوشته ام (مثلا اگر متغیر بی استفاده ای در کد ما باشد خطا می گیریم و کدها کامپایل نمی شود) بنابراین اگر می خواهید کمی آزاد تر باشید این گزینه های سخت گیرانه را غیرفعال کنید. در نهایت بخش include را کامنت کرده ام چرا که بعدا به آن برمی گردیم.
در مرحله بعدی یک فایل به نام gitignore. را در همان پوشه codebase ایجاد کنید و عبارت node_modules را در آن قرار بدهید. این کار باعث می شود git پوشه node_modules را نادیده بگیرد.
سپس دستور زیر را اجرا کنید تا تایپ های Node.js و خود typescript برایمان نصب شود. همانطور که می دانید در پروژه های تایپ اسکریپت اگر بخواهیم از node استفاده کنیم باید تایپ هایش را نصب کنیم تا به تمام قابلیت های تایپ اسکریپت دسترسی داشته باشیم:
npm i -D @types/node typescript
در مرحله بعدی به فایل package.json رفته و دو اسکریپت جدید به نام های watch و dev را تعریف کنید:
{
"name": "codebase",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"watch": "tsc -w",
"dev": "nodemon dist/index.js"
},
"keywords": [],
"author": "",
"license": "ISC",
"devDependencies": {
"@types/node": "^15.12.2",
"nodemon": "^2.0.7",
"supervisor": "^0.12.0",
"typescript": "^4.3.2"
}
}
اسکریپت tsc -w تایپ اسکریپت را در حالت watch اجرا می کند تا هر زمانی که فایلی را تغییر دادیم، فایل ها به صورت خودکار به جاوا اسکریپت کامپایل شوند. فایل های کامپایل شده ما در پوشه dist قرار خواهند داشت (این مسئله را در فایل tsconfig.json مشخص کردیم). اسکریپت dev نیز از برنامه ای به نام nodemon استفاده می کند تا در صورت ایجاد تغییر در کدهای جاوا اسکریپت (پوشه dist) آن ها را دوباره اجرا کند. اگر nodemon را در سیستم خود ندارید آن را بدین شکل نصب کنید:
npm i -D nodemon
حالا در پوشه codebase یک پوشه جدید به نام src ساخته و فایلی به نام index.ts را در آن ایجاد کنید. درون آن یک log ساده بنویسید:
console.log("FIRST TEST");
حالا در پنجره ترمینال دستور npm run watch را اجرا کنید. با این کار می بینید که پوشه dist برایتان ساخته شده است. حالا در ترمینال دیگری، دستور npm run dev را اجرا کنید. با این کار فایل های جاوا اسکریپت ما نیز تحت نظر گرفته می شوند و با هر تغییر سرور ریستارت خواهد شد.
ساخت پایگاه داده جدید
فرض من این است که می دانید چطور PostgreSQL را نصب کنید. از ترمینال وارد محیط PSQL شده و یک پایگاه داده جدید به نام roxo_training بسازید:
CREATE DATABASE roxo_training;
حالا یک پایگاه داده جدید را داریم. مطمئن باشید که نام کاربری رمز عبور خود برای PostgreSQL را می دانید.
نصب Mikro-ORM
همانطور که گفتم MikroORM به ما کمک می کند تا با پایگاه داده تعامل راحتی داشته باشیم. ما از پایگاه داده PostgreSQL استفاده می کنیم بنابراین در ترمینال می گوییم:
npm i -s @mikro-orm/core @mikro-orm/postgresql
اطلاعات بیشتر در رابطه با نصب این پکیچ در documentation رسمی آن موجود است. حالا به فایل index.ts می رویم تا MikroORM را تست کنیم:
import { MikroORM } from "@mikro-orm/core";
const main = async () => {
const orm = await MikroORM.init({
dbName: "roxo_training",
type: "postgresql",
debug: true,
});
};
main();
من تابعی async به نام main را تعریف می کنیم تا بتوانم از await استفاده کنم. با صدا زدن MikroORM.init اتصال ما به پایگاه داده شروع می شود. dbName نام پایگاه داده، type نوع پایگاه داده و debug مسئول نمایش کوئری های SQL اجرا شده در پس زمینه است تا دقیقا ببینیم چه کوئری هایی اجرا شده است. من نمی خواهم debug روی سرور واقعی نیز روشن باشد بلکه فقط در حال توسعه به آن نیاز داریم بنابراین به جای اینکه به صورت دستی و به شکل بالا از آن استفاده کنیم، چنین کاری را انجام می دهیم:
import { MikroORM } from "@mikro-orm/core";
const main = async () => {
const orm = await MikroORM.init({
dbName: "roxo_training",
type: "postgresql",
debug: process.env.NODE_ENV !== "production",
});
};
main();
NODE_ENV یک متغیر در env است که در هنگام قرار گیری روی سرور باید روی production قرار بگیرد. کد بالا می گوید اگر مقدار NODE_ENV روی production نیست آنگاه debug باید فعال باشد. از آنجایی که می خواهیم چنین کاری را در چندین بخش از برنامه انجام بدهیم بهتر است در پوشه src یک فایل جدید به نام constants.ts را ایجاد کنیم و محتوایش را بدین شکل استفاده کنیم:
export const __prod__ = process.env.NODE_ENV === "production";
حالا به index.ts برگشته و از آن استفاده می کنیم:
import { MikroORM } from "@mikro-orm/core";
import { __prod__ } from "./constants";
const main = async () => {
const orm = await MikroORM.init({
dbName: "roxo_training",
type: "postgresql",
debug: !__prod__,
});
};
main();
در صورتی که پایگاه داده شما رمز و حساب کاربری خاصی دارد حتما آن ها را در همین شیء پاس داده شده به ()init تعریف کنید.
در مرحله بعدی باید entity های خود را تعریف کنیم که معادل جدول ها در پایگاه داده هستند (MokroORM نام جداول را entity می گذارد). برای تعریف entity ها در پوشه src یک پوشه دیگر به نام entities تعریف کنید و فایل جدیدی به نام Post.ts را در آن تعریف نمایید:
import { Property, Entity, PrimaryKey } from "@mikro-orm/core";
@Entity()
export class Post {
@PrimaryKey()
id!: number;
@Property()
createdAt: Date = new Date();
@Property({ onUpdate: () => new Date() })
updatedAt: Date = new Date();
@Property()
title!: string;
}
ما در ابتدا کلاسی به نام Post را داریم. هر نامی که برای این کلاس بگذارید، نام جدول (table) شما در پایگاه داده roxo_training خواهد بود. یادتان باشد که حتما از decorator ای به نام entity بالای نام کلاس استفاده کنید (decorator ها از قابلیت های تایپ اسکریپت هستند).
حالا درون این کلاس (یا جدول) باید ستون هایش را تعریف کنیم. در ابتدا یک id را داریم. از آنجایی که فیلد id در همین ابتدا مقداری ندارد و باید در هنگام ثبت داده در پایگاه داده مقدار بگیرد، وجود علامت ! در کنار آن الزامی است در غیر این صورت خطا می گیرید. رعایت این مسئله برای تمام ستون های که مقدار اولیه ندارند الزامی است. ستون های createdAt و updatedAt به ترتیب نشان دهنده زمان ثبت یک ردیف در جدول و زمان به روز رسانی آن هستند. این دو ستون معمولا در اکثر جدول ها وجود دارند و بسیار کاربردی هستند. ستون آخر نیز title یا عنوان است که فعلا آن را برای تست نگه می دارم. در ضمن decorator ای که به نام property می بینید باعث می شود خصوصیات کلاس های ما تبدیل به ستون شوند.
در مرحله بعدی به index.ts برمی گردیم و جدول ساخته شده را به خصوصیتی به نام entities پاس می دهیم:
import { MikroORM } from "@mikro-orm/core";
import { __prod__ } from "./constants";
import { Post } from "./entities/Post";
const main = async () => {
const orm = await MikroORM.init({
entities: [Post],
dbName: "roxo_training",
type: "postgresql",
debug: !__prod__,
});
const post = orm.em.create(Post, { title: "my first post!" });
await orm.em.persistAndFlush(post);
};
main().catch(err => console.error(err));
همانطور که می بینید من خصوصیت entities را تعریف کرده ام که باید به شکل یک آرایه از جدول های تعریف شده توسط ما باشد. در مرحله بعدی از متد create استفاده کرده و یک ردیف را برای جدول Post ساخته ام و فقط ستون title را مقدار دهی کرده ام. چرا؟ به دلیل اینکه ستون های دیگر مانند id و createdAt و updatedAt به صورت خودکار مقدار دهی می شوند بنابراین نیازی به مقدار دهی دستی توسط ما ندارند. در ضمن تمام هدف ما از نوشتن این کدها این است که اتصال به پایگاه داده را تست کنیم.
مسئله بسیار مهم اینجاست که صدا زدن متد create و ساختن یک ردیف برای جدول Post، آن را در پایگاه داده ثبت نمی کند بلکه فقط یک ردیف را ساخته و برایتان برمی گرداند. به همین دلیل است که من آن را در متغیر post ذخیره کرده ام. برای اینکه این داده را در پایگاه داده ذخیره کنیم از متد persistAndFlush استفاده کرده ایم که ابتدا تغییرات ثبت نشده در پایگاه داده را دور می اندازد و سپس داده جدید ما را در پایگاه داده ثبت می کند. persistAndFlush یک متد ناهمگام (async) است بنابراین باید آن را await کنیم. برای اجرای کد بالا یادتان باشد که npm run watch و npm run dev باید در ترمینال در حال اجرا باشند. با این کار به محض ذخیره کردن یک فایل، سرور ریستارت می شود.
من در انتهای تابع main یک بلوک catch را اضافه کرده ام تا خطا های ممکن را دریافت کنیم. حالا اگر به ترمینال نگاه کنید ممکن است چنین خطایی را مشاهده کنید:
[info] MikroORM failed to connect to database roxo_training on postgresql://postgres@127.0.0.1:5432 error: password authentication failed for user "postgres"
mikro-orm به صورت پیش فرض سعی کرده است با نام کاربری postgres به پایگاه داده متصل شود. ممکن است شما چنین خطایی را دریافت نکنید. چرا؟ به دلیل اینکه postgres کاربر اصلی در PostgreSQL است اما اگر مانند من به این مشکل برخورد کردید باید نام کاربری و رمز عبور خود را نیز پاس بدهید:
const main = async () => {
const orm = await MikroORM.init({
entities: [Post],
user: "amir",
password: "00000000",
dbName: "roxo_training",
type: "postgresql",
debug: !__prod__,
});
const post = orm.em.create(Post, { title: "my first post!" });
await orm.em.persistAndFlush(post);
};
من نام کاربری amir و رمز عبور 00000000 را برای پایگاه داده PostgreSQL خودم انتخاب کرده ام، طبیعتا شما باید نام کاربری و رمز عبور خود را وارد کنید. در ضمن یادتان باشد که رمز 00000000 رمز بسیار ضعیفی است و فقط برای آسان تر شدن کار در این مثال استفاده شده است. این بار اگر به ترمینال نگاه کنید خطای دیگری گرفته ایم:
[info] MikroORM successfully connected to database roxo_training on postgresql://amir:*****@127.0.0.1:5432
[query] begin
[query] insert into "post" ("created_at", "title", "updated_at") values ('2021-06-11T05:07:42.397Z', 'my first post!', '2021-06-11T05:07:42.397Z') returning "id" [took 3 ms]
[query] rollback
TableNotFoundException: insert into "post" ("created_at", "title", "updated_at") values ('2021-06-11T05:07:42.397Z', 'my first post!', '2021-06-11T05:07:42.397Z') returning "id" - relation "post" does not exist
این خطا به ما می گوید که با موفقیت به پایگاه داده متصل شده ایم اما جدولی به نام Post در پایگاه داده ما وجود ندارد که بخواهیم عملیات INSERT را روی آن انجام بدهیم.
ساخت جدول با Migration ها
برای ساخت جدول در mikroorm دو راه حل اصلی وجود دارد:
- ساخت جدول Post به صورت دستی و مستقیما با PostgreSQL
- ساخت جدول Post با استفاده از migration ها در mikroorm
ساخت جدول به صورت دستی کار درستی نیست چرا که با قرار گرفتن برنامه روی سرور باید همه چیز را از صفر و دوباره تنظیم کنیم. برای استفاده از migration ها چطور؟ این روش بسیار بهتر است اما نیاز به پیکربندی دارد. migration ها فایل هایی هستند که جدول های پایگاه داده شما را توصیف می کنند و فقط با یک دستور از طریق CLI تمام جدول ها و خصوصیاتشان را در پایگاه داده ایجاد می کنند.
برای استفاده از migration ها ابتدا پکیج CLI از mikroorm را نصب می کنیم:
npm i @mikro-orm/cli ts-node
پکیج cli به ما اجازه می دهد از طریق CLI (همان ترمینال یا cmd) دستورات خاصی را اجرا کنیم. پکیج ts-node برای خواندن فایل های پیکربندی تایپ اسکریپت مربوط به CLI لازم است که در ادامه خواهید دید.
برای استفاده از CLI اولین قدم تعریف یک فایل پیکربندی به نام mikro-orm.config.ts در پوشه src است. پس از آنکه این فایل را ساختید شیء پاس داده شده به متد init در فایل index.ts را درون آن قرار می دهیم. چرا این کار را می کنیم؟ به دلیل اینکه دوست ندارم تمام تنظیمات را درون یک شیء بزرگ در index.ts داشته باشیم و فایل خودمان را شلوغ کنیم. من ترجیح می دهم تنظیمات جدا باشند. علاوه بر این، برای استفاده از migration ها نیاز است که فایل پیکربندی شما جدا باشد (در ادامه خواهید دید). محتوای فایل mikro-orm.config.ts باید به شکل زیر باشد:
import { __prod__ } from "./constants";
import { Post } from "./entities/Post";
import { MikroORM } from "@mikro-orm/core";
import path from "path";
export default {
migrations: {
path: path.join(__dirname, "./migrations"),
pattern: /^[\w-]+\d+\.[tj]s$/,
},
entities: [Post],
user: "amir",
password: "00000000",
dbName: "roxo_training",
type: "postgresql",
debug: !__prod__,
} as Parameters<typeof MikroORM.init>[0];
همانطور که می بینید من تنظیمات قبلی را دست نزده ام اما چند مورد ساده را اضافه کرده ام. در مرحله اول خصوصیت migrations را داریم که خودش دو فیلد می گیرد. فیلد اول path است که مسیر migration های ایجاد شده را مشخص می کند. من از ماژول path در node.js استفاده کرده ام تا یک مسیر مطلق ایجاد کنیم. با انجام این کار مطمئن می شویم در تمام سیستم های عامل و شرایط مختلف، مسیر پوشه migrations همیشه درست باشد. در قسمت pattern نیز یک الگوی regex را تعریف کرده ایم که وظیفه اش شناسایی فایل های js و ts است.
بخش مهم بعدی تعیین تایپ این شیء بود. برای اینکه این تایپ را مشخص کنیم از دستور خاصی در تایپ اسکریپت به نام Parameters استفاده کرده ایم. این دستور یک تابع را می گیرد و سپس تایپ پارامتر های آن را به صورت یک آرایه برمی گرداند. من تایپ تابع MikroORM.init را با استفاده از دستور typeof به آن داده ام. ما تایپ اولین آرگومان از متد init رامی خواهیم بنابراین اولین عضو از آرایه برگردانده شده را گرفته ایم. این کار را انجام داده ایم تا تایپ این شیء دقیق باشد. اگر اینطور نباشد در هنگام پاس دادن آن در index.ts از تایپ اسکریپت خطا می گیریم.
حالا به index.ts رفته و این شیء پیکربندی را به init پاس می دهیم:
import { MikroORM } from "@mikro-orm/core";
import { __prod__ } from "./constants";
import { Post } from "./entities/Post";
import mikroConfig from "./mikro-orm.config";
const main = async () => {
const orm = await MikroORM.init(mikroConfig);
const post = orm.em.create(Post, { title: "my first post!" });
await orm.em.persistAndFlush(post);
};
main().catch(err => console.error(err));
در مرحله بعدی باید تنظیمات خاصی را به فایل package.json وارد کنیم تا به mikroorm اجازه بدهد از طریق CLI عمل کند. این دستورات بسیار ساده هستند. من کل محتوای فایل package.json خودم تا این لحظه را برای شما قرار می دهم:
{
"name": "codebase",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"watch": "tsc -w",
"dev": "nodemon dist/index.js"
},
"keywords": [],
"author": "",
"license": "ISC",
"devDependencies": {
"@types/node": "^15.12.2",
"typescript": "^4.3.2"
},
"dependencies": {
"@mikro-orm/cli": "^4.5.6",
"@mikro-orm/core": "^4.5.6",
"@mikro-orm/postgresql": "^4.5.6",
"ts-node": "^10.0.0"
},
"mikro-orm": {
"useTsNode": true,
"configPaths": [
"./src/mikro-orm.config.ts",
"./dist/mikro-orm.config.js"
]
}
}
تنظیمات اضافه شده به این فایل، همان قسمت انتهایی آن (فیلد mikro-orm) است. اگر بخواهیم فایل پیکربندی ما یک فایل تایپ اسکریپت (پسوند ts) باشد باید خصوصیت useTsNode را روی true بگذاریم. mikroorm از ts-node برای خواندن فایل پیکربندی استفاده می کند و به همین دلیل بود که از همان ابتدا پکیج ts-node را نصب کرده بودیم. فیلد configPaths نیز برای مشخص کردن مسیر فایل پیکربندی است.
در مرحله بعدی نیاز به یک فایل migration داریم. برای ساخت این فایل به ترمینال (یا cmd برای کاربران ویندوز) رفته و دستور زیر را اجرا کنید:
npx mikro-orm migration:create
این دستور یک فایل migration را ساخته و چنین نتیجه ای به شما می دهد:
[discovery] ORM entity discovery started, using ReflectMetadataProvider [discovery] - processing entity Post [discovery] - entity discovery finished, found 1 entities, took 15 ms [info] MikroORM successfully connected to database roxo_training on postgresql://amir:*****@127.0.0.1:5432 [query] select table_name, nullif(table_schema, 'public') as schema_name from information_schema.tables where table_schema not like 'pg_%' and table_schema != 'information_schema' and table_name != 'geometry_columns' and table_name != 'spatial_ref_sys' and table_type != 'VIEW' order by table_name [took 601 ms] Migration20210611064436.ts successfully created
این پیام به ما می گوید که migration با موفقیت ساخته شده است. حالا اگر به پوشه src نگاه کنید یک پوشه جدید به نام migration را در آن خواهید دید. درون این پوشه یک فایل با نام Migration20210611064436.ts وجود دارد. توجه کنید که نام این فایل تاریخ ساختش را نیز در خود دارد بنابراین اعداد آن برای شما متفاوت خواهند بود. محتوای این فایل نیز در ابتدا به شکل زیر است:
import { Migration } from '@mikro-orm/migrations';
export class Migration20210611064436 extends Migration {
async up(): Promise<void> {
this.addSql('create table "post" ("id" serial primary key, "created_at" timestamptz(0) not null, "updated_at" timestamptz(0) not null, "title" varchar(255) not null);');
}
}
همانطور که می بینید هر migration در اصل یک کلاس است که متد های مختلفی دارد. متد up متدی است که مسئول ساخت یک جدول است و addSql نیز یک دستور SQL را گرفته و آن را اجرا می کند. دستور SQL ای که برای ساخت جدول می بینید، بهترین حدس mikroorm است اما ممکن است من با بعضی از قسمت هایش مخالف باشم. مثلا من دوست نداشته باشم ستون created_at از نوع (0)timestamptz باشد. چطور می توانیم این دستورات را تغییر بدهیم؟ دو راه حل وجود دارد:
- ویرایش دستی دستور SQL به سلیقه خودتان.
- مراجعه به فایل Post.ts و پاس دادن تایپ ها به decorator ها
برای پاس دادن تایپ به decorator می توانید به این شکل عمل کنید:
import { Property, Entity, PrimaryKey } from "@mikro-orm/core";
@Entity()
export class Post {
@PrimaryKey()
id!: number;
@Property({ type: "date" })
createdAt: Date = new Date();
@Property({ onUpdate: () => new Date() })
updatedAt: Date = new Date();
@Property()
title!: string;
}
همانطور که می بینید من تایپ ستون createdAt را روی date گذاشته ام که همان timestamptz را برایمان تولید می کند. این مثال فقط برای آشنایی شما بود. روش اول نیز ویرایش دستور SQL بود که من شخصا ترجیح می دهم بنابراین به فایل Migration20210611064436 برگشته و آن را بدین شکل ویرایش می کنم:
import { Migration } from "@mikro-orm/migrations";
export class Migration20210611064436 extends Migration {
async up(): Promise<void> {
this.addSql(
'create table "post" ("id" integer primary key generated always as identity, "created_at" timestamptz(0) not null, "updated_at" timestamptz(0) not null, "title" varchar(255) not null);'
);
}
}
در صورتی که چندین بار دستور ساخت migration را اجرا کرده اید حتما پوشه dist را حذف کرده و npm run watch را دوباره اجرا کنید. چرا؟ به دلیل اینکه با اجرای چند باره دستور ساخت migration، چندین migration در پوشه dist وجود خواهند داشت که با هم تداخل دارند بنابراین باید یک بار دیگر پروژه را از ابتدا کامپایل کنیم.
حالا به فایل index.ts برمی گردیم و این بار دستور اجرای migration را اجرا می کنیم:
const main = async () => {
const orm = await MikroORM.init(mikroConfig);
await orm.getMigrator().up();
const post = orm.em.create(Post, { title: "my first post!" });
await orm.em.persistAndFlush(post);
};
main().catch(err => console.error(err));
دستور up تمام migration های ما را اجرا می کند. حالا اگر به ترمینال نگاه کنید باید چنین خروجی ببینید:
// بقیه گزارش
[query] create table "mikro_orm_migrations" ("id" serial primary key, "name" varchar(255), "executed_at" timestamptz default current_timestamp)
[query] begin
[query] select * from "mikro_orm_migrations" order by "id" asc [took 16 ms]
[query] select * from "mikro_orm_migrations" order by "id" asc [took 2 ms]
== Migration20210611064436: migrating =======
[query] savepoint trx3
[query] set names 'utf8'; [took 1 ms]
[query] set session_replication_role = 'replica'; [took 0 ms]
[query] create table "post" ("id" integer primary key generated always as identity, "created_at" timestamptz(0) not null, "updated_at" timestamptz(0) not null, "title" varchar(255) not null); [took 98 ms]
[query] set session_replication_role = 'origin'; [took 1 ms]
[query] release savepoint trx3
[query] insert into "mikro_orm_migrations" ("name") values ('Migration20210611064436.js') [took 19 ms]
== Migration20210611064436: migrated (0.140s)
[query] commit
[query] begin
[query] insert into "post" ("created_at", "title", "updated_at") values ('2021-06-11T06:52:06.439Z', 'my first post!', '2021-06-11T06:52:06.439Z') returning "id" [took 15 ms]
[query] commit
همانطور که می بینید اولین پست ما به سادگی در پایگاه داده ثبت شده است! همچنین جدولی به نام mikro_orm_migrations نیز به صورت خودکار توسط mikroorm ساخته شده است که لیستی از migration های انجام شده را در خود دارد و ما با آن کاری نداریم. جدول دومی که به صورت خودکار ساخته شده است Post نام دارد که همنام کلاس Post (فایل entities) می باشد. در حال حاضر اگر به psql (بخش مدیریتی PostgreSQL در ترمینال) بروید و به جدول Post نگاهی بیندازید، چنین چیزی را می بینید:
Table "public.post" Column | Type | Collation | Nullable | Default ------------+-----------------------------+-----------+----------+------------------------------ id | integer | | not null | generated always as identity created_at | timestamp(0) with time zone | | not null | updated_at | timestamp(0) with time zone | | not null | title | character varying(255) | | not null | Indexes: "post_pkey" PRIMARY KEY, btree (id)
با این حساب همه چیز دقیقا طبق خواسته ما پیش رفته است.
همچنین اگر می خواهید پست اضافه شده به پایگاه داده را مشاهده کنید هم می توانید از محیط psql عمل کرده و هم از فایل index.ts اقدام کنید:
const main = async () => {
const orm = await MikroORM.init(mikroConfig);
await orm.getMigrator().up();
// const post = orm.em.create(Post, { title: "my first post!" });
// await orm.em.persistAndFlush(post);
const posts = await orm.em.find(Post, {});
console.info(posts);
};
برای اینکه پست تکراری به پایگاه داده ما اضافه نشود من دو خط مسئول این کار را کامنت کرده ام. از طرف دیگر دستور find را اجرا کرده ام که به عنوان آرگومان اول یک entity و به عنوان آرگومان دوم یک فیلتر را می گیرد. من هیچ چیزی را به فیلتر پاس نداده ام که یعنی فیلتری نداریم و همه داده ها باید برگردانده شوند بنابراین همه ردیف های جدول post برگردانده می شوند و ما آن ها را log کرده ایم. با اجرای این دستور باید چنین نتیجه ای را در ترمینال ببینید:
[query] select "e0".* from "post" as "e0" [took 1 ms]
[
Post {
id: 1,
createdAt: 2021-06-11T06:52:06.000Z,
updatedAt: 2021-06-11T06:52:06.000Z,
title: 'my first post!'
}
]
حالا که مطمئن شدیم همه چیز برایمان برگردانده می شود می توانیم دستور find و log را نیز کامنت کنیم. این ساختار کلی کار با mikro orm در پروژه ما بود. در ادامه پروژه دائما به آن برمی گردیم و آن را ویرایش می کنیم چرا که باید جدول های جدید و ستون های جدیدی را تعریف کنیم.
نصب Apollo-server و Express و GraphQL
حالا که به پایگاه داده سر و سامان داده ایم باید به سراغ نصب پکیج های زیر برویم:
npm i express @types/express apollo-server-express graphql type-graphql
- پکیج express سرور node.js ما است.
- پکیج types/express@ تایپ های express را اضافه می کند تا بتوانیم با تایپ اسکریپت با آن کار کنیم.
- پکیج apollo-server-express به ما اجازه می دهد یک سرور graphQL را روی express پیاده سازی کنیم.
- پکیج های graphql و type-graphql را نیز برای تعریف schema نیاز خواهیم داشت.
با اجرای دستور بالا پکیج های مورد نظر برایتان نصب می شوند.
روند کلی کار با apollo-server و graphql این است که باید در ابتدا چیزی به نام resolver را تعریف کنیم. resolver ها همان توابعی هستد که مشخص می کنند یک Endpoint در GarphQL چطور باید رفتار کند بنابراین در پوشه src یک پوشه جدید به نام resolvers را ایجاد کنید و داخل آن فایلی به نام hello.ts را بسازید. محتویات درون این فایل باید بدین شکل باشد:
import { Query, Resolver } from "type-graphql";
@Resolver()
export class HelloResolver {
@Query(() => String)
hello() {
return "hello world";
}
}
همانطور که می بینید ما ابتدا دو decorator به نام های Query و Resolver را از پکیج type-graphql وارد کرده ایم. در مرحله بعدی یک کلاس را ساخته و export کرده ایم که از decorator اول استفاده می کند. درون این کلاس باید متد هایی را بنویسید یا Mutation (نوشتن داده) هستند یا Query (خواندن داده) محسوب می شوند. من یک متد ساده به نام hello را تعریف کرده ام که رشته hello world را برمی گرداند. در ضمن باید از decorator دوم نیز استفاده کنیم و تایپ برگردانده شده را به صورت یک تابع به آن پاس بدهیم. طبیعتا ما یک رشته را برمی گردانیم بنابراین از String استفاده کرده ام. در نظر داشته باشید که در GraphQL باید به همین شکل (یعنی با S بزرگ) نوع داده String را مشخص کنید. فعلا همین یک mutation برای تست کردن برنامه کافی است.
در مرحله بعدی به فایل index.ts برمی گردیم و ابتدا با express یک سرور می سازیم. در مرحله بعدی یک سرور apollo-server را ساخته و exprerss را به آن پاس می دهیم. در واقع محتوای فایل index.ts من در حال حاضر بدین شکل است:
import { MikroORM } from "@mikro-orm/core";
import express from "express";
import { __prod__ } from "./constants";
import mikroConfig from "./mikro-orm.config";
import { ApolloServer } from "apollo-server-express";
import { buildSchema } from "type-graphql";
import { HelloResolver } from "./resolvers/hello";
const main = async () => {
const orm = await MikroORM.init(mikroConfig);
await orm.getMigrator().up();
const app = express();
const apolloServer = new ApolloServer({
schema: await buildSchema({
resolvers: [HelloResolver],
}),
});
apolloServer.applyMiddleware({ app });
app.listen(4000, () => {
console.log("server running on localhost:4000");
});
};
main().catch(err => console.error(err));
همانطور که می بینید برای ساخت سرور apollo باید یک حداقل یک خصوصیت به نام schema را به آن پاس بدهیم اما ساختن schema کار apollo نیست بلکه apollo فقط schema ساخته شده را دریافت کرده و روی سرور سوار می کند. برای ساخت GraphQL schema باید از پکیج type-graphql استفاده کنیم که یک متد ناهمگام به نام buildSchema را به ما می دهد بنابراین باید await شود. تنها خصوصیتی که در این بخش نیاز داریم همان resolvers است که من تنها resolver خودمان را به آن پاس داده ام. نهایتا با متد applyMiddleware برنامه ساخته شده توسط express (همان app) را به apollo-server پاس داده ایم تا graphql را روی سرور express ما قرار بدهد.
حالا باید سرور خودمان را تست کنیم. برای تست ابتدا مطمئن شوید که دستورات npm run watch و npm run dev مثل همیشه در حال اجرا هستند، سپس به http://localhost:4000 بروید. از آنجایی که هیچ مسیری برای express تعریف نکرده ایم طبیعتا با خطای Cannot GET مواجه می شویم که طبیعی است. نکته بسیار جالب این است که یک ابزار برای تست کوئری های GraphQL به صورت خودکار در اختیار ما گذاشته شده است، تنها کافی است که عبارت graphql را به انتهای آدرس اصلی خود اضافه کنید. این مقدار برای من http://localhost:4000/graphql است. با مراجعه به این آدرس ابزار تست کوئری خود را خواهید دید:
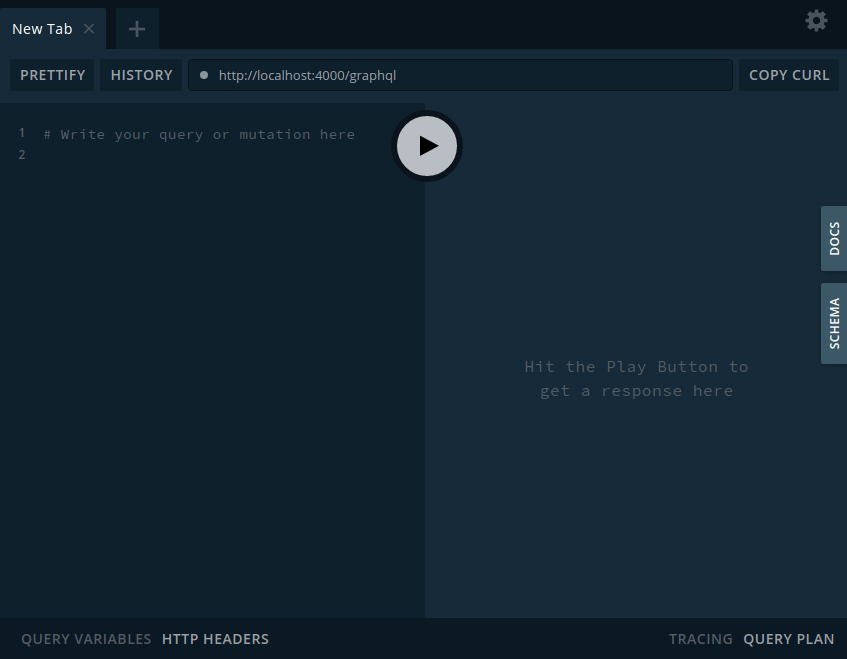
اگر روی گزینه docs در سمت راست صفحه (تصویر بالا) کلیک کنید، ساختار schema خود را به راحتی مشاهده خواهید کرد:
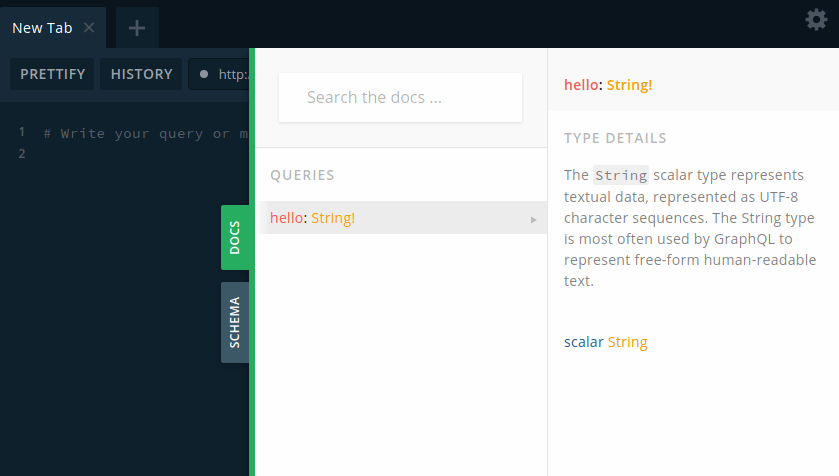
همانطور که می بینید توضیحات مربوطه نیز به صورت خودکار برای ما درج شده است! حالا بیایید آن را تست کنیم. ما فعلا فقط یک resolver به نام hello را داریم بنابراین همان را تست می کنیم. برای کوئری زدن به GraphQL باید ابتدا از علامت های {} استفاده کنید (دقیقا مانند زمانی که می خواهید یک شیء را تعریف کنید) و سپس نام کوئری خود را بنویسید:
{
hello
}
سپس با کلیک روی دکمه play در وسط صفحه، نتیجه را در سمت راست خواهید دید:
{
"data": {
"hello": "hello world"
}
}
شما می توانید این فرآیند را در تصویر زیر مشاهده کنید:
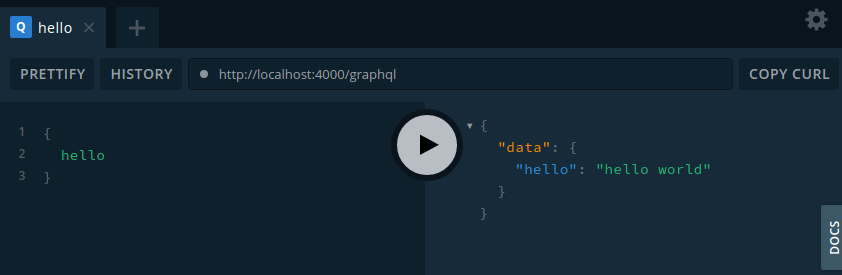
به شما تبریک می گویم، به همین سادگی یک سرور GraphQL را راه اندازی کرده اید!
ترکیب resolver ها با MikroORM
شما می توانید resolver هایتان را با MikroORM ترکیب کنید. برای اینکه این مسئله را به شما نشان بدهم، ابتدا در پوشه resolvers یک فایل دیگر به نام post.ts بسازید. ما هنوز نمی توانیم آن را کدنویسی کنیم.
حالا باید به فایل index.ts رفته و شیء orm را به آن پاس بدهیم. چرا؟ به دلیل اینکه ما می خواهیم درون resolver ها به MikroORM دسترسی داشته باشیم تا بتوانیم هر چیزی را که می خواهیم از پایگاه داده دریافت کنیم:
// بقیه کدها
const app = express();
const apolloServer = new ApolloServer({
schema: await buildSchema({
resolvers: [HelloResolver],
}),
context: () => ({ em: orm.em }),
});
// بقیه کدها
خصوصیت context یک خصوصیت ویژه است که بین تمام resolver ها به اشتراک گذاشته می شود بنابراین با پاس دادن شیء orm.em به آن، می توانیم در تمام resolver ها از پایگاه داده استفاده کنیم. حالا زمانی که بخواهیم از context استفاده کنیم باید یک تایپ را نیز برایش تعیین کنیم چرا که در حال کار با تایپ اسکریپت هستیم. برای این کار من به پوشه src رفته و یک فایل جدید به نام types.ts را در آن ایجاد می کنم. ما فقط باید تایپ em را در آن مشخص کنیم چرا که context ما فقط همین خصوصیت را دارد. چطور تایپ em را مشخص کنیم؟ اگر در همان فایل index.ts موس خود را روی em ببرید می توانید تایپ آن را مشاهده کنید. من از همان تایپ استفاده می کنم:
import { EntityManager, IDatabaseDriver, Connection } from "@mikro-orm/core";
export type MyContext = {
em: EntityManager<any> & EntityManager<IDatabaseDriver<Connection>>;
};
این تایپ مورد نظر ما برای em است که آن را عملا از پکیج mikro-orm/core برداشته ایم. در مرحله بعدی به فایل post.ts در پوشه resolvers می رویم و محتویاتش را به شکل زیر می نویسیم:
import { Post } from "../entities/Post";
import { MyContext } from "src/types";
import { Ctx, Query, Resolver } from "type-graphql";
@Resolver()
export class PostResolver {
@Query(() => [Post])
posts(@Ctx() { em }: MyContext): Promise<Post[]> {
return em.find(Post, {});
}
}
همانطور که می بینید ابتدا باید decorator ای به نام Resolver را روی کلاس مورد نظرمان صدا بزنیم. در مرحله بعدی Query@ را صدا می زنیم تا مشخص کنیم این متد یک Query است و نوع داده های برگردانده شده را آرایه ای از Post می گذاریم. در GraphQL برای نوشتن آرایه ای از یک چیز، یک آرایه را قرار داده و آن چیز را درون آرایه قرار می دهیم، در حالی که در تایپ اسکریپت باید علامت آرایه را بعد از آن چیز قرار بدهید. تعیین تایپ برگردانده شده در قسمت Query@ برای GraphQL و کسانی است که می خواهند توسعه front-end را انجام بدهند، تا بدانند دقیقا چه چیزی دریافت خواهند کرد.
در این بخش با صدا زدن یک decorator دیگر به نام Ctx می توانیم به شیء context و محتوایش دسترسی داشته باشیم. من در این بخش با destructuring شیء em را از context خارج کرده ام و تایپ آن را روی MyContext قرار داده ام که قبلا تعریف کرده بودیم. همچنین تایپ برگردانده شده توسط آن یک promise است که بعد از resolve شدن آرایه ای از پست ها را برایمان برمی گرداند. حالا می توانیم با استفاده از em.find در پایگاه داده جست و جو کنیم و همانطور که می بینید من تمام پست های موجود در آن را برگردانده ام.
همانطور که می دانید Post در حال حاضر یک entity است که متعلق به mikro orm است و ارتباطی با GraphQL ندارد بنابراین فعلا کدهایمان کار نمی کند. برای حل این مشکل به entities/Post.ts می رویم و با استفاده از decorator های پکیج type-graphql آن را به یک تایپ GraphQL نیز تبدیل می کنیم:
import { Property, Entity, PrimaryKey } from "@mikro-orm/core";
import { Field, ID, ObjectType } from "type-graphql";
@ObjectType()
@Entity()
export class Post {
@Field(() => ID)
@PrimaryKey()
id!: number;
@Field(() => String)
@Property()
createdAt: Date = new Date();
@Field(() => String)
@Property({ onUpdate: () => new Date() })
updatedAt: Date = new Date();
@Field()
@Property()
title!: string;
}
با صدا زدن objectType این کلاس را به یک تایپ GraphQL تبدیل می کنیم. در مرحله بعدی از Field@ استفاده می کنیم تا به GraphQL بگوییم هر کدام از این خصوصیات در این کلاس یک فیلد GraphQL است. همچنین در نظر داشته باشید که باید تایپ هر کدام از این Field ها را صریحا مشخص کنید چرا که در بعضی از موارد GraphQL نمی تواند تایپ را حدس بزند. مثلا تایپی به نام Date در type-graphql نداریم بنابراین من تایپ هایشان را String گذاشته ام. فیلد آخر که title است به طور صریح تایپ string را دارد بنابراین GraphQL خودش می تواند نوع آن را حدس بزند گرچه می توانید نوع آن را خودتان به صورت دستی نیز مشخص کنید. با انجام این کار مشکلاتمان حل می شود. در مرحله بعدی به فایل index.ts برگشته و این resolver جدید را به مجموعه resolver هایمان اضافه می کنیم:
const app = express();
const apolloServer = new ApolloServer({
schema: await buildSchema({
resolvers: [HelloResolver, PostResolver],
}),
context: () => ({ em: orm.em }),
});
حالا مطمئن شوید سرور ریستارت شده است و به آدرس http://localhost:4000/graphql بروید. با کلیک روی سربرگ DOCS یا Schema می توانید ساختار مورد نظرمان را مشاهده کنیم. حالا در سمت چپ صفحه کوئری زیر را می نویسیم:
{
posts {
id,
createdAt,
updatedAt,
title,
}
}
با اجرای این کوئری نتیجه زیر را می گیریم:
{
"data": {
"posts": [
{
"id": "1",
"createdAt": "1623394326000",
"updatedAt": "1623394326000",
"title": "my first post!"
}
]
}
}
بنابراین به همین راحتی توانسته ایم Mikro ORM و type-graphql را ترکیب کنیم. اگر این کار را نمی کردیم باید برای graphql یک کلاس جداگانه تعریف می کردیم. در ضمن توجه داشته باشید که ما فقط یک پست را در پایگاه داده داریم بنابراین فقط همین یک پست برایمان برگردانده شده است. در صورتی که چند پست دیگر را نیز اضافه کنید همه آن ها برایتان برگردانده می شوند.
حالا سوالی مهم پیش می آید. در حال حاضر entities/Post.ts هم entity ما برای Mikro ORM است و هم یک تایپ برای GraphQL، بنابراین کاربران می توانند به تمام فیلد های پایگاه داده ما دسترسی داشته باشند. درست است؟ با این حساب اگر کاربران به فیلد های حساس مانند شماره تلفن و ایمیل کاربران دیگر دسترسی پیدا کنند چطور؟ برای حل این مشکل کافی است Field@ را روی فیلد های حساس پایگاه داده که خصوصی هستند صدا نزنید. مثلا اگر title در پایگاه داده ما یک فیلد خصوصی است باید به entities/post.ts رفته و بگوییم:
import { Property, Entity, PrimaryKey } from "@mikro-orm/core";
import { Field, ID, ObjectType } from "type-graphql";
@ObjectType()
@Entity()
export class Post {
@Field(() => ID)
@PrimaryKey()
id!: number;
@Field(() => String)
@Property()
createdAt: Date = new Date();
@Field(() => String)
@Property({ onUpdate: () => new Date() })
updatedAt: Date = new Date();
@Property()
title!: string;
}
همانطور که می بینید من Field@ را از فیلد title حذف کرده ام. حالا اگر به مرورگر (آدرس http://localhost:4000/graphql) برگردیم و همان کوئری قبلی را اجرا کنیم چه می شود؟
{
posts {
id,
createdAt,
updatedAt,
title,
}
}
در این کوئری title را درخواست کرده ایم. با اجرای این کوئری خطای زیر برایمان برگردانده می شود:
{
"error": {
"errors": [
{
"message": "Cannot query field \"title\" on type \"Post\".",
"locations": [
{
"line": 6,
"column": 5
}
],
"extensions": {
"code": "GRAPHQL_VALIDATION_FAILED",
"exception": {
"stacktrace": [
"GraphQLError: Cannot query field \"title\" on type \"Post\".",
" at Object.Field (/media/amir/Development/GraphQL/codebase/node_modules/graphql/validation/rules/FieldsOnCorrectTypeRule.js:48:31)",
" at Object.enter (/media/amir/Development/GraphQL/codebase/node_modules/graphql/language/visitor.js:323:29)",
" at Object.enter (/media/amir/Development/GraphQL/codebase/node_modules/graphql/utilities/TypeInfo.js:370:25)",
" at visit (/media/amir/Development/GraphQL/codebase/node_modules/graphql/language/visitor.js:243:26)",
" at Object.validate (/media/amir/Development/GraphQL/codebase/node_modules/graphql/validation/validate.js:69:24)",
" at validate (/media/amir/Development/GraphQL/codebase/node_modules/apollo-server-core/dist/requestPipeline.js:233:34)",
" at Object.<anonymous> (/media/amir/Development/GraphQL/codebase/node_modules/apollo-server-core/dist/requestPipeline.js:119:42)",
" at Generator.next (<anonymous>)",
" at fulfilled (/media/amir/Development/GraphQL/codebase/node_modules/apollo-server-core/dist/requestPipeline.js:5:58)",
" at processTicksAndRejections (node:internal/process/task_queues:96:5)"
]
}
}
}
]
}
}
یعنی اصلا فیلدی به نام title برای GrarphQL تعریف نشده است بنابراین خطا گرفته ایم. در حال حاضر کوئری صحیح بدین شکل است:
{
posts {
id,
createdAt,
updatedAt,
}
}
از آنجایی که من title را می خواهم، دوباره Field را به آن اضافه می کنم اما این مثال را به یاد داشته باشید تا در پروژه های خود بدین شکل از آن استفاده کنید.
تکمیل Resolver برای پست ها (عملیات CRUD)
حالا که اولین عملیات خود را با موفقیت انجام داده ایم بهتر است به resolvers/post.ts برگردیم و عملیات های دیگر را نیز برایش تعریف کنیم. در حال حاضر فقط یک عملیات Query@ داشتیم که برای دریافت داده است اما برای ویرایش و ثبت داده باید یک Mutation داشته باشیم. قبل از اینکه بخواهیم به سراغ چنین چیزی برویم باید Query دیگر را تعریف کنیم که پست ها را بر اساس id خاصی دریافت می کند. زمانی که کاربر به دنبال دریافت یک پست خاص است باید id آن پست را داشته باشد بنابراین یکی از دو حالت زیر رخ می دهد:
- id ارسال شده در پایگاه داده وجود دارد و پست برای کاربر برگردانده می شود.
- id ارسال شده در پایگاه داده وجود ندارد بنابراین به او می گوییم چنین پستی وجود ندارد.
با این حساب می توان گفت:
import { Post } from "../entities/Post";
import { MyContext } from "src/types";
import { Arg, Ctx, Int, Query, Resolver } from "type-graphql";
@Resolver()
export class PostResolver {
@Query(() => [Post])
posts(@Ctx() { em }: MyContext): Promise<Post[]> {
return em.find(Post, {});
}
@Query(() => Post, { nullable: true })
post(
@Arg("id", () => Int) id: number,
@Ctx() { em }: MyContext
): Promise<Post | null> {
return em.findOne(Post, { id });
}
}
همانطور که می بینید ما یک Query را تعریف کرده ایم اما تایپ برگردانده شده توسط آن را به یکی از همان دو حالت تغییر داده ایم. یعنی گفته ایم این کوئری یک Post را برمی گرداند اما آرگومان دومی را نیز پاس داده ایم که می گوید nullable است یعنی ممکن است به جای Post هیچ داده ای برگردانده نشود. در مرحله بعدی Arg@ را صدا زده ایم که آرگومان دریافتی از سمت کاربر را تعریف می کند. ابتدا یک نام را برایش انتخاب می کنیم که من رشته id را انتخاب کرده ام و در بخش بعدی نیز تایپ برگردانده شده آن را مشخص می کنیم که من Int را انتخاب کرده ام. بقیه کدها مانند بخش قبل است با این تفاوت که از findOne استفاده کرده ایم و id را به عنوان فیلتر پاس داده ایم.
باید یک نکته مهم را درباره کد بالا گوشزد کنم:
// بقیه کدها
@Arg("id", () => Int) id: number,
// بقیه کدها
آرگومان "id" که به صورت رشته به Arg پاس داده ایم، نام آرگومان پاس داده شده به کوئری را تعیین می کند. مثلا اگر نامش را به جای id چیزی مثل identifier بگذاریم، کاربران کوئری زدن به سرور باید نام آرگومان خود را identifier بگذارند. از طرف دیگر آرگومان id: number همان آرگومانی است که به متد post پاس داده شده است و از آن در متد findOne استفاده کرده ایم.
برای تست این کدها دوباره به http://localhost:4000/graphql برمی گردیم و این بار کوئری زیر را اجرا می کنیم:
{
post (id: 1) {
title
}
}
یعنی به دنبال پستی با آیدی ۱ هستیم و عنوان آن را می خواهیم. نتیجه اجرای این کوئری بدین شکل خواهد بود:
{
"data": {
"post": {
"title": "my first post!"
}
}
}
با این حساب برای شما تمرینی دارم. عملیات CRUD را در همین فایل و بر اساس همین چیز هایی که گفته شد پیاده سازی کنید. سعی کنید خودتان این کار را انجام بدهید و سپس به پاسخ من نگاه کنید:
import { Post } from "../entities/Post";
import { MyContext } from "src/types";
import { Arg, Ctx, Int, Mutation, Query, Resolver } from "type-graphql";
@Resolver()
export class PostResolver {
@Query(() => [Post])
posts(@Ctx() { em }: MyContext): Promise<Post[]> {
return em.find(Post, {});
}
@Query(() => Post, { nullable: true })
post(
@Arg("id", () => Int) id: number,
@Ctx() { em }: MyContext
): Promise<Post | null> {
return em.findOne(Post, { id });
}
@Mutation(() => Post)
async createPost(
@Arg("title") title: string,
@Ctx() { em }: MyContext
): Promise<Post> {
const post = em.create(Post, { title });
await em.persistAndFlush(post);
return post;
}
@Mutation(() => Post, { nullable: true })
async updatePost(
@Arg("id") id: number,
@Arg("title", () => String, { nullable: true }) title: string,
@Ctx() { em }: MyContext
): Promise<Post | null> {
const post = await em.findOne(Post, { id });
if (!post) {
return null;
}
if (typeof title !== "undefined") {
post.title = title;
await em.persistAndFlush(post);
}
return post;
}
@Mutation(() => Boolean)
async deletePost(
@Arg("id") id: number,
@Ctx() { em }: MyContext
): Promise<boolean> {
try {
await em.nativeDelete(Post, { id });
return true;
} catch (error) {
return false;
}
}
}
همانطور که می دانید در GraphQL برای ویرایش داده ها نیاز به یک mutation داریم بنابراین به جای Query@ از Mutation@ استفاده کرده ایم. اولین mutation ما برای ثبت یک پست جدید با متد createPost است. ابتدا یک title را به عنوان آرگومان دریافت کرده ایم و سپس با متد create آن را در پایگاه داده ثبت می کنیم.
mutation بعدی ما ویرایش پست ها با متد updatePost است که یک id و یک title را دریافت می کند. من می خواهم title یک فیلد اجباری نباشد بنابراین آن را nullable کرده ام. توجه کنید که اگر بخواهید یک فیلد را nullable کنید باید حتما تایپ آن را به صورت دستی مشخص کنید و من هم همین کار را کرده ام (آن را روی String گذاشته ام). در مرحله بعدی به دنبال چنین پستی گشته ایم و اگر وجود نداشت فقط null را برمی گردانیم، در غیر این صورت پست را ویرایش کرده و برمی گردانیم.
در نهایت نیز یک mutation برای حذف پست ها داریم که به سادگی پست را با استفاده از id خودش حذف می کند. من آن را در یک بلوک try & catch نیز گذاشته ام تا بعدا به شما نشان بدهم این روش، روش صحیحی نیست. بسته به نتیجه حذف عنصر ما true یا false را برمی گردانیم.
حالا باید برای تست این کوئری ها به http://localhost:4000/graphql برویم. در قدم اول یک پست جدید می سازیم:
mutation {
createPost (title: "This is a mutation") {
id,
createdAt,
updatedAt,
title,
}
}
برای نوشتن کوئری هایی که از نوع mutation هستند باید حتما عبارت mutation را نوشته و کوئری خود را درون آن ذکر کنید. با اجرای این کوئری چنین نتیجه ای را می گیرید:
{
"data": {
"createPost": {
"id": "5",
"createdAt": "1623564826979",
"updatedAt": "1623564826979",
"title": "This is a mutation"
}
}
}
بنابراین پست ما به سادگی ویرایش شده است. در مرحله بعدی می خواهیم این پست را ویرایش کنیم بنابراین می گوییم:
mutation {
updatePost (id: 5, title: "An updated title for this") {
id,
title
}
}
با اجرای این کوئری نتیجه زیر را دریافت می کنید:
{
"data": {
"updatePost": {
"id": "5",
"title": "An updated title for this"
}
}
}
برای مطمئن شدن از صحت این عملیات یک کوئری ساده را به پایگاه داده می زنیم تا تمام پست هایمان را دریافت کنیم:
{
posts{
id,
createdAt,
updatedAt,
title,
}
}
با اجرای این کوئری نتیجه زیر را می گیرید:
{
"data": {
"posts": [
{
"id": "1",
"createdAt": "1623394326000",
"updatedAt": "1623394326000",
"title": "my first post!"
},
{
"id": "4",
"createdAt": "1623499878000",
"updatedAt": "1623499878000",
"title": "My Second post."
},
{
"id": "5",
"createdAt": "1623562850000",
"updatedAt": "1623564935936",
"title": "An updated title for this"
}
]
}
}
همانطور که می بینید پست ما به شکل صحیح ویرایش شده است.
تنها عملیاتی که باقی مانده است، حذف پست ها است. من یک بار دیگر کوئری ثبت پست جدید را اجرا می کنم تا یک پست جدید دیگر داشته باشیم. id این پست برای من ۶ است اما ممکن است برای شما تفاوت داشته باشد. حالا کوئری زیر را برای آن می نویسم:
mutation {
deletePost(id: 6)
}
با اجرای این کوئری چنین نتیجه ای برایمان برگردانده می شود:
{
"data": {
"deletePost": true
}
}
حالا اگر یک آیدی غیر واقعی مثل ۹۹۹ را به این کوئری پاس بدهیم چه می شود؟ باز هم true را می گیریم. چرا؟ به دلیل اینکه اگر سعی در حذف پستی داشته باشیم که اصلا وجود ندارد، پایگاه داده به خطا برمی خورد اما اسکریپت ما exception پرتاب نمی کند بنابراین هیچ گاه وارد بخش catch از deletePost نمی شویم. متد nativeDelete در صورتی که بتواند ردیف مورد نظر را پیدا کرده و حذف کند عدد ۱ را برمی گرداند و در غیر این صورت عدد 0 برگردانده می شود. با این حساب می توانیم این متد را به شکل زیر ویرایش کنیم:
@Mutation(() => Boolean)
async deletePost(
@Arg("id") id: number,
@Ctx() { em }: MyContext
): Promise<boolean> {
const result = await em.nativeDelete(Post, { id });
if (result === 1) {
return true;
} else {
return false;
}
}
حالا اگر یک آیدی غیر واقعی مانند ۹۹ را وارد کنید false می گیرید اما برای id های واقعی true را دریافت خواهید کرد.
فرآیند احراز هویت: ساخت جدول User
برای احراز هویت کاربران باید ابتدا یک entity به نام users را ایجاد کنیم و سپس resolver های مورد نظرش را تعریف کنیم. برای شروع به پوشه entities رفته و فایل جدیدی به نام User.ts را ایجاد کنید. از آنجایی که قبلا با entities/Post.ts کار کرده ایم انتظار دارم بتوانید خودتان User.ts را بنویسید. این مسئله را به عنوان یک تمرین برای خودتان حل کنید و سپس به پاسخ من توجه کنید:
import { Property, Entity, PrimaryKey } from "@mikro-orm/core";
import { Field, ID, ObjectType } from "type-graphql";
@ObjectType()
@Entity()
export class User {
@Field(() => ID)
@PrimaryKey()
id!: number;
@Field(() => String)
@Property()
createdAt: Date = new Date();
@Field(() => String)
@Property({ onUpdate: () => new Date() })
updatedAt: Date = new Date();
@Field()
@Property({ unique: true })
username!: string;
@Property({ type: "text" })
password!: string;
}
با این حساب هر کاربر یک username دارد که باید unique یا یکتا (غیرتکراری) باشد و همچنین فیلد رمز عبور را داریم که تایپ آن را text گذاشته ام تا فضا کم نیاوریم. شما می توانید انواع داده دیگر را نیز انتخاب کنید اما من text را برای رمز عبور ترجیح می دهم. توجه داشته باشید که من Field@ را به password اضافه نکرده ام چرا که نمی خواهم کسی اجازه داشته باشد رمز عبور دیگر کاربران را مشاهده کند. بقیه موارد تکراری هستند.
از آنجایی که ما migration های زیادی را انجام می دهیم من می خواهم یک اسکریپت جداگانه را برایشان تعریف کنم. برای این کار به package.json می رویم:
"scripts": {
"watch": "tsc -w",
"dev": "nodemon dist/index.js",
"c:migration": "mikro-orm migration:create"
},
از این به بعد می توانیم با اجرای دستور npm run c:migration یک migration جدید بسازیم. البته هنوز نمی توانیم این دستور را اجرا کنیم. ابتدا به فایل mikro-orm.config.ts می رویم تا entity جدید خود را به mikro orm پاس بدهیم. در حال حاضر پیکربندی این فایل به شکل زیر است:
import { __prod__ } from "./constants";
import { MikroORM } from "@mikro-orm/core";
import path from "path";
import { Post } from "./entities/Post";
export default {
migrations: {
path: path.join(__dirname, "./migrations"),
pattern: /^[\w-]+\d+\.[tj]s$/,
},
entities: [Post],
user: "amir",
password: "00000000",
host: "localhost",
dbName: "roxo_training",
type: "postgresql",
debug: !__prod__,
} as Parameters<typeof MikroORM.init>[0];
با این حساب یا باید برای تک تک entity هایمان به این فایل بیاییم و آن ها را به صورت دستی اضافه کنیم (مانند کاری که با Post در کد بالا کرده ایم) یا اینکه مسیر entity هایمان را به آن بدهیم. من روش دوم را انتخاب می کنم چرا که راحت تر است:
export default {
migrations: {
path: path.join(__dirname, "./migrations"),
pattern: /^[\w-]+\d+\.[tj]s$/,
},
entities: ["dist/entities/*.js"],
user: "amir",
password: "00000000",
host: "localhost",
dbName: "roxo_training",
type: "postgresql",
debug: !__prod__,
} as Parameters<typeof MikroORM.init>[0];
با این کار mikro orm خودش هر فایلی با پسوند js در پوشه entities را به عنوان یک entity شناسایی می کند بنابراین نیازی نیست هر بار به صورت دستی این کار را انجام بدهیم. حالا که Mikro ORM از entity هایمان خبر دارد می توانیم دستور npm run c:migration را اجرا کنیم. با اجرای این دستور migration قبلی ما برای جدول Post بدون مشکل خواهد بود اما یک migration جدید برای جدول User ایجاد خواهد شد که چنین محتوایی را دارد:
import { Migration } from '@mikro-orm/migrations';
export class Migration20210613065044 extends Migration {
async up(): Promise<void> {
this.addSql('create table "user" ("id" serial primary key, "created_at" timestamptz(0) not null, "updated_at" timestamptz(0) not null, "username" varchar(255) not null, "password" text not null);');
this.addSql('alter table "user" add constraint "user_username_unique" unique ("username");');
}
}
همانطور که قبلا هم توضیح دادم من دوست ندارم ستون primary key من از نوع serial باشد بنابراین آن را به identity تغییر می دهم:
// بقیه کدها
async up(): Promise<void> {
this.addSql('create table "user" ("id" integer primary key generated always as identity, "created_at" timestamptz(0) not null, "updated_at" timestamptz(0) not null, "username" varchar(255) not null, "password" text not null);');
this.addSql('alter table "user" add constraint "user_username_unique" unique ("username");');
}
// بقیه کدها
بقیه ستون ها مناسب هستند بنابراین نیازی به ویرایش آن ها نداریم. این migration به صورت خودکار روی پایگاه داده ما پیاده شده است. چطور؟ در فایل index.ts کد زیر را نوشته بودیم:
await orm.getMigrator().up();
بنابراین همه چیز به صورت خودکار انجام می شود.
توجه داشته باشید که Mikro ORM هیچ وقت migration های قبلی را دوباره اجرا نمی کند. Mikro ORM جدولی به نام mikro_orm_migrations را در پایگاه داده شما می سازد و لیستی از تمام migration های اجرا شده را در آن نگه می دارد. اگر یکی از این migration ها از قبل ایجاد شده بود دیگر آن را اجرا نمی کند. با این حساب migration مربوط به Post در پروژه ما دوباره اجرا نمی شود. در صورتی که با migration ها به مشکل برخورد کردید مطمئن شوید که خصوصیت target در فایل tsconfig.json شما روی ES6 تنظیم شده باشد. همچنین بسیار از خطا ها با پاک کردن پوشه dist و اجرای دوباره دستور npm run watch تصحیح می شود.
پس از اجرای این کدها تعداد جداول در پایگاه داده roxo_training به شکل زیر است:
List of relations Schema | Name | Type | Owner --------+-----------------------------+----------+------- public | mikro_orm_migrations | table | amir public | post | table | amir public | user | table | amir
فرآیند احراز هویت: ساخت resolver برای User
در مرحله بعدی باید یک resolver را برای جدول User تعریف کنیم بنابراین به پوشه resolvers رفته و فایل جدیدی به نام user.ts می سازیم. قبل از اینکه بخواهیم چیزی را در این resolver بنویسیم باید ابتدا پکیجی را برای هش کردن رمز عبور کاربران نصب کنیم. حتما می دانید که هیچ گاه نباید رمز عبور کاربران را به صورت یک متن ساده ذخیره کنید چرا که اگر پایگاه داده شما هک شود رمز کاربران شما فاش می شود.
برای هش کردن رمز عبور از پکیج argon2 استفاده می کنیم:
npm i argon2
پس از نصب این پکیج به فایل resolvers/user.ts برمی گردیم. ما در مراحل قبل از Arg@ برای دسترسی به آرگومان های GraphQL استفاده می کردیم اما روش دیگری نیز برای این کار وجود دارد. در GraphQL یک تایپ خاص به نام InputType وجود دارد و روش استفاده از آن بدین شکل است که ما یک کلاس را به عنوان آرگومان های دریافتی تعریف می کنیم:
@InputType()
class UsernamePasswordInput {
@Field()
username!: string;
@Field()
password!: string;
}
با صدا زدن InputType می توانیم کلاس خود را به یک تایپ Input برای GraphQL تبدیل کنیم. درون این کلاس فیلد های مورد نظرمان را مشخص کنیم. این فیلد ها همان آرگومان هایی هستند که باید از سمت کاربر پاس داده شوند. در مرحله بعدی از این کلاس برای تعریف resolver خودمان استفاده می کنیم:
import { MyContext } from "../types";
import { Arg, Ctx, Field, InputType, Mutation, Resolver } from "type-graphql";
import argon2 from "argon2";
import { User } from "../entities/User";
@InputType()
class UsernamePasswordInput {
@Field()
username!: string;
@Field()
password!: string;
}
@Resolver()
export class UserResolver {
@Mutation(() => User)
async register(
@Arg("userData") userData: UsernamePasswordInput,
@Ctx() { em }: MyContext
) {
const hashedPassword = await argon2.hash(userData.password);
const user = em.create(User, {
username: userData.username,
password: hashedPassword,
});
await em.persistAndFlush(user);
return user;
}
}
ما یک resolver را در این بخش تعریف کرده ایم. تنها متدی که فعلا داریم متد register است که مخصوص ثبت نام کاربران جدید است. ما در اینجا آرگومانی به نام userData تعریف کرده ایم (شما می توانید هر نامی را برایش انتخاب کنید) که تایپ آن از نوع input type ما (همان کلاس UsernamePasswordInput) است. درون این متد ابتدا با متد hash از پکیج argon2 رمز عبور کاربر را هش کرده ایم و سپس با create یک کاربر جدید را در پایگاه داده ساخته ایم. پس از ثبت این کاربر در پایگاه داده با متد persistAndFlush آن کاربر را برگردانده ایم.
تنها کاری که باقی مانده است پاس دادن این resolver به apollo-server است. برای این کار به فایل index.ts رفته و می گوییم:
const apolloServer = new ApolloServer({
schema: await buildSchema({
resolvers: [HelloResolver, PostResolver, UserResolver],
}),
context: () => ({ em: orm.em }),
});
حالا به مرورگر رفته و کوئری زیر را ارسال کنید:
mutation {
register(userData: { username: "amir", password: "amir" }) {
id
createdAt
updatedAt
username
}
}
همانطور که می بینید userData به صورت یک شیء پاس داده شده است چرا که یک Input Type است. با اجرای این کوئری نتیجه زیر را می گیرید:
{
"data": {
"register": {
"id": "1",
"createdAt": "1623570892041",
"updatedAt": "1623570892041",
"username": "amir"
}
}
}
همانطور که می بینید رمز عبور برایمان برگردانده نشده است. چرا؟ به دلیل اینکه Field@ را روی آن صدا نزدیم. به همین سادگی یک کاربر را ثبت نام کرده ایم.
حالا که متد ثبت نام را ایجاد کرده ایم بهتر است به سراغ متد لاگین برویم. برای انجام این کار باید موضوعی را در نظر داشته باشیم. اولا ما قصد پیاده سازی یک سیستم لاگین واقعی با توکن های JWT را نداریم بلکه فقط با کوکی ها کار می کنیم. هدف ما در ابتدا این است که رمز عبور کاربر را اعتبارسنجی کرده و سپس در صورت صحت آن، یک شیء کاربر را برایش برگردانیم. در نهایت به سراغ کوکی ها می رویم. مسئله بعدی این است که اگر رمز عبور کاربر اشتباه بود، چطور می توانیم یک خطا را برایش برگردانیم؟ ده ها راه مختلف برای حل این مشکل وجود دارد اما من دوست دارم دو کلاس جداگانه را برای این مسئله در همین فایل resolvers/user.ts ایجاد کنم:
// بقیه کدها
@ObjectType()
class FieldError {
@Field()
field!: string;
@Field()
message!: string;
}
@ObjectType()
class UserResponse {
@Field(() => [FieldError], { nullable: true })
errors?: FieldError[];
@Field(() => User, { nullable: true })
user?: User;
}
// بقیه کدها
در ابتدا یک کلاس FieldError را ایجاد کرده ام که یک object type است و دو خصوصیت field و message را دارد. خصوصیت field باید به کاربر بگوید که چه فیلدی دارای خطا بوده و خصوصیت message نیز پیام آن خطا می باشد که توضیحات بیشتری را در خود دارد. در مرحله بعدی یک کلاس دیگر به نام UserResponse را داریم که دو فیلد دارد: errors و user. همانطور که می بینید هر دو فیلد اختیاری هستند (با علامت ؟ برای تایپ اسکریپت و nullable برای GraphQL مشخص شده اند). چرا؟ به دلیل اینکه در هر زمان فقط یکی از این دو فیلد ارسال می شوند. اگر خطایی داشته باشیم فیلد error و در غیر این صورت فیلد user ارسال می شوند. آیا نمی توانستیم به جای این کار از Union ها در تایپ اسکریپت استفاده کنیم؟ این کار ممکن است ما روش بالا معمولا مشکلات کمتری را برایتان ایجاد می کند و استفاده از آن نیز ساده تر است.
حالا باید متد login را بنویسیم. از آنجایی که کدهای این فایل زیاد است من کل محتوای فایل user.ts خودم را برایتان قرار می دهم:
import { MyContext } from "../types";
import {
Arg,
Ctx,
Field,
InputType,
Mutation,
ObjectType,
Resolver,
} from "type-graphql";
import argon2 from "argon2";
import { User } from "../entities/User";
@InputType()
class UsernamePasswordInput {
@Field()
username!: string;
@Field()
password!: string;
}
@ObjectType()
class FieldError {
@Field()
field!: string;
@Field()
message!: string;
}
@ObjectType()
class UserResponse {
@Field(() => [FieldError], { nullable: true })
errors?: FieldError[];
@Field(() => User, { nullable: true })
user?: User;
}
@Resolver()
export class UserResolver {
@Mutation(() => User)
async register(
@Arg("userData") userData: UsernamePasswordInput,
@Ctx() { em }: MyContext
) {
const hashedPassword = await argon2.hash(userData.password);
const user = em.create(User, {
username: userData.username,
password: hashedPassword,
});
await em.persistAndFlush(user);
return user;
}
@Mutation(() => UserResponse)
async login(
@Arg("userData") userData: UsernamePasswordInput,
@Ctx() { em }: MyContext
): Promise<UserResponse> {
const user = await em.findOne(User, { username: userData.username });
if (!user) {
return {
errors: [
{
field: "username",
message: "username does not exists",
},
],
};
}
const valid = await argon2.verify(user.password, userData.password);
if (!valid) {
return {
errors: [
{
field: "password",
message: "Incorrect Password",
},
],
};
}
return { user };
}
}
برای آرگومان هایمان باز هم از UsernamePasswordInput استفاده کرده ایم چرا که باز هم باید رمز عبور و نام کاربری را دریافت کنیم. همچنین در نظر داشته باشید که متد login یک UserResponse را برمی گرداند. دلیل تعریف این کلاس همین مسئله بود که بتوانیم هم خطا و هم کاربر را در شرایط مختلف برگردانیم.
در مرحله بعدی سعی کرده ایم کاربری را با نام کاربری ارسال شده پیدا کنیم و نتیجه را در متغیر user ذخیره کرده ایم. در صورتی که این متغیر خالی بود یعنی اصلا چنین کاربری وجود ندارد بنابراین یک شیء خطا را برگردانده ایم. در صورتی که چنین کاربری وجود داشته باشد متد verify را صدا می زنیم که دو آرگومان می گیرد. آرگومان اول رمز هش شده (دریافت شده از پایگاه داده) و آرگومان دوم رمز دریافت شده از سمت کاربر است. در صورتی که نتیجه صحیح باشد فقط شیء user را برمی گردانیم و در غیر این صورت یک شیء خطا برگردانده خواهد شد. برای تست این کد باید دوباره به http://localhost:4000/graphql برگردید و یک کوئری جدید را ارسال کنیم:
mutation {
login(userData: { username: "amir", password: "amir" }) {
errors {
field
message
}
user {
id
username
}
}
}
من نام کاربری و رمز عبور خودم را پاس داده ام اما بعد از آن باید مشخص کنیم دقیقا چه فیلد هایی را می خواهیم. errors و user هر دو شیء هستند بنابراین باید دقیقا مشخص شود کدام فیلد ها مد نظر ما است. من برای errors فیلد های field و message و برای user فیلد های id و username را می خواهم. با اجرای این کوئری نتیجه زیر را دریافت می کنیم:
{
"data": {
"login": {
"errors": null,
"user": {
"id": "1",
"username": "amir"
}
}
}
}
همانطور که می بینید فیلد errors برابر با null است که یعنی هیچ خطایی نداریم. در بخش user نیز اطلاعات حساب کاربری خودم را دریافت کرده ام. حالا این بار یک کوئری اشتباه می زنیم، مثلا:
mutation {
login(userData: { username: "amir", password: "00000000" }) {
errors {
field
message
}
user {
id
username
}
}
}
رمز عبور من 00000000 نیست بنابراین با اجرای کوئری بالا خطای زیر را دریافت می کنیم:
{
"data": {
"login": {
"errors": [
{
"field": "password",
"message": "Incorrect Password"
}
],
"user": null
}
}
}
این بار user برابر null بوده و errors توضیحات مربوط به خطا را شامل می شود. ما می توانیم از همین مکانیسم در متد register نیز استفاده کنیم تا در صورت خالی بودن نام کاربری یک خطا را برگردانیم:
@Mutation(() => UserResponse)
async register(
@Arg("userData") userData: UsernamePasswordInput,
@Ctx() { em }: MyContext
): Promise<UserResponse> {
if (userData.username.length <= 2) {
return {
errors: [
{
field: "username",
message: "length should be greater than 2",
},
],
};
}
if (userData.password.length <= 3) {
return {
errors: [
{
field: "password",
message: "length should be greater than 3",
},
],
};
}
const hashedPassword = await argon2.hash(userData.password);
const user = em.create(User, {
username: userData.username,
password: hashedPassword,
});
try {
await em.persistAndFlush(user);
} catch (error) {
if ((error.code = "23505")) {
return {
errors: [
{
field: "username",
message: "username already taken.",
},
],
};
}
}
return { user };
}
انجام اعتبارسنجی نهایتا به خود شما و پیچیدگی سیستم شما دارد. من در ابتدا بررسی کرده ام که طول رمز عبور بیشتر از ۳ کاراکتر و طول نام کاربری بیشتر از ۲ کاراکتر باشد. این مسئله باعث می شود که کاربران نتوانند یک فیلد خالی را برای ما ارسال کنند. هر دوی این اعتبارسنجی ها با یک شرط ساده if انجام می شوند. در مرحله بعدی باید بررسی کنیم که نام کاربری ثبت شده تکراری نباشد. اگر یادتان باشد ما برای ستون نام کاربری از constraint ای به نام Unique استفاده کرده بودیم که یعنی این ستون فقط می تواند مقادیر یکتا داشته باشد. شما می توانید این کدها را در entities/user.ts مشاهده کنید:
@ObjectType()
@Entity()
export class User {
@Field(() => ID)
@PrimaryKey()
id!: number;
@Field(() => String)
@Property()
createdAt: Date = new Date();
@Field(() => String)
@Property({ onUpdate: () => new Date() })
updatedAt: Date = new Date();
@Field()
@Property({ unique: true })
username!: string;
@Property({ type: "text" })
password!: string;
}
در صورتی که نام کاربری تکراری باشد یک خطا با کد 23505 برایمان برگردانده شده و یک exception پرتاب می شود که اسکریپت ما را متوقف می کند. ما دو راه حل برای این مشکل داریم: راه حل اول این است که ابتدا وجود چنین نام کاربری را بررسی کنیم و در صورتی که چنین نامی وجود داشت یک خطا را به کاربر بدهیم. راه حل دوم این است که persistAndFlush را در یک بلوک try & catch قرار بدهیم. در این حالت باید بررسی کنیم که کد خطا 23505 باشد. چرا؟ به دلیل اینکه ممکن است عملیات ثبت در پایگاه داده به دلیل دیگری به غیر از تکراری بودن نام کاربری با خطا روبرو شود (مثلا پایگاه داده مشکلی پیدا کرده باشد) با این حساب می گوییم اگر کد خطا 23505 بود یک شیء خطا را به کاربر برمی گردانیم که می گوید نام کاربری قبلا ثبت شده است.
نصب پکیج های express-session و connect-redis
همانطور که توضیح دادم برای احراز هویت و لاگین کاربران از کوکی ها و session ها استفاده خواهیم کرد. پکیج express-session به ما اجازه این کار را می دهد. این پکیج روش های مختلفی برای ذخیره داده های مربوط به لاگین کاربر را انجام می دهد. من می خواهم این کوکی ها را در پایگاه داده redis ذخیره کنم. چرا؟ به دلیل اینکه باید این داده ها را برای هر درخواست بررسی کنیم بنابراین باید پایگاه داده بسیاری سریعی داشته باشیم. redis داده های را در مموری (RAM) سیستم ذخیره می کند بنابراین سرعت بسیار بالایی دارد. من انتظار دارم شما redis را روی سیستم خود نصب داشته باشید. برای اتصال به redis نیز نیاز به پکیج connect-redis خواهیم داشت. تمام این پکیج ها با دستور زیر نصب می شوند:
npm install redis connect-redis express-session
سپس تایپ های این پکیج ها را نصب می کنیم:
npm install -D @types/redis @types/express-session @types/connect-redis
با اجرای این دستورات پکیج های مورد نظر ما نصب می شوند. در مرحله بعدی باید به فایل index.ts رفته و از این پکیج ها استفاده کنیم. اگر به صفحه رسمی connect-redis بروید چنین مثالی را از نحوه استفاده پیدا خواهید کرد:
const redis = require('redis')
const session = require('express-session')
let RedisStore = require('connect-redis')(session)
let redisClient = redis.createClient()
app.use(
session({
store: new RedisStore({ client: redisClient }),
saveUninitialized: false,
secret: 'keyboard cat',
resave: false,
})
)
این تنظیمات یک نمونه ساده از تنظیمات مربوط به این پلاگین است اما پروژه ما به شکلی است که باید آن را به شکل متفاوتی پیکربندی کنیم. همچنین ما از تایپ اسکریپت استفاده می کنیم اما مثال بالا با جاوا اسکریپت است (مثلا دستورات require باید به import تبدیل شوند). من به عنوان تمرین از شما می خواهم توضیحات connect-redis را مطالعه کنید و بر اساس آن session و کوکی را برای پروژه ما ایجاد کنید. در جلسه بعدی برایتان توضیح خواهم داد که چطور می توانیم این کار را انجام بدهیم. کلید یادگیری این است که خودتان این کار ها را انجام بدهید بنابراین قبل از رفتن به قسمت بعد بهتر است خودتان سعی در حل این مشکل کنید.









در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.